Meta-learning, a burgeoning field in AI research, has made significant strides in training neural networks to adapt swiftly to new tasks with minimal data. This technique centers on exposing neural networks to diverse tasks, thereby cultivating versatile representations crucial for general problem-solving. Such varied exposure aims to develop universal capabilities in AI systems, an essential step toward the grand vision of artificial general intelligence (AGI).
The primary challenge in meta-learning lies in creating task distributions that are broad enough to expose models to a wide array of structures and patterns. Achieving this breadth of exposure is fundamental to nurturing universal representations in AI models, which is essential for tackling diverse problems. This endeavor is at the heart of evolving more adaptable and generalized AI systems.
In universal prediction, current strategies often incorporate foundational principles like Occam’s Razor, which favors simpler hypotheses, and Bayesian Updating, which refines beliefs with new data. However, these traditional approaches encounter practical limitations, chiefly the computational resources they require. As a response, approximations of Solomonoff Induction have been developed. Solomonoff Induction is a theoretical framework that aims to construct ideal universal prediction systems, but its practical application is hampered by its computational demands.
Google DeepMind’s recent research breaks new ground by integrating Solomonoff Induction with neural networks through meta-learning. The researchers employed Universal Turing Machines (UTMs) for data generation, effectively exposing neural networks to a comprehensive spectrum of computable patterns. This exposure is pivotal in steering the networks toward mastering universal inductive strategies.
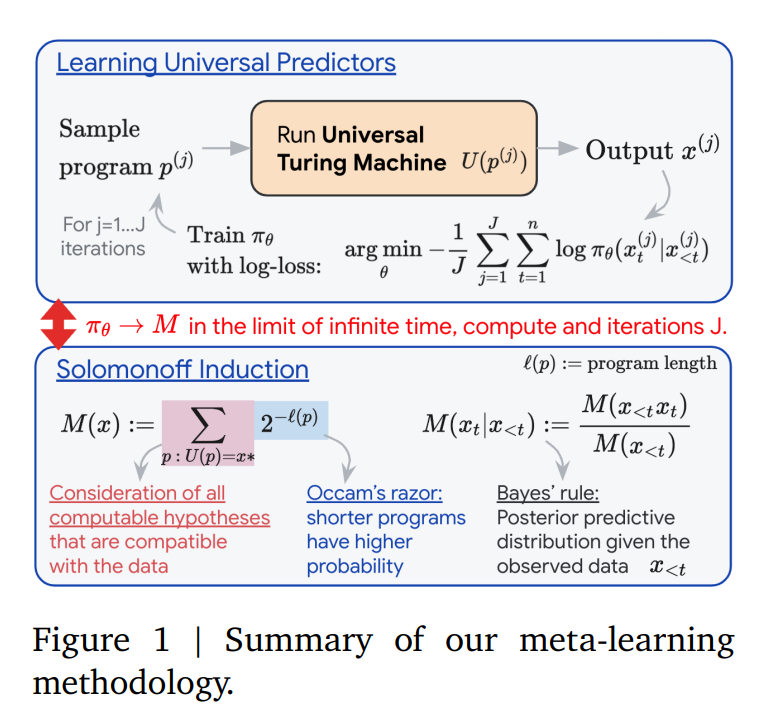
The methodology adopted by DeepMind employs established neural architectures like Transformers and LSTMs alongside innovative algorithmic data generators. The focus extends beyond just selecting architectures; it encompasses formulating an appropriate training protocol. This comprehensive approach involves thorough theoretical analysis and extensive experimentation to assess the efficacy of the training processes and the neural networks’ resultant capabilities.
DeepMind’s experiments reveal that enlarging the model’s size correlates with enhanced performance. This suggests that scaling up models is instrumental in facilitating the learning of more universal prediction strategies. Notably, large Transformers trained with UTM data exhibited the ability to transfer their knowledge effectively to a range of other tasks. This indicates that these models have developed a capacity to internalize and reuse universal patterns.
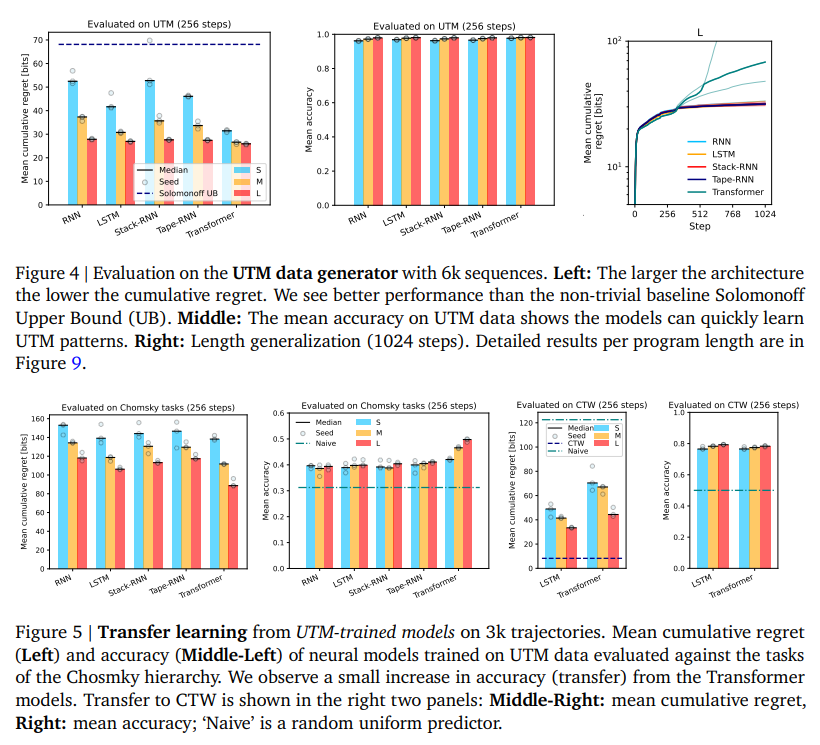
Both large LSTMs and Transformers demonstrated optimal performance in scenarios involving variable-order Markov sources. This is a significant finding, as it highlights these models’ ability to model Bayesian mixtures effectively over programs, which is essential for Solomonoff Induction. This result is notable because it demonstrates the models’ capacity to fit data and comprehend and replicate the underlying generative processes.
In conclusion, Google DeepMind’s study signifies a major leap forward in AI and machine learning. It illuminates the promising potential of meta-learning in equipping neural networks with the skills necessary for universal prediction strategies. The research’s focus on using UTMs for data generation and the balanced emphasis on theoretical and practical aspects of training protocols mark a pivotal advancement in developing more versatile and generalized AI systems. The study’s findings open new avenues for future research in crafting AI systems with enhanced learning and problem-solving abilities.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.
 [FREE AI WEBINAR] ‘Using ANN for Vector Search at Speed & Scale (Demo on AWS)’ (Feb 5, 2024)
[FREE AI WEBINAR] ‘Using ANN for Vector Search at Speed & Scale (Demo on AWS)’ (Feb 5, 2024) 