

Artificial intelligence (AI) focuses on creating systems capable of performing tasks requiring human intelligence. Within this field, the development of large language models (LLMs) aims to understand and generate human language, with applications in translation, summarization, and question-answering. Despite these advancements, complex multi-step reasoning tasks, such as solving mathematical problems, still need to be solved for even the most advanced LLMs. Enhancing the reasoning capabilities of these models is crucial for improving their performance on such tasks.
A significant problem in AI is improving the reasoning abilities of LLMs, especially for tasks requiring multiple logical steps. Current models often make intermediate-step errors, leading to incorrect final answers. Addressing these errors in the intermediate stages is essential for better performance in complex reasoning tasks. The focus is on creating methods that can more accurately guide LLMs through each step of the reasoning process.
Existing research includes various frameworks and models to improve LLM reasoning capabilities. Chain-of-Thought (CoT) prompting guides LLMs to break down tasks into intermediate steps, enhancing performance. Outcome Reward Models (ORMs) and Process Reward Models (PRMs) provide feedback, with PRMs offering more detailed supervision at each step. Current methods like Math-Shepherd and MiPS use Monte Carlo estimation to automate data collection, while self-consistency decoding and fine-tuning with high-quality datasets have also improved LLM reasoning.

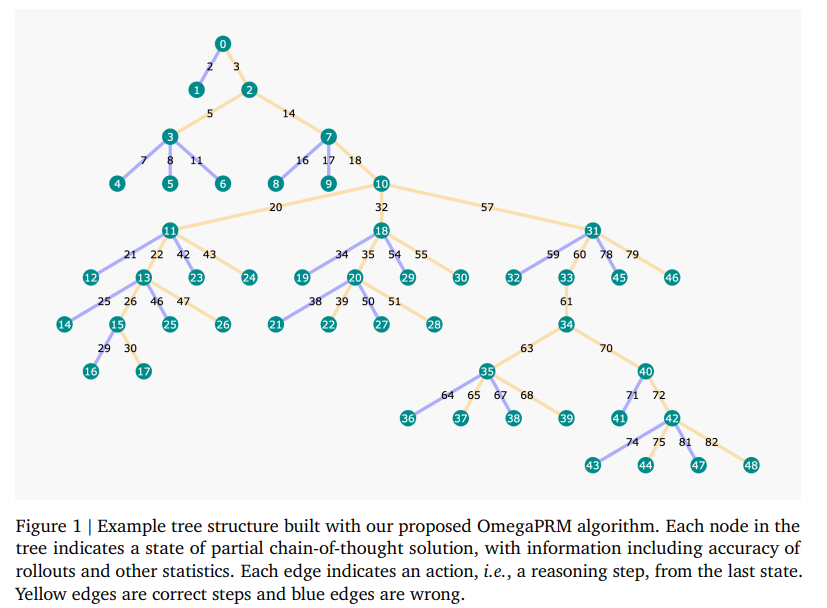
Researchers at Google DeepMind and Google introduced OmegaPRM, a novel method for automated process supervision data collection. This method employs a divide-and-conquer Monte Carlo Tree Search (MCTS) algorithm to efficiently identify the first error in a reasoning chain. OmegaPRM uses binary search to balance the collection of positive and negative examples, ensuring high quality and efficiency. This automated approach distinguishes itself by eliminating the need for costly human intervention, thus making it a scalable solution for enhancing LLM performance.
The OmegaPRM methodology involves creating a state-action tree to represent detailed reasoning paths for questions. Nodes contain the question and preceding reasoning steps, while edges indicate subsequent steps. The algorithm uses temperature sampling to generate multiple completions, treated as an approximate action space. The researchers collected over 1.5 million process supervision annotations from the MATH dataset. The Gemini Pro model, trained with this data, utilized the weighted self-consistency algorithm to achieve improved performance, demonstrating the effectiveness of OmegaPRM in training PRMs.

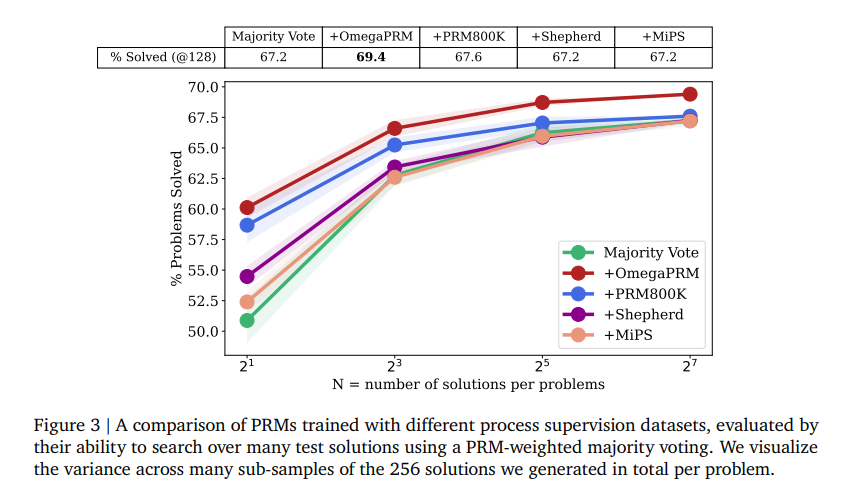
The OmegaPRM algorithm enhances the instruction-tuned Gemini Pro model’s mathematical reasoning performance. Utilizing the weighted self-consistency algorithm alongside automated process supervision, the model achieved a 69.4% success rate on the MATH benchmark. This success rate represents a 36% relative improvement from the base model’s 51% performance. The researchers’ automated approach ensures that data collection costs are significantly reduced compared to human annotation and brute-force Monte Carlo sampling methods. These improvements underscore the potential of OmegaPRM in advancing LLM capabilities in complex multi-step reasoning tasks.
In conclusion, the research team at Google DeepMind and Google successfully tackled the challenge of improving LLM mathematical reasoning through automated process supervision. The OmegaPRM method enhances performance and reduces reliance on costly human annotation, making it a significant advancement in AI reasoning tasks. The methodology’s efficiency and the model’s improved performance underscore OmegaPRM’s potential to revolutionize complex multi-step reasoning in AI.
language processing tasks.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 44k+ ML SubReddit


Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.