Large language models (LLMs) can understand and generate human-like text by encoding vast knowledge repositories within their parameters. This capacity enables them to perform complex reasoning tasks, adapt to various applications, and interact effectively with humans. However, despite their remarkable achievements, researchers continue to investigate the mechanisms underlying the storage and utilization of knowledge in these systems, aiming to enhance their efficiency and reliability further.
A key challenge in using large language models is their propensity to generate inaccurate, biased, or hallucinatory outputs. These problems arise from a limited understanding of how such models organize and access knowledge. Without clear insights into the internal interactions of various components within these architectures, addressing errors or optimizing performance remains a significant hurdle. Existing studies often focus on individual elements, such as specific attention heads or MLPs, rather than exploring the broader and more intricate relationships between them. This fragmented understanding substantially restricts the ability to improve factual accuracy and safe knowledge retrieval.
Conventional approaches for analyzing language models typically focus on knowledge neurons within MLP layers. These neurons are presumed to store factual information, acting as key-value memory. Knowledge editing techniques have been developed to refine this stored data, addressing inaccuracies and updating biases. However, these methods often need better generalization, unintended disruptions to related knowledge, and failure to utilize the edited information fully. Further, such methods overlook the synergistic functioning of various components within the Transformer, further limiting their efficacy in resolving knowledge-related challenges.
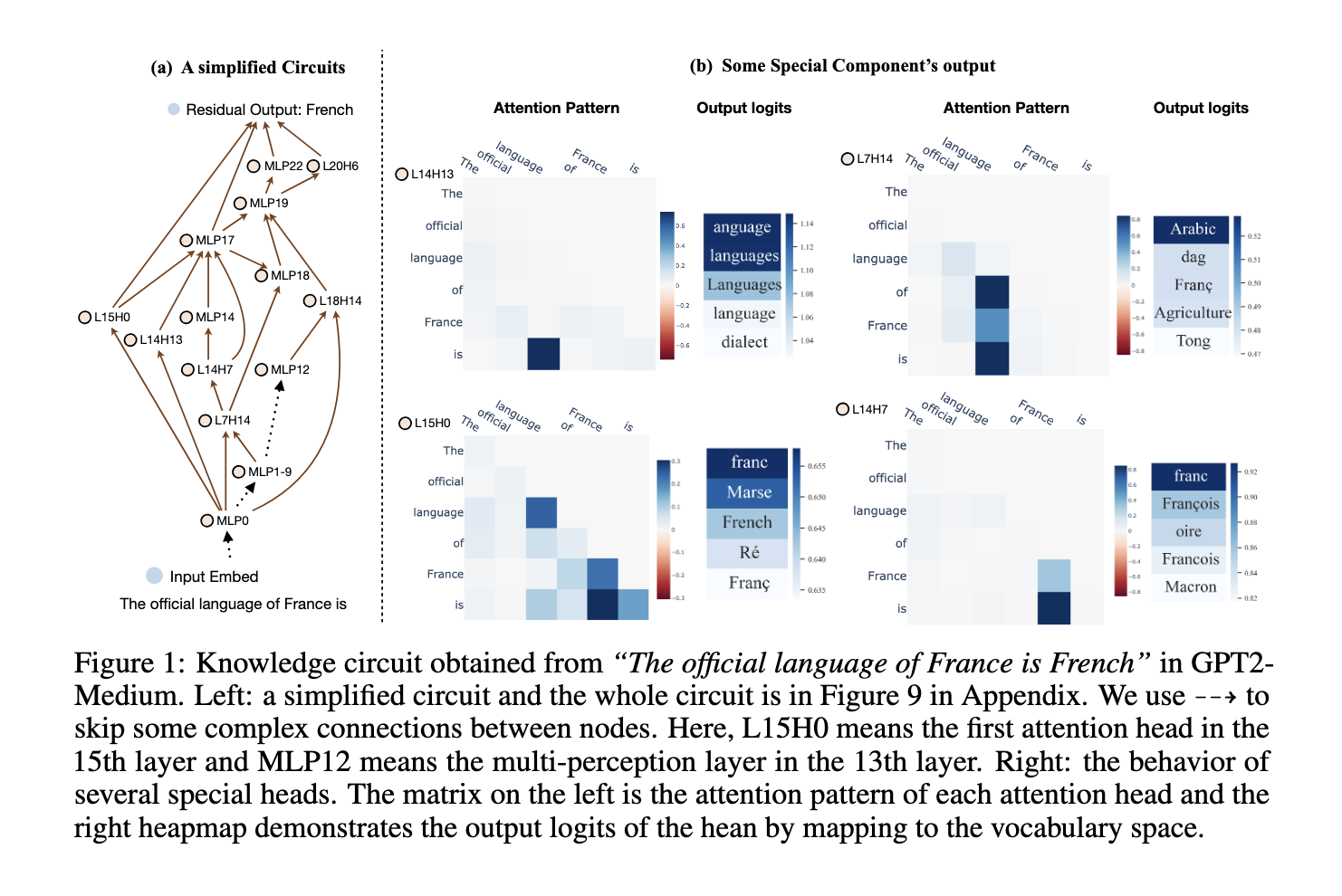
Researchers from Zhejiang University and the National University of Singapore proposed a new approach to overcome these challenges, introducing the concept of “knowledge circuits.” These circuits represent interconnected subgraphs within a Transformer’s computational graph, incorporating MLPs, attention heads, and embeddings. The researchers employed GPT-2 and TinyLLAMA models to demonstrate how knowledge circuits work collaboratively to store, retrieve, and apply knowledge effectively. This method emphasizes the interplay between components rather than treating them as isolated units, offering a more holistic perspective on the internal mechanisms of LLMs.
