Constructing Knowledge Graphs (KGs) from unstructured data is a complex task due to the difficulties of extracting and structuring meaningful information from raw text. Unstructured data often contains unresolved or duplicated entities and inconsistent relationships, which complicates its transformation into a coherent knowledge graph. Additionally, the vast amount of unstructured data available across various fields further emphasizes the need for scalable methods to automatically process, extract, and structure this data into KGs. Successfully addressing these challenges is crucial for enabling efficient reasoning, inference, and data-driven decision-making in fields ranging from scientific research to web data analysis.
Traditional methods for building KGs from unstructured text primarily rely on techniques such as named entity recognition, relation extraction, and entity resolution. These approaches are frequently constrained by the need for predefined entity types and relationships, often depending on domain-specific ontologies. Additionally, they typically involve supervised learning, which requires large amounts of annotated data. A significant limitation of these methods is their tendency to generate inconsistent graphs with duplicated or unresolved entities, resulting in redundancies and ambiguities that necessitate extensive post-processing. Furthermore, many existing solutions are topic-dependent, limiting their applicability across different domains, which restricts their scalability and adaptability to new use cases.
Researchers from INSA Lyon, CNRS, and Universite Claude Bernard Lyon 1 introduce iText2KG, a zero-shot, topic-independent method for incrementally constructing Knowledge Graphs (KGs) from unstructured data without the need for predefined ontologies or post-processing. This framework consists of four distinct modules:
- Document Distiller: Reforms raw documents into semantic blocks using large language models (LLMs) guided by a flexible, user-defined schema.
- Incremental Entity Extractor: Extracts unique entities from the semantic blocks, ensuring no duplications or semantic ambiguities.
- Incremental Relation Extractor: Identifies and extracts semantically unique relationships between entities.
- Graph Integrator: Visualizes the entities and relationships in a KG using Neo4j, allowing for structured representation of data.
This modular design separates entity and relation extraction tasks, leading to improved precision and consistency. Moreover, the use of a zero-shot learning paradigm ensures adaptability across various domains without the need for fine-tuning or retraining, making it a flexible, accurate, and scalable solution for KG construction.
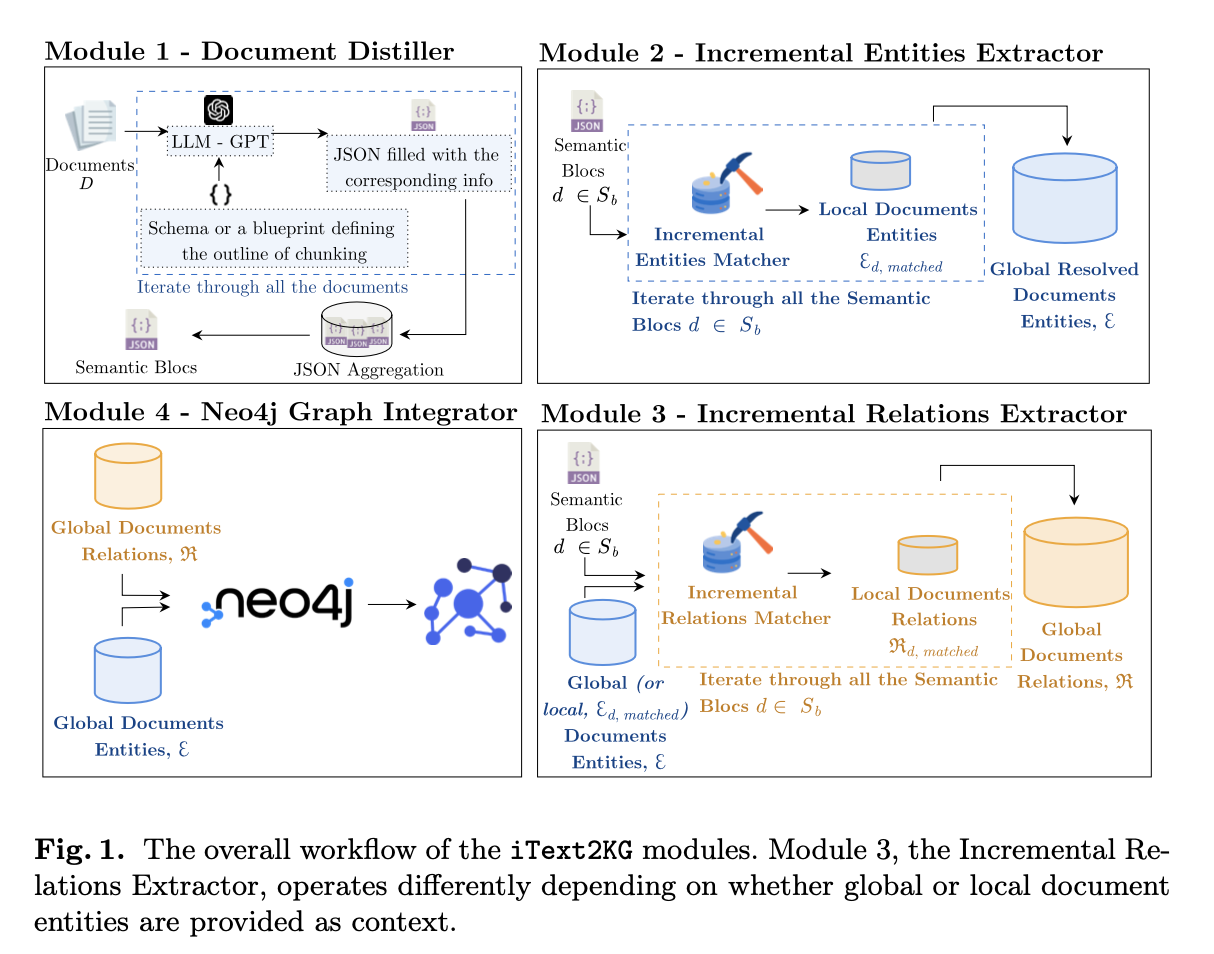
