
In this post, we discuss how generative artificial intelligence (AI) can help health insurance plan members get the information they need. Many health insurance plan beneficiaries find it challenging to navigate through the complex member portals provided by their insurance plans. These portals often require multiple clicks, filters, and searches to find specific information about their benefits, deductibles, claim history, and other important details. This can lead to dissatisfaction, confusion, and increased calls to customer service, resulting in a suboptimal experience for both members and providers.
The problem arises from the inability of traditional UIs to understand and respond to natural language queries effectively. Members are forced to learn and adapt to the system’s structure and terminology, rather than the system being designed to understand their natural language questions and provide relevant information seamlessly. Generative AI technology, such as conversational AI assistants, can potentially solve this problem by allowing members to ask questions in their own words and receive accurate, personalized responses. By integrating generative AI powered by Amazon Bedrock and purpose-built AWS data services such as Amazon Relational Database Service (Amazon RDS) into member portals, healthcare payers and plans can empower their members to find the information they need quickly and effortlessly, without navigating through multiple pages or relying heavily on customer service representatives. Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon through a unified API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
The solution presented in this post not only enhances the member experience by providing a more intuitive and user-friendly interface, but also has the potential to reduce call volumes and operational costs for healthcare payers and plans. By addressing this pain point, healthcare organizations can improve member satisfaction, reduce churn, and streamline their operations, ultimately leading to increased efficiency and cost savings.

Figure 1: Solution Demo
Solution overview
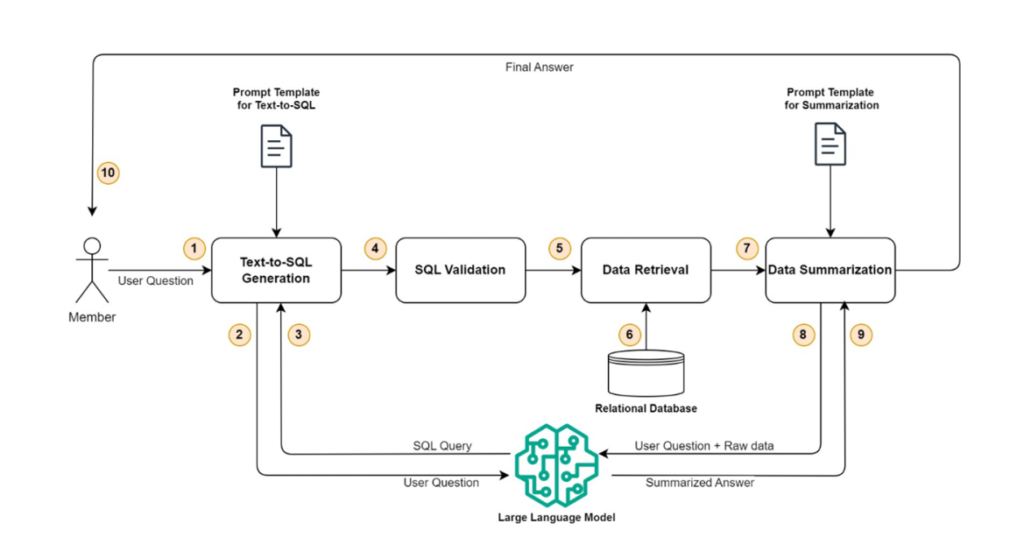
In this section, we dive deep to show how you can use generative AI and large language models (LLMs) to enhance the member experience by transitioning from a traditional filter-based claim search to a prompt-based search, which allows members to ask questions in natural language and get the desired claims or benefit details. From a broad perspective, the complete solution can be divided into four distinct steps: text-to-SQL generation, SQL validation, data retrieval, and data summarization. The following diagram illustrates this workflow.

Figure 2: Logical Workflow
Let’s dive deep into each step one by one.
Text-to-SQL generation
This step takes the user’s questions as input and converts that into a SQL query that can be used to retrieve the claim- or benefit-related information from a relational database. A pre-configured prompt template is used to call the LLM and generate a valid SQL query. The prompt template contains the user question, instructions, and database schema along with key data elements, such as member ID and plan ID, which are necessary to limit the query’s result set.
SQL validation
This step validates the SQL query generated in previous step and makes sure it’s complete and safe to be run on a relational database. Some of the checks that are performed include:
- No delete, drop, update, or insert operations are present in the generated query
- The query starts with select
- WHERE clause is present
- Key conditions are present in the WHERE clause (for example, member-id = “78687576501” or member-id like “786875765%%”)
- Query length (string length) is in expected range (for example, not more than 250 characters)
- Original user question length is in expected range (for example, not more than 200 characters)
If a check fails, the query isn’t run; instead, a user-friendly message suggesting that the user contact customer service is sent.
Data retrieval
After the query has been validated, it is used to retrieve the claims or benefits data from a relational database. The retrieved data is converted into a JSON object, which is used in the next step to create the final answer using an LLM. This step also checks if no data or too many rows are returned by the query. In both cases, a user-friendly message is sent to the user, suggesting they provide more details.
Data summarization
Finally, the JSON object retrieved in the data retrieval step along with the user’s question is sent to LLM to get the summarized response. A pre-configured prompt template is used to call the LLM and generate a user-friendly summarized response to the original question.
Architecture
The solution uses Amazon API Gateway, AWS Lambda, Amazon RDS, Amazon Bedrock, and Anthropic Claude 3 Sonnet on Amazon Bedrock to implement the backend of the application. The backend can be integrated with an existing web application or portal, but for the purpose of this post, we use a single page application (SPA) hosted on Amazon Simple Storage Service (Amazon S3) for the frontend and Amazon Cognito for authentication and authorization. The following diagram illustrates the solution architecture.

