Large-scale multimodal foundation models have achieved notable success in understanding complex visual patterns and natural language, generating interest in their application to medical vision-language tasks. Progress has been made by creating medical datasets with image-text pairs and fine-tuning general domain models on these datasets. However, these datasets have limitations. They lack multi-granular annotations that link local and global information within medical images, which is crucial for identifying specific lesions from regional details. Additionally, current methods for constructing these datasets rely heavily on pairing medical images with reports or captions, limiting their scalability.
Researchers from UC Santa Cruz, Harvard University, and Stanford University have introduced MedTrinity-25M, a large-scale multimodal medical dataset containing over 25 million images across ten modalities. This dataset includes detailed multi-granular annotations for more than 65 diseases, encompassing global information like disease type and modality and local annotations such as bounding boxes and segmentation masks for regions of interest (ROIs). Using an automated pipeline, the researchers generated these comprehensive annotations without relying on paired text descriptions, enabling advanced multimodal tasks and supporting large-scale pretraining of medical AI models.
Medical multimodal foundation models have seen growing interest due to their ability to understand complex visual and textual features, leading to advancements in medical vision-language tasks. Models like Med-Flamingo and Med-PaLM have been fine-tuned on medical datasets to enhance their performance. However, the scale of available training data often limits these models. To address this, researchers have focused on constructing large medical datasets. However, datasets like MIMIC-CXR and RadGenome-Chest CT are constrained by the labor-intensive process of pairing images with detailed textual descriptions. In contrast, the MedTrinity-25M dataset uses an automated pipeline to generate comprehensive multi-granular annotations for unpaired photos, offering a significantly larger and more detailed dataset.
The MedTrinity-25M dataset features over 25 million images organized into triplets of {image, ROI, description}. Images span ten modalities and cover 65 diseases, sourced from repositories like TCIA and Kaggle. ROIs are highlighted with masks or bounding boxes, pinpointing abnormalities or key anatomical features. Multigranular textual descriptions detail the image modality, disease, and ROI specifics. The dataset construction involves generating coarse captions, identifying ROIs with models like SAT and BA-Transformer, and leveraging medical knowledge for accurate descriptions. MedTrinity-25M stands out for its scale, diversity, and detailed annotations compared to other datasets.
The study evaluated LLaVA-Med++ on biomedical Visual Question Answering (VQA) tasks using VQA-RAD, SLAKE, and PathVQA datasets to assess the impact of pretraining on the MedTrinity-25M dataset. Initial pretraining followed LLaVA-Med’s methodology, with additional fine-tuning on VQA datasets for three epochs. Results show that LLaVA-Med++ with MedTrinity-25M pretraining outperforms the baseline model by approximately 10.75% on VQA-RAD, 6.1% on SLAKE, and 13.25% on PathVQA. It achieves state-of-the-art results in two benchmarks and ranks third in the third, demonstrating significant performance improvements with MedTrinity-25M pretraining.
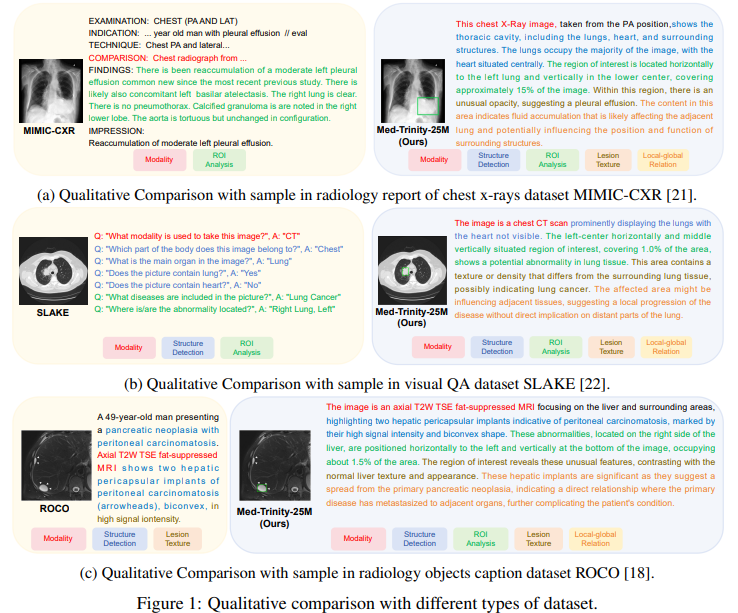
The study presents MedTrinity-25M, a vast multi-modal medical dataset with over 25 million image-ROI-description triplets from 90 sources, spanning ten modalities and covering over 65 diseases. Unlike previous methods reliant on paired image-text data, MedTrinity-25M is created using an automated pipeline that generates detailed annotations from unpaired images, leveraging expert models and advanced MLLMs. The dataset’s rich multi-granular annotations support a variety of tasks, including captioning, report generation, and classification. The model, pretrained on MedTrinity-25M, achieved state-of-the-art results in VQA tasks, highlighting its effectiveness for training multimodal medical AI models.
Check out the Paper and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 48k+ ML SubReddit
Find Upcoming AI Webinars here
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.

