
One of the primary challenges in AI research is verifying the correctness of language models (LMs) outputs, especially in contexts requiring complex reasoning. As LMs are increasingly used for intricate queries that demand multiple reasoning steps, domain expertise, and quantitative analysis, ensuring the accuracy and reliability of these models is crucial. This task is particularly important in fields like finance, law, and biomedicine, where incorrect information can lead to significant adverse outcomes.
Current methods for verifying LM outputs include fact-checking and natural language inference (NLI) techniques. These methods typically rely on datasets designed for specific reasoning tasks, such as question answering (QA) or financial analysis. However, these datasets are not tailored for claim verification, and existing methods exhibit limitations like high computational complexity, dependence on large volumes of labeled data, and inadequate performance on tasks requiring long-context reasoning or multi-hop inferences. High label noise and the domain-specific nature of many datasets further hinder the generalizability and applicability of these methods in broader contexts.
A team of researchers from Google and Tel Aviv University proposed CoverBench, a benchmark specifically designed for evaluating complex claim verification across diverse domains and reasoning types. CoverBench addresses the limitations of existing methods by providing a unified format and a diverse set of 733 examples requiring complex reasoning, including long-context understanding, multi-step reasoning, and quantitative analysis. The benchmark includes true and false claims vetted for quality, ensuring low levels of label noise. This novel approach allows for a comprehensive evaluation of LM verification capabilities, highlighting areas needing improvement and setting a higher standard for claim verification tasks.

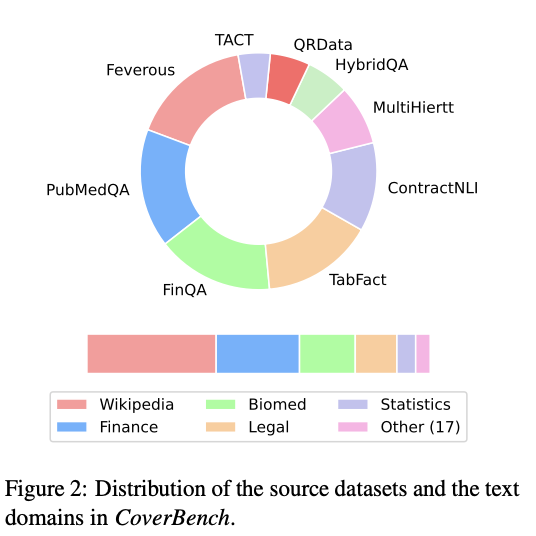
CoverBench comprises datasets from nine different sources, including FinQA, QRData, TabFact, MultiHiertt, HybridQA, ContractNLI, PubMedQA, TACT, and Feverous. These datasets cover a range of domains such as finance, Wikipedia, biomedical, legal, and statistics. The benchmark involves converting various QA tasks into declarative claims, standardizing table representations, and generating negative examples using seed models like GPT-4. The final dataset contains long input contexts, averaging 3,500 tokens, which challenge current models’ capabilities. The datasets were manually vetted to ensure the correctness and difficulty of the claims.

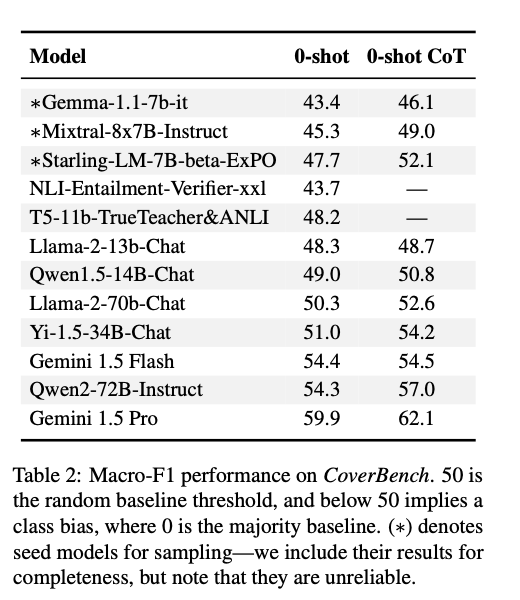
The evaluation of CoverBench demonstrates that current competitive LMs struggle significantly with the tasks presented, achieving performance near the random baseline in many instances. The highest-performing models, such as Gemini 1.5 Pro, achieved a Macro-F1 score of 62.1, indicating substantial room for improvement. In contrast, models like Gemma-1.1-7b-it performed much lower, underscoring the benchmark’s difficulty. These results highlight the challenges LMs face in complex claim verification and the significant headroom for advancements in this area.

In conclusion, CoverBench significantly contributes to AI research by providing a challenging benchmark for complex claim verification. It overcomes the limitations of existing datasets by offering a diverse set of tasks that require multi-step reasoning, long-context understanding, and quantitative analysis. The benchmark’s thorough evaluation reveals that current LMs have substantial room for improvement in these areas. CoverBench thus sets a new standard for claim verification, pushing the boundaries of what LMs can achieve in complex reasoning tasks.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 48k+ ML SubReddit
Find Upcoming AI Webinars here


Aswin AK is a consulting intern at MarkTechPost. He is pursuing his Dual Degree at the Indian Institute of Technology, Kharagpur. He is passionate about data science and machine learning, bringing a strong academic background and hands-on experience in solving real-life cross-domain challenges.

