Symbolic regression is an advanced computational method to find mathematical equations that best explain a dataset. Unlike traditional regression, which fits data to predefined models, symbolic regression searches for the underlying mathematical structures from scratch. This approach has gained prominence in scientific fields like physics, chemistry, and biology, where researchers aim to uncover fundamental laws governing natural phenomena. By producing interpretable equations, symbolic regression allows scientists to explain patterns in data more intuitively, making it a valuable tool in the broader pursuit of automated scientific discovery.
A key challenge in symbolic regression is the enormous search space for potential hypotheses. As the complexity of data increases, the number of possible solutions grows exponentially, making it computationally prohibitive to search effectively. Traditional approaches, such as genetic algorithms, rely on random mutations and crossovers to evolve solutions, but they often need help with scalability and efficiency. As a result, there is an urgent need for more efficient methods to handle larger datasets without compromising accuracy or interpretability, thus driving advancements in scientific discovery.
Several existing methods attempt to tackle this problem, each with its limitations. Genetic algorithms, which use processes that mimic natural evolution to explore the search space, remain the most common. However, these techniques are often random and cannot incorporate domain-specific knowledge, slowing the search for useful solutions. Other methods, such as neural-guided search or deep reinforcement learning, have been employed but still need scalability. These approaches often require extensive computational resources and may not be practical for real-world scientific applications.
