
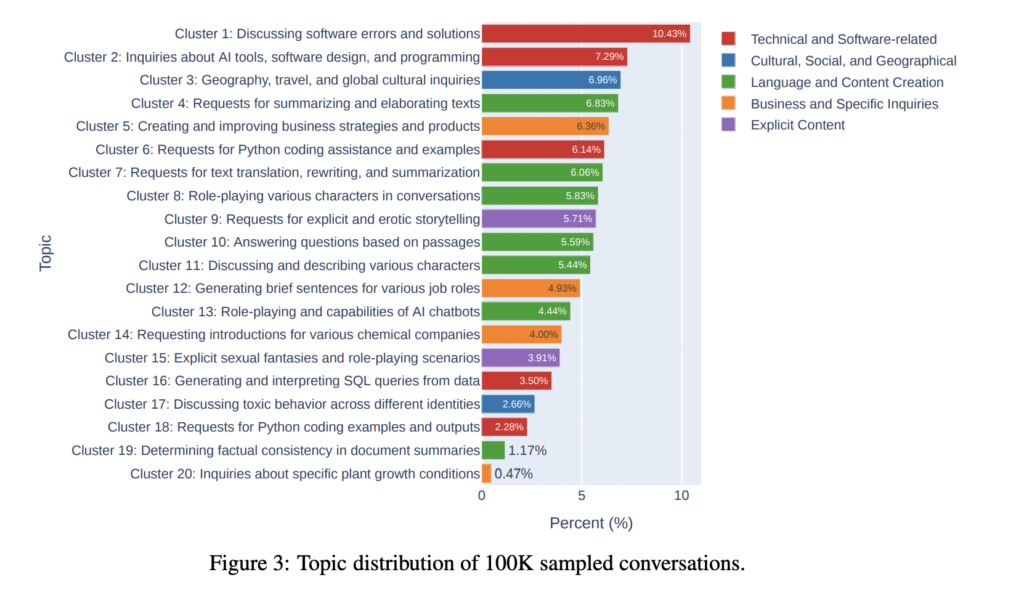
Large language models (LLMs) have become integral to various AI applications, from virtual assistants to code generation. Users adapt their behavior when engaging with LLMs, using specific queries and question formats for different purposes. Studying these patterns can provide insights into user expectations and trust in various LLMs. Moreover, understanding the range of questions, from simple facts to complex context-heavy queries, can help enhance LLMs to better serve users, prevent misuse, and enhance AI safety. It can be said that:
- High operational costs associated with running large language model services make it financially challenging for many organizations to collect real user question data.
- Companies that possess substantial user question datasets are hesitant to share them due to concerns about revealing their competitive advantages and the desire to maintain data privacy.
- Encouraging users to interact with open language models is a challenge because these models often don’t perform as well as those developed by major companies.
- This difficulty in user engagement with open models makes it challenging to compile a – substantial dataset that accurately reflects real user interactions with these models for research purposes.
To address this gap, this research paper introduces a novel large-scale, real-world dataset called LMSYS-Chat-1M. This dataset was carefully curated from an extensive collection of real interactions between large language models (LLMs) and users. These interactions were gathered during a period of five months by hosting a free online LLM service that provided access to 25 popular LLMs, encompassing both open-source and proprietary models. The service incurred significant computational resources, including several thousands of A100 hours.
To maintain user engagement over time, the authors implemented a competitive element known as the “chatbot arena” and incentivized users to utilize the service by regularly updating rankings and leaderboards for popular LLMs. Consequently, LMSYS-Chat-1M comprises over one million user conversations, showcasing a diverse range of languages and topics. Users provided their consent for their interactions to be used for this dataset through the “Terms of Use” section on the data collection website.
This dataset was collected from the Vicuna demo and Chatbot Arena website between April and August 2023. The website provides users with three chat interface options: a single model chat, a chatbot arena where chatbots battle, and a chatbot arena that allows users to compare two chatbots side-by-side. This platform is entirely free, and neither users are compensated nor are any fees imposed on them for its usage.
In this paper, the authors explore the potential applications of LMSYS-Chat-1M in four different use cases. They demonstrate that LMSYS-Chat-1M can effectively fine-tune small language models to serve as powerful content moderators, achieving performance similar to GPT-4. Additionally, despite safety measures in some served models, LMSYS-Chat-1M still contains conversations that can challenge the safeguards of leading language models, offering a new benchmark for studying model robustness and safety.
Furthermore, the dataset includes high-quality user-language model dialogues suitable for instruction fine-tuning. By using a subset of these dialogues, the authors show that Llama-2 models can achieve performance levels comparable to Vicuna and Llama2 Chat on specific benchmarks. Lastly, LMSYS-Chat-1M’s broad coverage of topics and tasks makes it a valuable resource for generating new benchmark questions for language models.
Check out the Paper and Dataset. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..


Janhavi Lande, is an Engineering Physics graduate from IIT Guwahati, class of 2023. She is an upcoming data scientist and has been working in the world of ml/ai research for the past two years. She is most fascinated by this ever changing world and its constant demand of humans to keep up with it. In her pastime she enjoys traveling, reading and writing poems.