
Large language models (LLMs) are AI systems trained on vast amounts of text data, enabling them to understand, generate, and reason with natural language in highly capable and flexible ways. LLM training has seen remarkable advances in recent years, with organizations pushing the boundaries of what’s possible in terms of model size, performance, and efficiency. In this post, we explore how FP8 optimization can significantly speed up large model training on Amazon SageMaker P5 instances.
LLM training using SageMaker P5
In 2023, SageMaker announced P5 instances, which support up to eight of the latest NVIDIA H100 Tensor Core GPUs. Equipped with high-bandwidth networking technologies like EFA, P5 instances provide a powerful platform for distributed training, enabling large models to be trained in parallel across multiple nodes. With the use of Amazon SageMaker Model Training, organizations have been able to achieve higher training speeds and efficiency by turning to P5 instances. This showcases the transformative potential of training different scales of models faster and more efficiently using SageMaker Training.
LLM training using FP8
P5 instances, which are NVIDIA H100 GPUs underneath, also come with capabilities of training models using FP8 precision. The FP8 data type has emerged as a game changer in LLM training. By reducing the precision of the model’s weights and activations, FP8 allows for more efficient memory usage and faster computation, without significantly impacting model quality. The throughput for running matrix operations like multipliers and convolutions on 32-bit float tensors is much lower than using 8-bit float tensors. FP8 precision reduces the data footprint and computational requirements, making it ideal for large-scale models where memory and speed are critical. This enables researchers to train larger models with the same hardware resources, or to train models faster while maintaining comparable performance. To make the models compatible for FP8, NVIDIA released the Transformer Engine (TE) library, which provides support for some layers like Linear, LayerNorm, and DotProductAttention. To enable FP8 training, models need to use the TE API to incorporate these layers when casted to FP8. For example, the following Python code shows how FP8-compatible layers can be integrated:
try:
import transformer_engine.pytorch as te
using_te = True
except ImportError as ie:
using_te = False
......
linear_type: nn.Module = te.Linear if using_te else nn.Linear
......
in_proj = linear_type(dim, 3 * n_heads * head_dim, bias=False, device="cuda" if using_te)
out_proj = linear_type(n_heads * head_dim, dim, bias=False, device="cuda" if using_te)
......Results
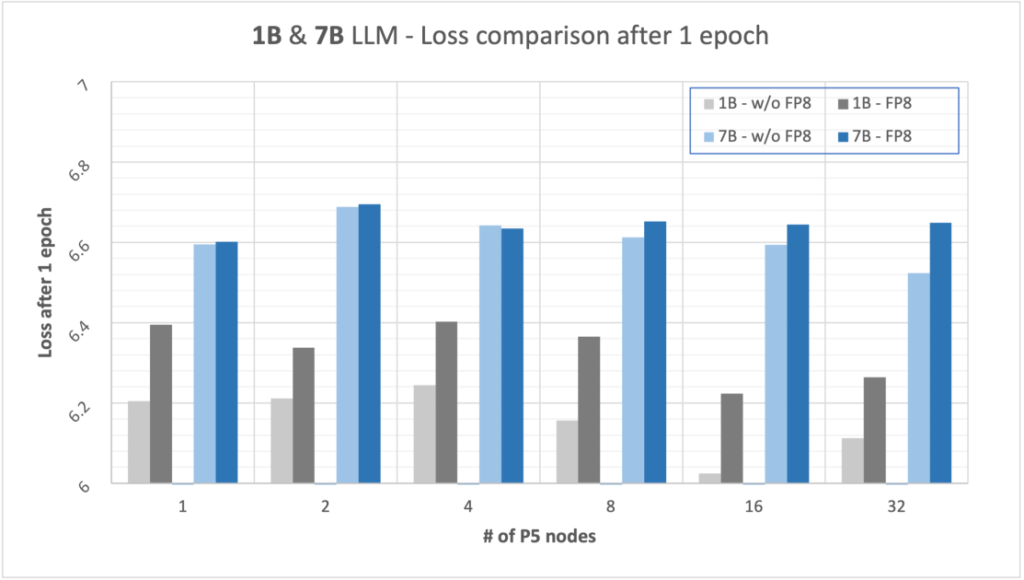
We ran some tests using 1B-parameter and 7B-parameter LLMs by running training with and without FP8. The test is run on 24 billion tokens for one epoch, thereby providing a comparison for throughput (in tokens per second per GPU) and model performance (in loss numbers). For 1B-parameter models, we computed results to compare performance with FP8 using a different number of instances for distributed training. The following table summarizes our results:
| Number of P5 Nodes | Without FP8 | With FP8 | % Faster by Using FP8 | % Loss Higher with FP8 than Without FP8 | ||||
| Tokens/sec/GPU | % Decrease | Loss After 1 Epoch | Tokens/sec/GPU | % Decrease | Loss After 1 Epoch | |||
| 1 | 40200 | – | 6.205 | 40800 | – | 6.395 | 1.49 | 3.06 |
| 2 | 38500 | 4.2288 | 6.211 | 41600 | -3.4825 | 6.338 | 8.05 | 2.04 |
| 4 | 39500 | 1.7412 | 6.244 | 42000 | -4.4776 | 6.402 | 6.32 | 2.53 |
| 8 | 38200 | 4.9751 | 6.156 | 41800 | -3.98 | 6.365 | 9.42 | 3.39 |
