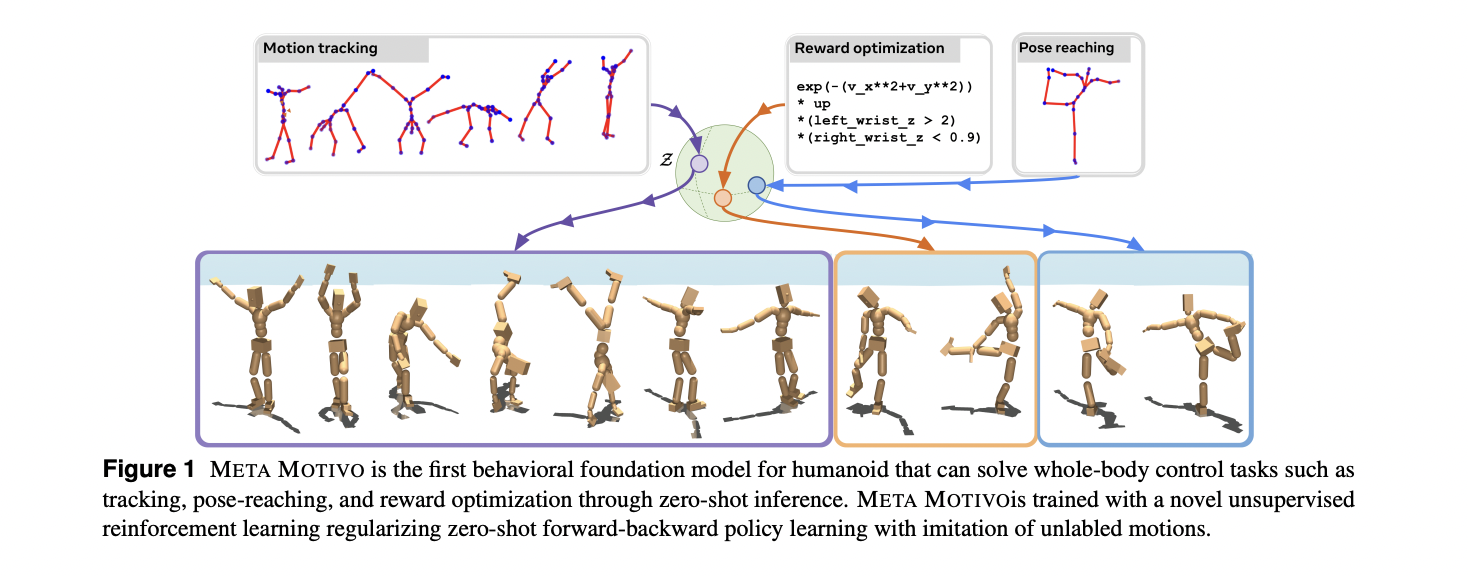
Foundation models, pre-trained on extensive unlabeled data, have emerged as a cutting-edge approach for developing versatile AI systems capable of solving complex tasks through targeted prompts. Researchers are now exploring the potential of extending this paradigm beyond language and visual domains, focusing on behavioral foundation models (BFMs) for agents interacting with dynamic environments. Specifically, the research aims to develop BFMs for humanoid agents, targeting whole-body control through proprioceptive observations. This approach addresses a long-standing challenge in robotics and AI, characterized by the high-dimensionality and intrinsic instability of humanoid control systems. The ultimate goal is to create generalized models that can express diverse behaviors in response to various prompts, including imitation, goal achievement, and reward optimization.
Meta researchers introduce FB-CPR (Forward-Backward representations with Conditional Policy Regularization), an innovative online unsupervised reinforcement learning algorithm designed to ground policy learning through observation-only unlabeled behaviors. The algorithm’s key technical innovation involves utilizing forward-backward representations to embed unlabeled trajectories into a shared latent space, utilizing a latent-conditional discriminator to encourage policies to comprehensively “cover” dataset states. Demonstrating the method’s effectiveness, the team developed META MOTIVO, a behavioral foundation model for whole-body humanoid control that can be prompted to solve diverse tasks such as motion tracking, goal reaching, and reward optimization in a zero-shot learning scenario. The model utilizes the SMPL skeleton and AMASS motion capture dataset to achieve remarkable behavioral expressiveness.
