The natural language processing (NLP) field rapidly evolves, with small language models gaining prominence. These models, designed for efficient inference on consumer hardware and edge devices, are increasingly important. They allow for full offline applications and have shown significant utility when fine-tuned for tasks such as sequence classification, question answering, or token classification, often outperforming larger models in these specialized areas.
One of the primary challenges in NLP is developing language models that balance power and resource efficiency. Traditional large-scale models like BERT and GPT-3 demand substantial computational power and memory, limiting their deployment on consumer-grade hardware and edge devices. This creates a pressing need for smaller, more efficient models that maintain high performance while reducing resource requirements. Addressing this need involves developing models that are not only powerful but also accessible and practical for use on devices with limited computational power.
Currently, methods in the field include large-scale language models, such as BERT and GPT-3, which have set benchmarks in numerous NLP tasks. These models, while powerful, require extensive computational resources for training and deployment. Fine-tuning these models for specific tasks involves significant memory and processing power, making them impractical for use on devices with limited resources. This limitation has prompted researchers to explore alternative approaches that balance efficiency with performance.
Researchers at H2O.ai have introduced the H2O-Danube3 series to address these challenges. This series includes two main models: H2O-Danube3-4B and H2O-Danube3-500M. The H2O-Danube3-4B model is trained on 6 trillion tokens, while the H2O-Danube3-500M model is trained on 4 trillion tokens. Both models are pre-trained on extensive datasets and fine-tuned for various applications. These models aim to democratize language models’ use by making them accessible and efficient enough to run on modern smartphones, enabling a wider audience to leverage advanced NLP capabilities.
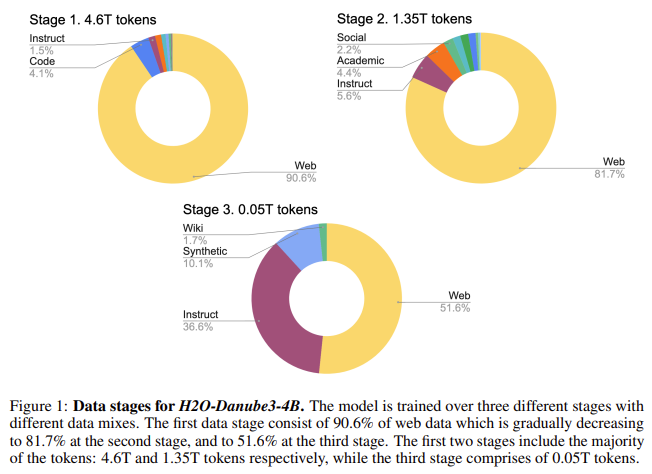
The H2O-Danube3 models utilize a decoder-only architecture inspired by the Llama model. The training process involves three stages with varying data mixes to improve the quality of the models. In the first stage, the models are trained on 90.6% web data, which is gradually reduced to 81.7% in the second stage and 51.6% in the third stage. This approach helps refine the model by increasing the proportion of higher-quality data, including instruct data, Wikipedia, academic texts, and synthetic texts. The models are optimized for parameter and compute efficiency, allowing them to perform well even on devices with limited computational power. The H2O-Danube3-4B model has approximately 3.96 billion parameters, while the H2O-Danube3-500M model includes 500 million parameters.
The performance of the H2O-Danube3 models is notable across various benchmarks. The H2O-Danube3-4B model excels in knowledge-based tasks and achieves a strong accuracy of 50.14% on the GSM8K benchmark, focusing on mathematical reasoning. Additionally, the model scores over 80% on the 10-shot hellaswag benchmark, which is close to the performance of much larger models. The smaller H2O-Danube3-500M model also performs well, scoring highest in eight out of twelve academic benchmarks compared to similar-sized models. This demonstrates the models’ versatility and efficiency, making them suitable for various applications, including chatbots, research, and on-device applications.

In conclusion, the H2O-Danube3 series addresses the critical need for efficient and powerful language models operating on consumer-grade hardware. The H2O-Danube3-4B and H2O-Danube3-500M models offer a robust solution by providing models that are both resource-efficient and highly performant. These models demonstrate competitive performance across various benchmarks, showcasing their potential for widespread use in applications such as chatbot development, research, fine-tuning for specific tasks, and on-device offline applications. H2O.ai’s innovative approach to developing these models highlights the importance of balancing efficiency with performance in NLP.
Check out the Paper, Model Card, and Details. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.
