Log-based anomaly detection has become essential for improving software system reliability by identifying issues from log data. However, traditional deep learning methods often struggle to interpret the semantic details in log data, typically in natural language. LLMs, like GPT-4 and Llama 3, have shown promise in handling such tasks due to their advanced language comprehension. Current LLM-based methods for anomaly detection include prompt engineering, which uses LLMs in zero/few-shot setups, and fine-tuning, which adapts models to specific datasets. Despite their advantages, these methods face challenges in customizing detection accuracy and managing memory efficiency.
The study reviews approaches to log-based anomaly detection, focusing on deep learning methods, especially those using pretrained LLMs. Traditional techniques include reconstruction-based methods (such as autoencoders and GANs), which rely on training models to reconstruct normal log sequences and detect anomalies based on reconstruction errors. Binary classification methods, typically supervised, detect anomalies by classifying log sequences as normal or abnormal. LLMs, including BERT and GPT-based models, are employed in two primary strategies: prompt engineering, which utilizes the internal knowledge of LLMs, and fine-tuning, which customizes models for specific datasets to improve anomaly detection performance.
Researchers from SJTU, Shanghai, developed LogLLM, a log-based anomaly detection framework utilizing LLMs. Unlike traditional methods that require log parsers, LogLLM preprocesses logs with regular expressions. It leverages BERT to extract semantic vectors and uses Llama, a transformer decoder, for log sequence classification. A projector aligns the vector spaces of BERT and Llama to maintain semantic coherence. LogLLM’s innovative three-stage training process enhances its performance and adaptability. Experiments across four public datasets show that LogLLM outperforms existing methods, accurately detecting anomalies, even in unstable logs with evolving templates.
The LogLLM anomaly detection framework uses a three-step approach: preprocessing, model architecture, and training. Logs are first preprocessed using regular expressions to replace dynamic parameters with a constant token, simplifying model training. The model architecture combines BERT for extracting semantic vectors, a projector for aligning vector spaces, and Llama for classifying log sequences. The training process includes oversampling the minority class to address data imbalance, fine-tuning Llama for answer templates, training BERT and the projector for log embeddings, and finally, fine-tuning the entire model. QLoRA is used for efficient fine-tuning, minimizing memory usage while preserving performance.
The study evaluates LogLLM’s performance using four real-world datasets: HDFS, BGL, Liberty, and Thunderbird. LogLLM is compared with several semi-supervised, supervised, and non-deep learning methods, including DeepLog, LogAnomaly, PLELog, and RAPID. The evaluation uses metrics such as Precision, Recall, and F1-score. Results show LogLLM achieves superior performance across all datasets, with an average F1-score 6.6% higher than the best alternative, NeuralLog. The method efficiently balances precision and recall, outperforms others in anomaly detection, and demonstrates the importance of using labeled anomalies for training.
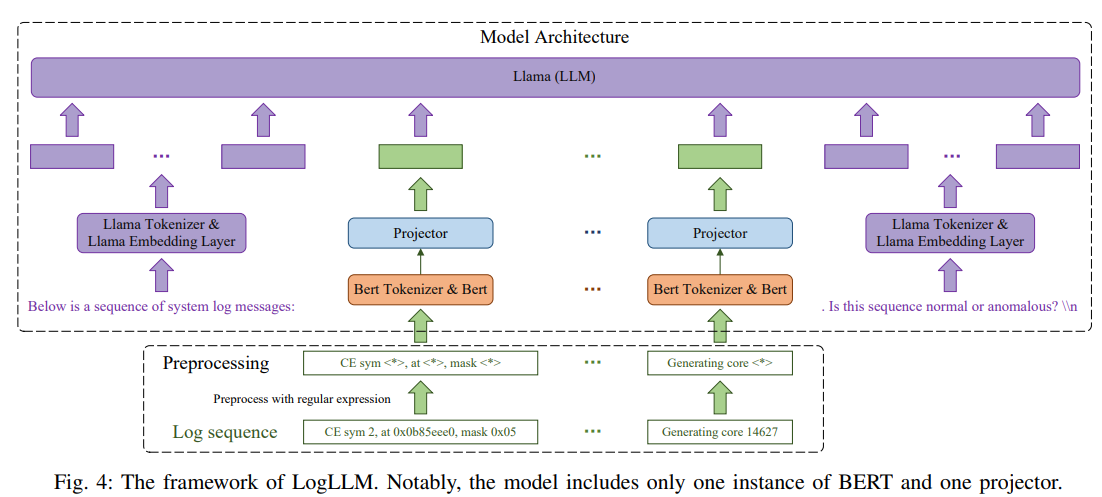
In conclusion, the study introduces LogLLM, a log-based anomaly detection framework that utilizes LLMs like BERT and Llama. BERT extracts semantic vectors from log messages, while Llama classifies log sequences. A projector is used to align the vector spaces of BERT and Llama for semantic consistency. Unlike traditional methods, LogLLM preprocesses logs with regular expressions, eliminating the need for log parsers. The framework is trained using a novel three-stage procedure to improve performance and adaptability. Experimental results on four public datasets show LogLLM outperforms existing methods, effectively detecting anomalies even in unstable log data.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[FREE AI WEBINAR] Implementing Intelligent Document Processing with GenAI in Financial Services and Real Estate Transactions– From Framework to Production
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.
