Knowledge graphs are finding their way into financial practices, especially as powerful tools for competitor retrieval tasks. Graph’s ability to organize and analyze complex data effectively allows them to gain insights from competitive clues and reveal meaningful connections between companies. They thus substitute manual data collection and analysis methods with greater scalability and applicability scope. The performance of knowledge graphs could be further enhanced by combining them with graph embedding techniques. However, in financial tasks, current methods face many challenges, such as directed and undirected relationships, attributed nodes, and minimal annotated competitor connections. Thus, the current SOTA embedding methods are limited in finance due to the overwhelmingly complex structure of practical graphs. This article discusses a recent study that aims to improve competitor retrieval with the help of graph neural networks.
JPMorgan Chase researchers propose JPMorgan Proximity Embedding for Competitor Detection, a Novel Graph Neural Network for Competitor Retrieval in Financial Knowledge Graphs. JPEC utilizes graph neural networks to learn from first and second-order node proximity for effective competitor pattern capture. In financial graphs, competitor edges are generally sparse but provide essential learnings. Here, first-order proximity comes into the picture, which characterizes local connections and is used as supervised information that constrains the similarity of latent representations between pairs of competitors. The second-order proximity is used to learn graph structure and attributes simultaneously with the help of GCN Autoencoders. This is interesting because, conventionally, GCNs are designed for undirected graphs. Authors exploit its propagation function to exploit GCN in directed graph settings.
Additionally, the model uses a decoder to make up for the sparsity of the competitor’s edges, as mentioned earlier. The decoder enhances the model’s ability to extract information from the supply chain graph. The loss function for the second-order proximity is to minimize the difference between the original node feature vectors and the reconstructed ones.
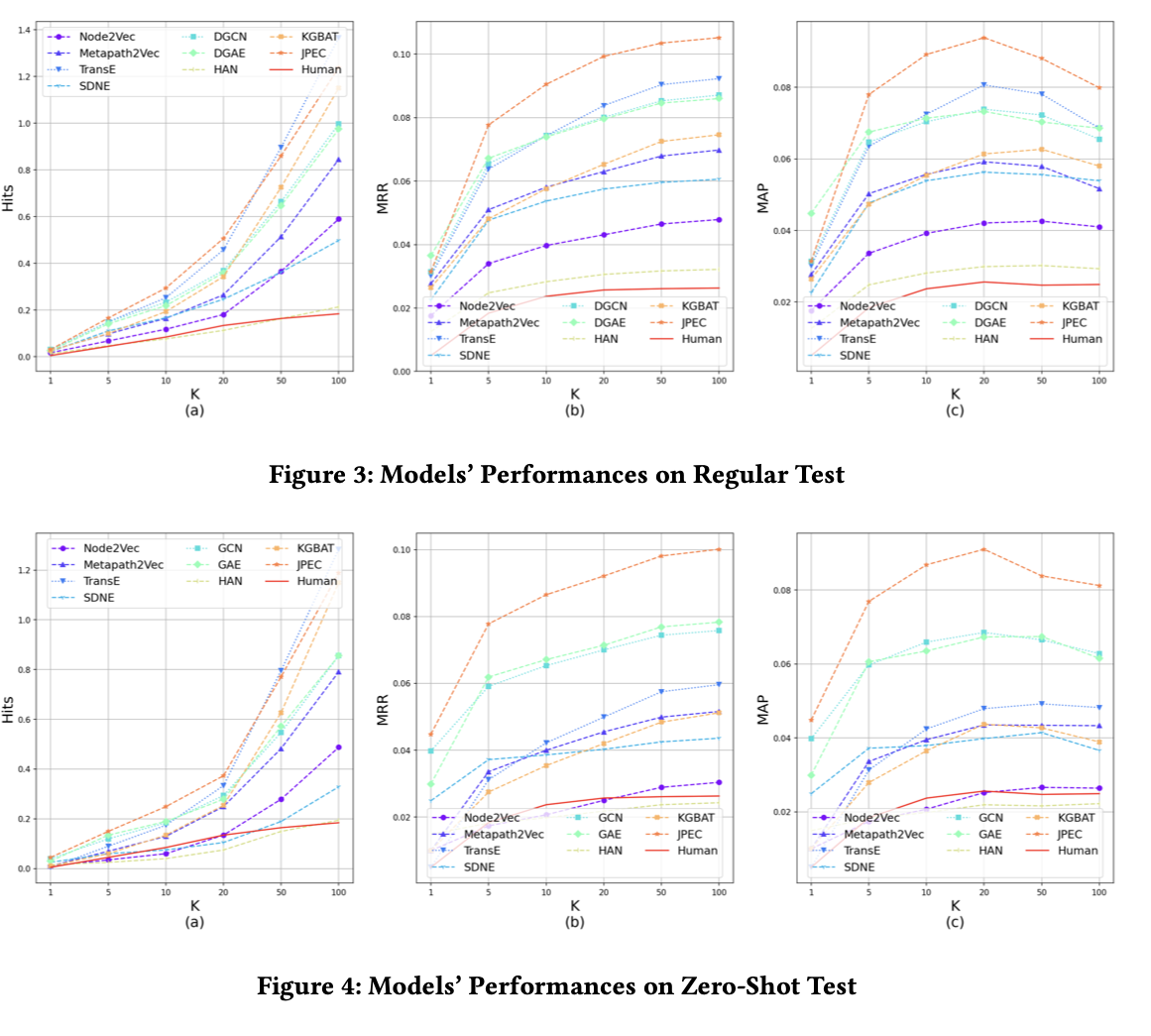
This model was evaluated on a dataset prepared from a large-scale financial knowledge graph that included various financial entities such as companies, investors, and bankers, along with their relationships. Two datasets were produced from A) the Regular Test Dataset and B) the Zero-Shot Test Dataset; for Zero-Shot Test Data, authors chose a subset of the graph and extracted COMPETE_WITH edges around them. They then removed all COMPETE_WITH connections between these nodes and the rest of the graph to ensure these nodes are unseen in the training competitor data. For the other category, the authors randomly sampled the remaining dataset. In contrast to the zero-shot test dataset, regular test data retained all nodes but randomly retained some COM PETE_WITH edges from the graph. While evaluating, the authors compared models’ performances with three ranking metrics -Hits, MRR or Mean Reciprocal Rank, and Mean Average Precision (MAP). The results of this analysis established that most machine learning-based methods outperformed human queries in competitor detection on regular testing data. For the Zero-shot dataset, structure-based embedding methods underperformed with problems of cold start, whereas attributed embedding methods performed well.
To sum up, JPEC utilized two orders of node proximity to enhance financial knowledge graphs. This method outperformed most state-of-the-art finance experts, who manually predicted competitors of a node.JPEC marks a significant advancement in the field, demonstrating the potential of knowledge graphs to uncover valuable patterns within complex networks, particularly in practical business applications.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[Upcoming Live LinkedIn event] ‘One Platform, Multimodal Possibilities,’ where Encord CEO Eric Landau and Head of Product Engineering, Justin Sharps will talk how they are reinventing data development process to help teams build game-changing multimodal AI models, fast‘
Adeeba Alam Ansari is currently pursuing her Dual Degree at the Indian Institute of Technology (IIT) Kharagpur, earning a B.Tech in Industrial Engineering and an M.Tech in Financial Engineering. With a keen interest in machine learning and artificial intelligence, she is an avid reader and an inquisitive individual. Adeeba firmly believes in the power of technology to empower society and promote welfare through innovative solutions driven by empathy and a deep understanding of real-world challenges.