iText2KG processes documents incrementally by passing them through its four core modules. First, the Document Distiller module restructures raw text into semantic blocks based on a flexible, user-defined schema, which can be adapted to different types of documents such as scientific papers, CVs, or websites. These semantic blocks are then fed into the Incremental Entity Extractor, which identifies and ensures that each entity is unique by resolving potential ambiguities using similarity measures like cosine similarity.
The Incremental Relation Extractor then extracts relationships between the identified entities, leveraging both local and global document contexts to ensure the accuracy of the relationships. Finally, the Graph Integrator consolidates these entities and relationships into a visual knowledge graph using Neo4j, providing a coherent and structured representation of the data. The system’s performance was tested on a variety of document types, demonstrating its versatility across different use cases without the need for retraining.
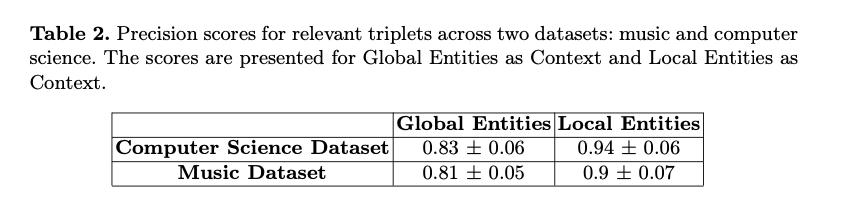
iText2KG exhibited superior performance compared to baseline methods, particularly in schema consistency, triplet extraction precision, and entity/relation resolution. The system achieved high consistency in structuring information from various types of documents, such as scientific articles, websites, and CVs. Precision in extracting relevant relationships was notably high when using local entities, ensuring minimal errors in the knowledge graph. Additionally, the approach demonstrated a low false discovery rate in entity and relation resolution, particularly with structured documents like scientific papers. Overall, iText2KG proved to be effective in constructing accurate and consistent knowledge graphs across multiple domains, adapting to different data types without the need for extensive fine-tuning or post-processing.

In conclusion, iText2KG offers a significant advancement in KG construction by providing a flexible, zero-shot approach capable of structuring unstructured data into consistent, topic-independent knowledge graphs. By modularizing the tasks of entity and relation extraction and adopting an incremental process, the method overcomes key limitations of traditional approaches, such as reliance on predefined ontologies and extensive post-processing. With strong performance across a variety of document types, iText2KG shows immense potential for broad application in fields requiring structured knowledge from unstructured text, offering a reliable, scalable, and efficient solution for KG construction.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
Aswin AK is a consulting intern at MarkTechPost. He is pursuing his Dual Degree at the Indian Institute of Technology, Kharagpur. He is passionate about data science and machine learning, bringing a strong academic background and hands-on experience in solving real-life cross-domain challenges.