To construct knowledge circuits, researchers systematically analyzed the computational graph of the models by ablating specific edges and observing the resulting changes in performance. This process involved identifying critical connections and determining how various components interact to produce accurate outputs. Through this approach, they uncovered specialized roles for components such as “mover heads” that transfer information across tokens and “relation heads” that focus on contextual relationships within the input. These circuits were shown to aggregate knowledge in earlier layers and refine it in later stages to enhance predictive accuracy. Detailed experiments revealed how these circuits process factual, commonsense, and social bias-related knowledge.
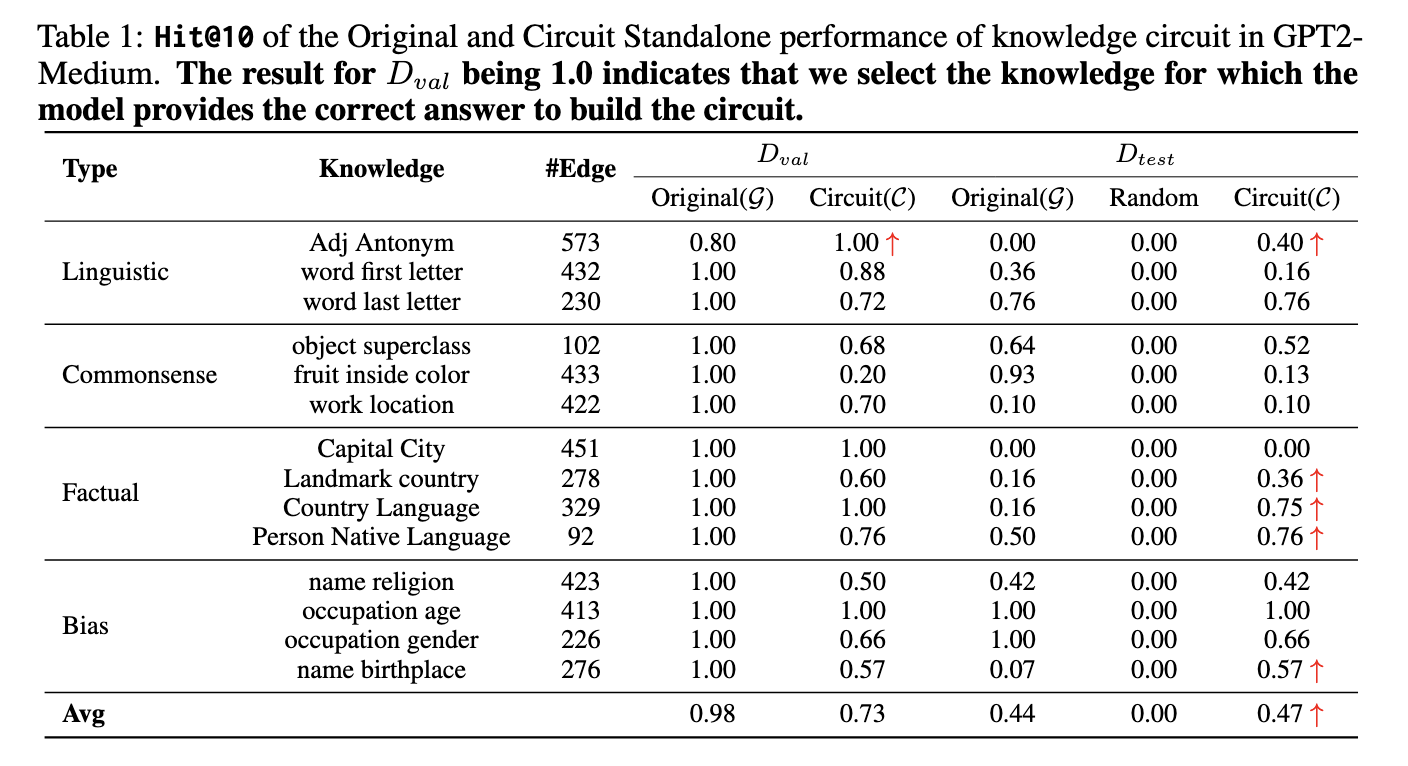
The researchers demonstrated that knowledge circuits could independently maintain over 70% of a model’s original performance while utilizing only 10% of its total parameters. Specific tasks saw substantial improvements. For example, performance on landmark-country relations increased from a baseline of 16% to 36%, indicating that removing noise and focusing on essential circuits enhanced accuracy. The analysis also showed that knowledge circuits improve the model’s ability to interpret complex phenomena like hallucinations and in-context learning. Hallucinations were linked to failures in information transfer within the circuits, while in-context learning was associated with the emergence of new attention heads that adapt to the provided demonstrations. Metrics such as Hit@10, which measures the ranking accuracy of predicted tokens, were used to validate these findings.
