
In today’s increasingly interconnected world, effective communication across languages is essential. However, many natural language processing (NLP) models still struggle with less common languages. This challenge is particularly evident for low-resource languages such as Thai, Mongolian, and Khmer, which lack the data and processing infrastructure available for languages like English or Chinese. Traditional NLP models often fail to adequately understand and generate text in a broad range of languages, limiting their effectiveness in multilingual applications. Consequently, both users and developers face challenges when deploying these models in diverse linguistic environments.
Meet Xmodel-1.5
Xmodel-1.5 is a 1-billion-parameter multilingual model pretrained on approximately 2 trillion tokens. Developed by Xiaoduo Technology’s AI Lab, Xmodel-1.5 aims to provide an inclusive NLP solution capable of strong performance across multiple languages, including Thai, Arabic, French, Chinese, and English. It is specifically designed to excel in both high-resource and low-resource languages. To support research in low-resource language understanding, the team has also released a Thai evaluation dataset consisting of questions annotated by students from Chulalongkorn University’s School of Integrated Innovation.
Xmodel-1.5 was trained on a diverse corpus from sources such as Multilang Wiki, CulturaX, and other language-specific datasets. It demonstrates the ability to generalize well in less-represented languages, making it a valuable tool for enhancing cross-linguistic understanding in natural language processing tasks.
Technical Details and Benefits
Xmodel-1.5 incorporates several advanced techniques to enhance its capabilities. It uses a unigram tokenizer, specifically trained to accommodate the nuances of multiple languages, resulting in a vocabulary of 65,280 tokens. The tokenizer balances efficiency and language coverage, making it suitable for multilingual tasks, including those with less standardized orthography. The model architecture includes features such as rotary positional embedding (RoPE), RMS normalization for improved training stability, and SwiGLU activation for optimized performance. Grouped-query attention is also employed to improve training and inference efficiency.
Trained with over 2 trillion tokens, Xmodel-1.5 uses a mix of high-resource and low-resource data sources, enabling the model to become proficient in both. Additionally, it employs a data distribution strategy to ensure adequate representation of low-resource languages during training. Post-training, instruction fine-tuning was conducted, further enhancing its proficiency, particularly in retrieval-augmented generation (RAG) tasks within the e-commerce domain, achieving a 92.47% satisfaction rate.
The Significance of Xmodel-1.5
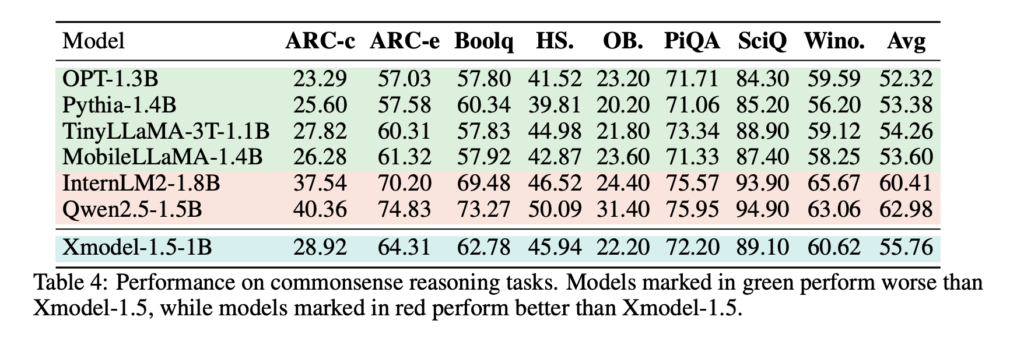
Xmodel-1.5 stands out for its multilingual capabilities and its focus on inclusivity for underrepresented linguistic communities. The inclusion of Thai, Arabic, and other languages highlights its commitment to bridging the gap between high-resource and low-resource languages. The release of an evaluation dataset for Thai provides a valuable benchmark for advancing multilingual NLP research. Compared to baseline models such as OPT, Pythia, and TinyLLaMA, Xmodel-1.5 demonstrated improved performance across several multilingual tasks, particularly in commonsense reasoning.


In multilingual tasks, Xmodel-1.5 achieved strong results, surpassing PolyLM-1.7B in various benchmarks, including ARC, XCOPA, and mMMLU. For instance, its performance in the Arabic variant of HellaSwag and the Thai subset of the Belebele Benchmark was higher than that of its competitors, demonstrating effective multilingual capabilities. This makes Xmodel-1.5 a valuable tool for real-world applications that require handling diverse linguistic input.
Conclusion
Xmodel-1.5 represents a significant advancement in multilingual NLP, particularly in addressing the needs of underrepresented languages. With its extensive pretraining, advanced model architecture, and focus on less common languages, Xmodel-1.5 is a versatile tool for bridging language gaps. The introduction of an open-source Thai evaluation dataset highlights its potential to contribute to future multilingual NLP research. As cross-cultural interactions continue to grow, tools like Xmodel-1.5 will play an important role in supporting effective and inclusive communication across language barriers. The model’s open availability ensures it is both a technological achievement and a practical asset for researchers and practitioners.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
Why AI-Language Models Are Still Vulnerable: Key Insights from Kili Technology’s Report on Large Language Model Vulnerabilities [Read the full technical report here]


Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.