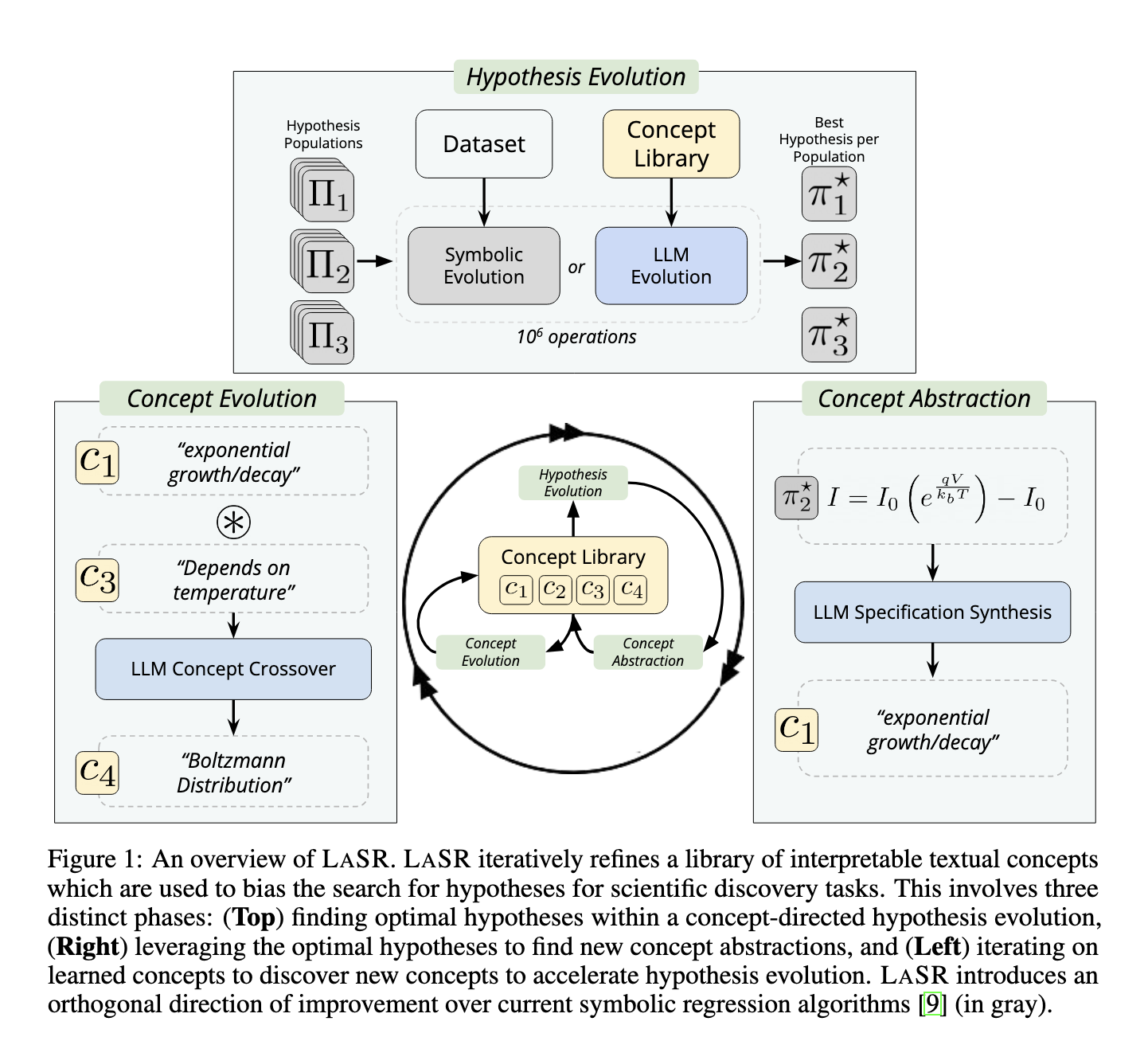
Researchers from UT Austin, MIT, Foundry Technologies, and the University of Cambridge developed a novel method called LASR (Learned Abstract Symbolic Regression). This innovative approach combines traditional symbolic regression with large language models (LLMs) to introduce a new layer of efficiency and accuracy. The researchers designed LASR to build a library of abstract, reusable concepts to guide the hypothesis generation process. By leveraging LLMs, the method reduces the reliance on random evolutionary steps and introduces a knowledge-driven mechanism that directs the search toward more relevant solutions.
The methodology of LASR is structured into three key phases. In the first phase, hypothesis evolution, genetic operations like mutation and crossover are applied to the hypothesis pool. However, unlike traditional methods, these operations are conditioned on abstract concepts generated by LLMs. In the second phase, the top-performing hypotheses are summarized into textual concepts. These concepts are stored in a library to bias the hypothesis search in subsequent iterations. In the final phase, concept evolution, the stored concepts are refined and evolved using additional LLM-guided operations. This iterative loop between concept abstraction and hypothesis evolution accelerates the search for accurate and interpretable solutions. The method ensures that prior knowledge is used and evolves alongside the hypotheses being tested.
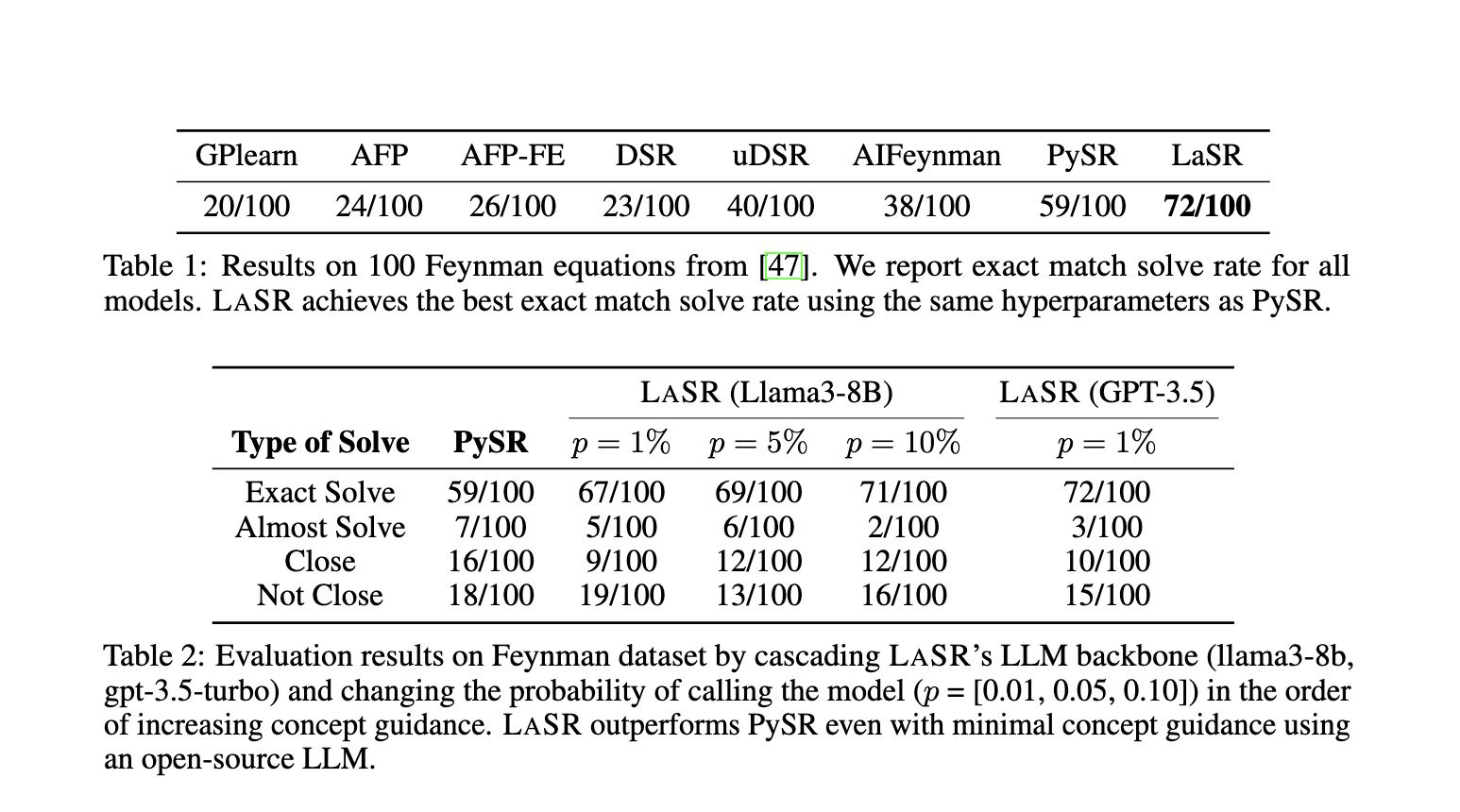
