
Vision-language models have evolved significantly over the past few years, with two distinct generations emerging. The first generation, exemplified by CLIP and ALIGN, expanded on large-scale classification pretraining by utilizing web-scale data without requiring extensive human labeling. These models used caption embeddings obtained from language encoders to broaden the vocabulary for classification and retrieval tasks. The second generation, akin to T5 in language modeling, unified captioning and question-answering tasks through generative encoder-decoder modeling. Models like Flamingo, BLIP-2, and PaLI further scaled up these approaches. Recent developments have introduced an additional “instruction tuning” step to enhance user-friendliness. Alongside these advancements, systematic studies have aimed to identify the critical factors in vision-language models.
Building on this progress, DeepMind researchers present PaliGemma, an open vision-language model combining the strengths of the PaLI vision-language model series with the Gemma family of language models. This innovative approach builds upon the success of previous PaLI iterations, which demonstrated impressive scaling capabilities and performance improvements. PaliGemma integrates a 400M SigLIP vision model with a 2B Gemma language model, resulting in a sub-3B vision-language model that rivals the performance of much larger predecessors like PaLI-X, PaLM-E, and PaLI-3. The Gemma component, derived from the same technology powering the Gemini models, contributes its auto-regressive decoder-only architecture to enhance PaliGemma’s capabilities—this fusion of advanced vision and language processing techniques positions PaliGemma as a significant advancement in multimodal AI.