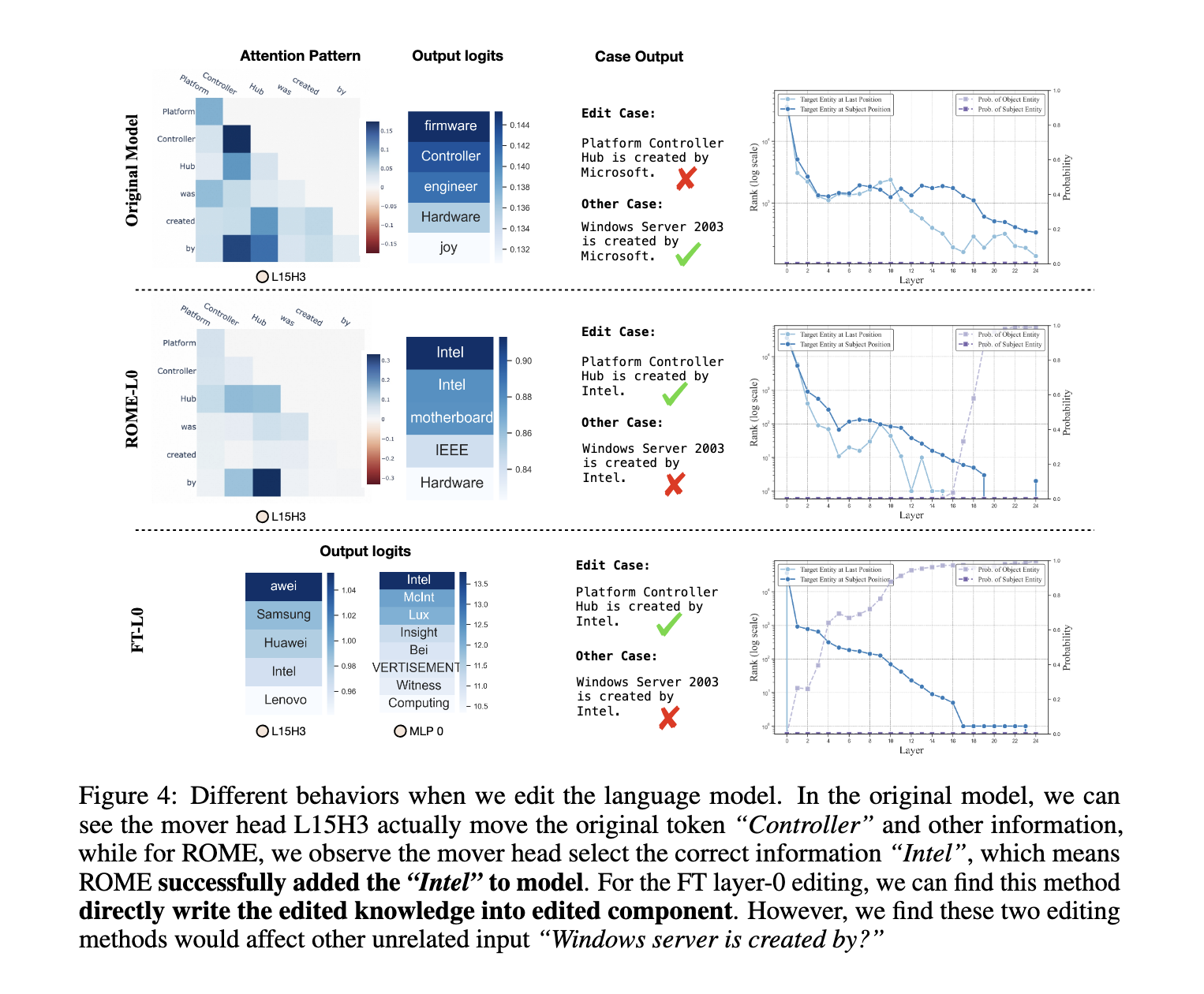
The study revealed limitations in existing knowledge-editing methods. Techniques like ROME and fine-tuning layer methods successfully added new knowledge but often disrupted unrelated areas. For example, when modifying a model to associate “Intel” with specific hardware, unrelated queries about “Windows servers” erroneously reflected the edited knowledge. This highlighted the risk of overfitting and the need for more precise and robust editing mechanisms. The findings underscored the importance of considering the broader context of knowledge circuits rather than focusing solely on individual layers or neurons.
In conclusion, this research provides a novel and detailed perspective on the internal workings of large language models by emphasizing knowledge circuits. Shifting the focus from isolated components to interconnected structures offers a comprehensive framework for analyzing and improving transformer-based models. The insights gained from this study pave the way for better knowledge storage, safer editing practices, and enhanced model interpretability. Future work could expand on these findings to explore the scalability and application of knowledge circuits across diverse domains and architectures. This advancement holds promise for addressing longstanding challenges in machine learning and making LLMs more reliable and effective.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.