The performance of LASR was tested on a variety of benchmarks, including the Feynman Equations, which consist of 100 physics equations drawn from the famous *Feynman Lectures on Physics*. LASR significantly outperformed state-of-the-art symbolic regression approaches in these tests. While the best traditional methods solved 59 out of 100 equations, LASR successfully discovered 66. This is a remarkable improvement, particularly given that the method was tested with the same hyperparameters as its competitors. Further, in synthetic benchmarks designed to simulate real-world scientific discovery tasks, LASR consistently showed superior performance compared to baseline methods. The results underscore the efficiency of combining LLMs with evolutionary algorithms to improve symbolic regression.
A key finding of the LASR method was its ability to discover novel scaling laws for large language models, a crucial aspect in improving LLM performance. For instance, LASR identified a new scaling law by analyzing data from the BIG-Bench evaluation suite, a benchmark for LLMs. The research team discovered that increasing the number of in-context examples during model training exponentially enhances performance for low-resource models, but this gain diminishes as training progresses. This novel insight demonstrates the broader utility of LASR beyond symbolic regression, potentially influencing the future development of LLMs.
Overall, the LASR method represents a significant step forward in symbolic regression. By introducing a knowledge-driven, concept-guided approach, it offers a solution to the scalability issues that have long plagued traditional methods. Using LLMs to generate abstract concepts provides a new layer of efficiency, allowing the method to converge faster on accurate and interpretable equations. The success of LASR in outperforming existing methods on benchmark tests and discovering new insights in LLM scaling laws highlights its potential to drive advancements in symbolic regression and machine learning.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.