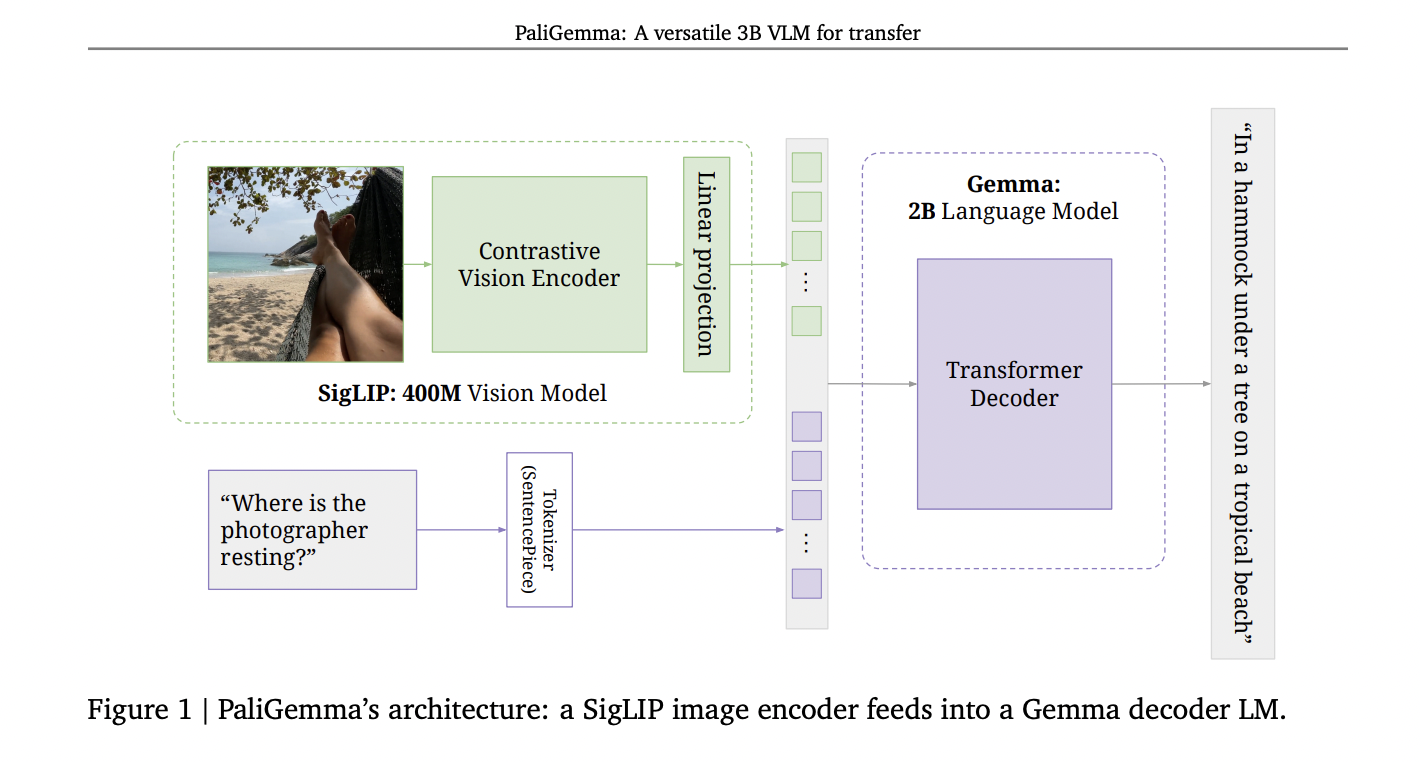
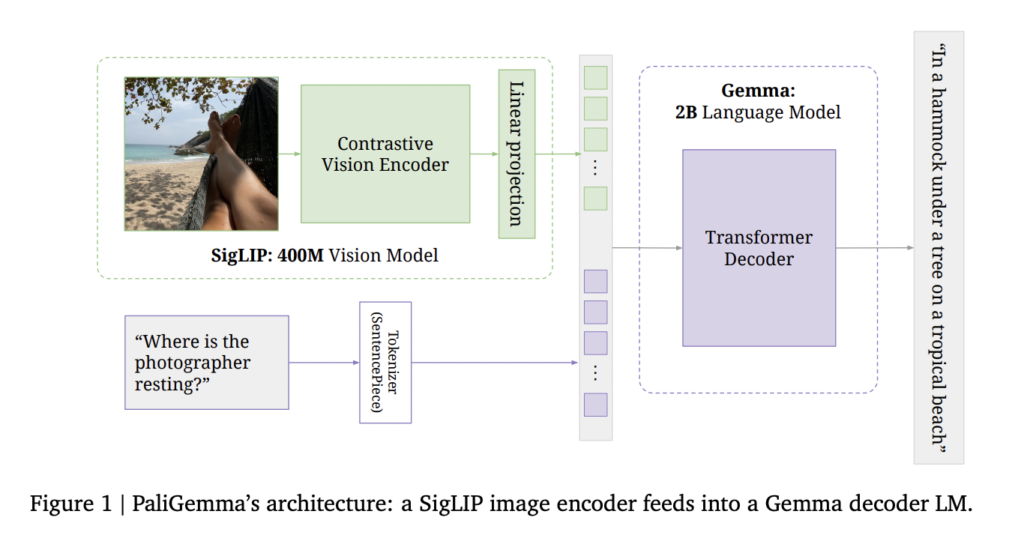
PaliGemma’s architecture comprises three key components: a SigLIP ViTSo400m image encoder, a Gemma-2B v1.0 decoder-only language model, and a linear projection layer. The image encoder transforms input images into a sequence of tokens, while the language model processes text using its SentencePiece tokenizer. The linear projection layer aligns the dimensions of image and text tokens, allowing them to be concatenated. This simple yet effective design enables PaliGemma to handle various tasks, including image classification, captioning, and visual question-answering, through a flexible image+text in, text out API.
The model’s input sequence structure is carefully designed for optimal performance. Image tokens are placed at the beginning, followed by a BOS token, prefix tokens (task description), a SEP token, suffix tokens (prediction), an EOS token, and PAD tokens. This arrangement allows for full attention across the entire input, enabling image tokens to consider the task context when updating their representations. The suffix, which forms the output, is covered by an auto-regressive mask to maintain the generation process’s integrity.
PaliGemma’s training process involves multiple stages to ensure comprehensive visual-language understanding. It begins with unimodal pretraining of individual components, followed by multimodal pretraining on a diverse mixture of tasks. Notably, the image encoder is not frozen during this stage, allowing for improved spatial and relational understanding. The training continues with a resolution increase stage, enhancing the model’s ability to handle high-resolution images and complex tasks. Finally, a transfer stage adapts the base model to specific tasks or use cases, demonstrating PaliGemma’s versatility and effectiveness across various applications.
The results demonstrate PaliGemma’s impressive performance across a wide range of visual-language tasks. The model excels in image captioning, achieving high scores on benchmarks like COCO-Captions and TextCaps. In visual question answering, PaliGemma shows strong performance on various datasets, including VQAv2, GQA, and ScienceQA. The model also performs well on more specialized tasks such as chart understanding (ChartQA) and OCR-related tasks (TextVQA, DocVQA). Notably, PaliGemma exhibits significant improvements when increasing image resolution from 224px to 448px and 896px, especially for tasks involving fine-grained details or text recognition. The model’s versatility is further demonstrated by its ability to handle video input tasks and image segmentation challenges.


Researchers also present the noteworthy findings from the PaliGemma research:
- Simple square resizing (224×224) performs as well as complex aspect-ratio preserving techniques for segmentation tasks.
- Researchers introduced CountBenchQA, a new dataset addressing limitations in TallyQA for assessing VLMs’ counting abilities.
- Discrepancies were found in previously published WidgetCaps numbers, invalidating some comparisons.
- Image annotations (e.g., red boxes) are as effective as text prompts for indicating widgets to be captioned.
- RoPE interpolation for image tokens during resolution upscaling (Stage 2) showed no significant benefits.
- PaliGemma demonstrates unexpected zero-shot generalization to 3D renders from Objaverse without specific training.
- The model achieves state-of-the-art performance on MMVP, significantly outperforming larger models like GPT4-V and Gemini.
This research introduces PaliGemma, a robust, compact open-base VLM that excels in transfer learning across diverse tasks. This research demonstrates that smaller VLMs can achieve state-of-the-art performance on a wide spectrum of benchmarks, challenging the notion that larger models are always superior. By releasing the base model without instruction tuning, the researchers aim to provide a valuable foundation for further studies in instruction tuning and specific applications. This approach encourages a clearer distinction between base models and fine-tuned versions in VLM research, potentially opening new avenues for more efficient and versatile AI systems in the field of visual-language understanding.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit


Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.