The rapid progress of text-to-image (T2I) diffusion models has made it possible to generate highly detailed and accurate images from text inputs. However, as the length of the input text increases, current encoding methods, such as CLIP (Contrastive Language-Image Pretraining), encounter various limitations. These methods struggle to capture the full complexity of long text descriptions, making it difficult to maintain alignment between the text and the generated images which creates challenges in correctly representing the detailed problems of longer texts, which is crucial for generating images that reflect the desired content. Additionally, there is a growing need for more advanced encoding techniques capable of handling text inputs and simultaneously preserving the precision and coherence of the generated images. While alternative methods like large language model (LLM)-based encoders can handle longer sequences, they fail to provide the same level of alignment as contrastive pre-training encoders do.

The growing popularity of diffusion models has been driven by advancements in fast sampling techniques and text-conditioned generation. Diffusion models transform a Gaussian distribution into a target data distribution via a multiple-step denoising process. The loss function helps predict noise added to clean data, with DDIM and DDPM cleaning this process. Stable Diffusion integrates a VAE, CLIP, and diffusion model to generate images from text prompts.
Preference models are refined with human feedback to better align generated images with text prompts. However, reward fine-tuning, which uses these models as signals, faces challenges like overfitting and inefficient backpropagation. Techniques like DRTune help by truncating gradients to improve sampling steps, though overfitting remains. Cascaded and latent space models allow for high-resolution image generation, enhancing style-consistent content creation and editing. Traditional evaluation metrics, like Inception Score (IS) and Fréchet Inception Distance (FID), have limitations, leading to newer approaches like perceptual similarity metrics (LPIPS), detection models, and human preference models. Methods like DPOK and DiffusionCLIP optimize outcomes using human preferences, while DRTune increases training speed by controlling input gradients, improving efficiency. To tackle these issues, a group of researchers from The University of Hong Kong, Sea AI Lab, Singapore, Renmin University of China, Zhejiang University have proposed LongAlign, which includes a segment-level encoding method for processing long texts and a decomposed preference optimization method for effective alignment training.
The researchers have proposed a segment-level encoding method to allow models with limited input capacity to process long-text inputs effectively. A preference decomposition approach is introduced, enabling preference models to generate T2I alignment scores alongside general preference scores, which enhances text alignment during the fine-tuning of generative models. After approximately 20 hours of fine-tuning, the proposed longSD model outperforms stronger foundation models in long-text alignment, demonstrating significant potential for improvement beyond the model’s architecture. LongAlign’s segment-level encoding overcomes input length limits by processing text segments separately. The decomposed preference optimization method uses CLIP-based preference models, decomposing preference scores into text-relevant and text-irrelevant parts. A reweighting strategy is applied to reduce overfitting and enhance alignment. Fine-tuning Stable Diffusion (SD) v1.5 with LongAlign for 20 hours resulted in superior T2I alignment compared to models like PixArt-α and Kandinsky v2.2
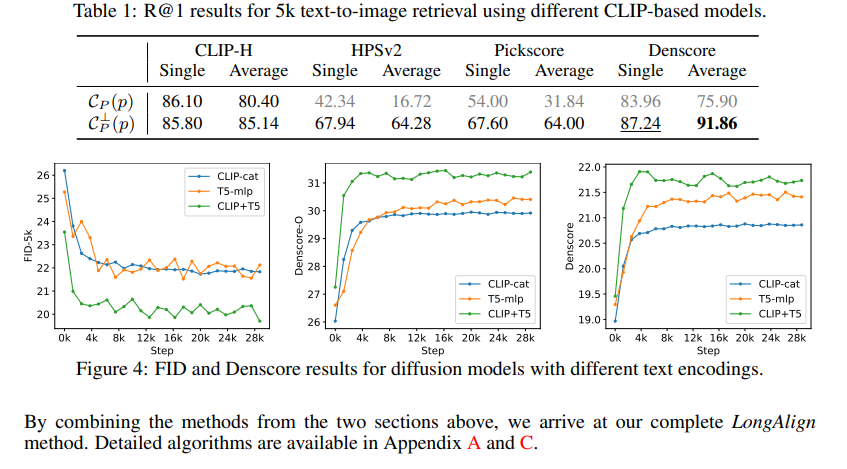
LongAlign divides the text into segments, encodes them individually, and merges the results. For diffusion models, it uses embedding concatenation, and for preference models, a segment-level loss for detailed preference scores. CLIP’s token limit is addressed by segment-level encoding. Direct embedding concatenation led to poor image quality, but retaining start-of-text embeddings, removing end-of-text embeddings, and introducing a new padding embedding improved merging. Both CLIP and T5 can be used for long-text encoding. Diffusion models are fine-tuned with large-scale, long texts paired with their corresponding images to ensure an accurate representation of text segments. In preference optimization, CLIP-based models are aligned by splitting long-text conditions into segments and defining a new segment-level preference training loss. This enables weakly supervised learning and generates detailed segment-level scores. Using preference models as reward signals for fine-tuning T2I diffusion models presents challenges in backpropagating gradients and managing overfitting. A reweighted gradient approach is introduced to address these issues. LongAlign combines these methods to improve long-text alignment; some experiments conducted showed that the LongAlign model achieved better generation results compared to the baseline models while effectively handling long-text inputs and displaying its advantages.
In conclusion, the LongAlign model significantly improves the alignment of generated images with long text input. It outperforms the existing models by introducing segment-level encoding and a decomposed preference optimization method, showcasing its efficiency in handling complex and lengthy text descriptions. This advancement strategy is beyond CLIP-based models with the limitation that the method still does not fully capture the generation of the exact number of entities specified by prompts, partly due to the constraints of CLIP.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase Inference Engine (Promoted)
Nazmi Syed is a consulting intern at MarktechPost and is pursuing a Bachelor of Science degree at the Indian Institute of Technology (IIT) Kharagpur. She has a deep passion for Data Science and actively explores the wide-ranging applications of artificial intelligence across various industries. Fascinated by technological advancements, Nazmi is committed to understanding and implementing cutting-edge innovations in real-world contexts.