| 16 | 35500 | 11.6915 | 6.024 | 39500 | 1.7412 | 6.223 | 11.26 | 3.3 |
| 32 | 33500 | 16.6667 | 6.112 | 38000 | 5.4726 | 6.264 | 13.43 | 2.48 |
The following graph that shows the throughput performance of 1B-parameter model in terms of tokens/second/gpu over different numbers of P5 instances:
For 7B-parameter models, we computed results to compare performance with FP8 using different number of instances for distributed training. The following table summarizes our results:

| Number of P5 Nodes | Without FP8 | With FP8 | % Faster by Using FP8 | % Loss Higher with FP8 than Without FP8 | ||||
| Tokens/sec/GPU | % Decrease | Loss After 1 Epoch | Tokens/sec/GPU | % Decrease | Loss After 1 Epoch | |||
| 1 | 9350 | – | 6.595 | 11000 | – | 6.602 | 15 | 0.11 |
| 2 | 9400 | -0.5347 | 6.688 | 10750 | 2.2935 | 6.695 | 12.56 | 0.1 |
| 4 | 9300 | 0.5347 | 6.642 | 10600 | 3.6697 | 6.634 | 12.26 | -0.12 |
| 8 | 9250 | 1.0695 | 6.612 | 10400 | 4.9541 | 6.652 | 11.06 | 0.6 |
| 16 | 8700 | 6.9518 | 6.594 | 10100 | 8.7155 | 6.644 | 13.86 | 0.76 |
| 32 | 7900 | 15.508 | 6.523 | 9700 | 11.8182 | 6.649 | 18.56 | 1.93 |
The following graph that shows the throughput performance of 7B-parameter model in terms of tokens/second/gpu over different numbers of P5 instances:
The preceding tables show how, when using FP8, the training of 1B models is faster by 13% and training of 7B models is faster by 18%. As model training speed increases with FP8, there is generally a trade-off with a slower decrease in loss. However, the impact on model performance after one epoch remains minimal, with only about a 3% higher loss for 1B models and 2% higher loss for 7B models using FP8 as compared to training without using FP8. The following graph illustrates the loss performance.
As discussed in Scalable multi-node training with TensorFlow, due to inter-node communication, a small decline in the overall throughput is observed as the number of nodes increases.

The impact on LLM training and beyond
The use of FP8 precision combined with SageMaker P5 instances has significant implications for the field of LLM training. By demonstrating the feasibility and effectiveness of this approach, it opens the door for other researchers and organizations to adopt similar techniques, accelerating progress in large model training. Moreover, the benefits of FP8 and advanced hardware extend beyond LLM training. These advancements can also accelerate research in fields like computer vision and reinforcement learning by enabling the training of larger, more complex models with less time and fewer resources, ultimately saving time and cost. In terms of inference, models with FP8 activations have shown to improve two-fold over BF16 models.
Conclusion
The adoption of FP8 precision and SageMaker P5 instances marks a significant milestone in the evolution of LLM training. By pushing the boundaries of model size, training speed, and efficiency, these advancements have opened up new possibilities for research and innovation in large models. As the AI community builds on these technological strides, we can expect even more breakthroughs in the future. Ongoing research is exploring further improvements through techniques such as PyTorch 2.0 Fully Sharded Data Parallel (FSDP) and TorchCompile. Coupling these advancements with FP8 training could lead to even faster and more efficient LLM training. For those interested in the potential impact of FP8, experiments with 1B or 7B models, such as GPT-Neo or Meta Llama 2, on SageMaker P5 instances could offer valuable insights into the performance differences compared to FP16 or FP32.
About the Authors