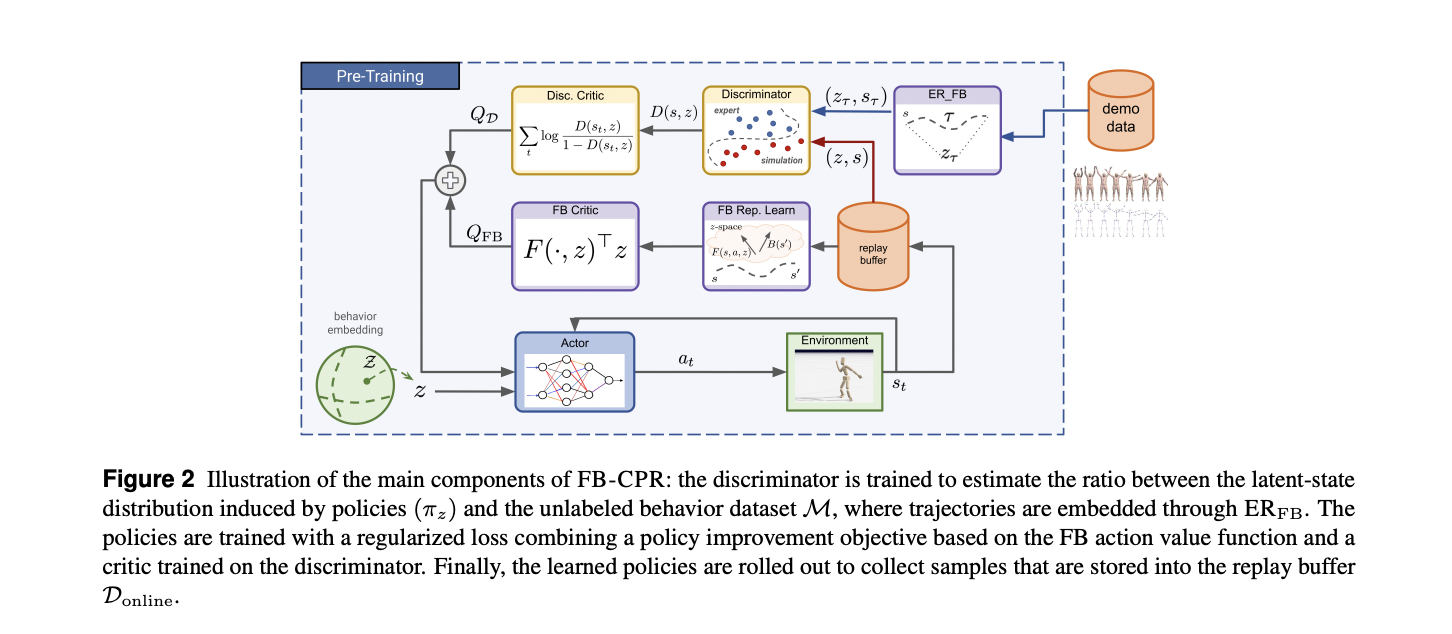
Researchers introduce a robust approach to forward-backward (FB) representation learning with conditional policy regularization. At the pre-training stage, the agent has access to an unlabeled behavior dataset containing observation-only trajectories. The method focuses on developing a continuous set of latent-conditioned policies where latent variables are drawn from a distribution defined over a latent space. By representing behaviors through the joint space of states and latent variables, the researchers aim to capture diverse motion patterns. The key innovation lies in inferring latent variables for each trajectory using the ERFB method, which allows encoding trajectories into a shared representational space. The ultimate goal is to regularize the unsupervised training of the behavioral foundation model by minimizing the discrepancy between the induced policy distribution and the dataset distribution.
The research presents a comprehensive performance evaluation of the FB-CPR algorithm across multiple task categories. FB-CPR demonstrates remarkable zero-shot capabilities, achieving 73.4% of top-line algorithm performance without explicit task-specific training. In reward-maximization tasks, the method outperforms unsupervised baselines, notably achieving 177% of DIFFUSER’s performance while maintaining significantly lower computational complexity. For goal-reaching tasks, FB-CPR performs comparably to specialized baselines, outperforming zero-shot alternatives by 48% and 118% in proximity and success metrics respectively. A human evaluation study further revealed that while task-specific algorithms might achieve higher numerical performance, FB-CPR was consistently perceived as more “human-like”, with participants rating its behaviors as more natural in 83% of reward-based tasks and 69% of goal-reaching scenarios.
This research introduced FB-CPR, a unique algorithm that combines zero-shot properties of forward-backward models with innovative regularization techniques for policy learning using unlabeled behavior datasets. By training the first behavioral foundation model for complex humanoid agent control, the method demonstrated state-of-the-art performance across diverse tasks. Despite its significant achievements, the approach has notable limitations. FB-CPR struggles with tasks far removed from motion-capture datasets and occasionally produces imperfect movements, particularly in scenarios involving falling or standing. The current model is restricted to proprioceptive observations and cannot navigate environments or interact with objects. Future research directions include integrating additional state variables, exploring complex perception methods, utilizing video-based human activity datasets, and developing more direct language-policy alignment techniques to expand the model’s capabilities and generalizability.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.