Figure 3: Solution Architecture
The workflow consists of the following steps:
- A single page application (SPA) is hosted using Amazon S3 and loaded into the end-user’s browser using Amazon CloudFront.
- User authentication and authorization is done using Amazon Cognito.
- After a successful authentication, a REST API hosted on API Gateway is invoked.
- The Lambda function, exposed as a REST API using API Gateway, orchestrates the logic to perform the functional steps: text-to-SQL generation, SQL validation, data retrieval, and data summarization. The Amazon Bedrock API endpoint is used to invoke the Anthropic Claude 3 Sonnet LLM. Claim and benefit data is stored in a PostgreSQL database hosted on Amazon RDS. Another S3 bucket is used for storing prompt templates that will be used for SQL generation and data summarizations. This solution uses two distinct prompt templates:
- The text-to-SQL prompt template contains the user question, instructions, database schema along with key data elements, such as member ID and plan ID, which are necessary to limit the query’s result set.
- The data summarization prompt template contains the user question, raw data retrieved from the relational database, and instructions to generate a user-friendly summarized response to the original question.
- Finally, the summarized response generated by the LLM is sent back to the web application running in the user’s browser using API Gateway.
Sample prompt templates
In this section, we present some sample prompt templates.
The following is an example of a text-to-SQL prompt template:
The {text1} and {text2} data items will be replaced programmatically to populate the ID of the logged-in member and user question. Also, more examples can be added to help the LLM generate appropriate SQLs.
The following is an example of a data summarization prompt template:
The {text1}, {text2}, and {text3} data items will be replaced programmatically to populate the user question, the SQL query generated in the previous step, and data formatted in JSON and retrieved from Amazon RDS.
Security
Amazon Bedrock is in scope for common compliance standards such as Service and Organization Control (SOC), International Organization for Standardization (ISO), and Health Insurance Portability and Accountability Act (HIPAA) eligibility, and you can use Amazon Bedrock in compliance with the General Data Protection Regulation (GDPR). The service enables you to deploy and use LLMs in a secured and controlled environment. The Amazon Bedrock VPC endpoints powered by AWS PrivateLink allow you to establish a private connection between the virtual private cloud (VPC) in your account and the Amazon Bedrock service account. It enables VPC instances to communicate with service resources without the need for public IP addresses. We define the different accounts as follows:
- Customer account – This is the account owned by the customer, where they manage their AWS resources such as RDS instances and Lambda functions, and interact with the Amazon Bedrock hosted LLMs securely using Amazon Bedrock VPC endpoints. You should manage access to Amazon RDS resources and databases by following the security best practices for Amazon RDS.
- Amazon Bedrock service accounts – This set of accounts is owned and operated by the Amazon Bedrock service team, which hosts the various service APIs and related service infrastructure.
- Model deployment accounts – The LLMs offered by various vendors are hosted and operated by AWS in separate accounts dedicated for model deployment. Amazon Bedrock maintains complete control and ownership of model deployment accounts, making sure no LLM vendor has access to these accounts.
When a customer interacts with Amazon Bedrock, their requests are routed through a secured network connection to the Amazon Bedrock service account. Amazon Bedrock then determines which model deployment account hosts the LLM model requested by the customer, finds the corresponding endpoint, and routes the request securely to the model endpoint hosted in that account. The LLM models are used for inference tasks, such as generating text or answering questions.
No customer data is stored within Amazon Bedrock accounts, nor is it ever shared with LLM providers or used for tuning the models. Communications and data transfers occur over private network connections using TLS 1.2+, minimizing the risk of data exposure or unauthorized access.
By implementing this multi-account architecture and private connectivity, Amazon Bedrock provides a secure environment, making sure customer data remains isolated and secure within the customer’s own account, while still allowing them to use the power of LLMs provided by third-party providers.
Conclusion
Empowering health insurance plan members with generative AI technology can revolutionize the way they interact with their insurance plans and access essential information. By integrating conversational AI assistants powered by Amazon Bedrock and using purpose-built AWS data services such as Amazon RDS, healthcare payers and insurance plans can provide a seamless, intuitive experience for their members. This solution not only enhances member satisfaction, but can also reduce operational costs by streamlining customer service operations. Embracing innovative technologies like generative AI becomes crucial for organizations to stay competitive and deliver exceptional member experiences.
To learn more about how generative AI can accelerate health innovations and improve patient experiences, refer to Payors on AWS and Transforming Patient Care: Generative AI Innovations in Healthcare and Life Sciences (Part 1). For more information about using generative AI with AWS services, refer to Build generative AI applications with Amazon Aurora and Knowledge Bases for Amazon Bedrock and the Generative AI category on the AWS Database Blog.
About the Authors





