The primary challenge in text embeddings in Natural Language Processing (NLP) lies in developing models that can perform equally well across different languages. Traditional models are often English-centric, limiting their efficacy in multilingual contexts. This gap highlights the need for embedding models trained on diverse linguistic data capable of understanding and interpreting multiple languages without losing accuracy or performance. Addressing this issue would significantly enhance the model’s utility in global applications, from automatic translation services to cross-lingual information retrieval systems.
The development of text embeddings relies heavily on monolingual datasets, predominantly in English, which narrows their applicability. While effective for English text, these methods often must be revised when applied to other languages. The approach typically involves training models on large datasets to capture linguistic nuances without considering the multilingual spectrum. As a result, there’s an evident performance disparity when these models are tasked with processing non-English languages, underscoring the necessity for more inclusive and diverse training methodologies.
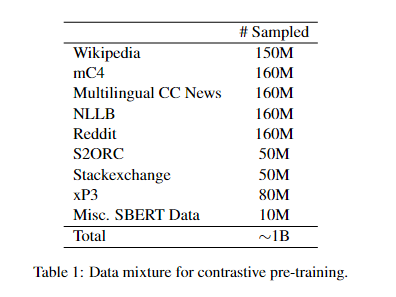
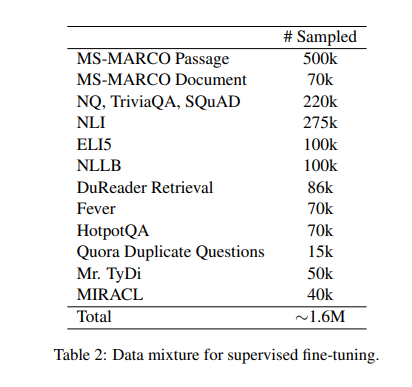
A research team at Microsoft Corporation has introduced the multilingual E5 text embedding models mE5-{small / base / large}, designed to address the above mentioned challenges. These models are trained using a methodology incorporating many languages, ensuring better performance across different linguistic contexts. By adopting a two-stage training process that includes contrastive pre-training on multilingual text pairs followed by supervised fine-tuning, the models aim to balance inference efficiency and embedding quality, making them highly versatile for various multilingual applications.
The multilingual E5 text embedding models are initialized from the multilingual MiniLM, xlm-robertabase, and xlm-roberta-large models. Contrastive pre-training is performed on 1 billion multilingual text pairs, followed by fine-tuning on a combination of labeled datasets. The mE5-large-instruct model is fine-tuned on a new data mixture that includes synthetic data from GPT-4. This method ensures that the models are proficient in English and exhibit high performance in other languages. The training process is designed to align the models closely with the linguistic properties of the target languages, using both weakly-supervised and supervised techniques. This approach enhances the models’ multilingual capabilities and ensures that they are adaptable to specific language tasks, providing a significant advancement in text embedding technologies.
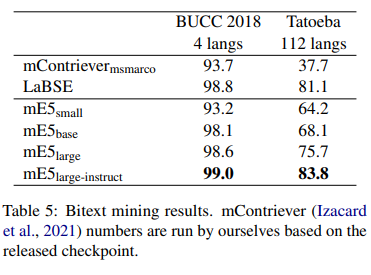
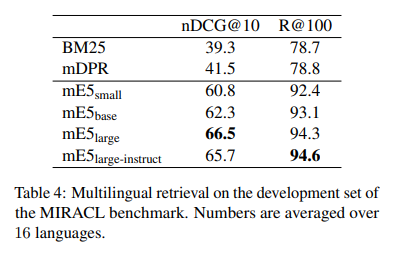
The models are evaluated on various datasets, including nDCG10, R100, MrTyDi, and DuReader. Upon evaluation, the multilingual E5 models demonstrated exceptional performance across multiple languages and benchmarks, including the MIRACL multilingual retrieval benchmark and Bitext mining in over 100 languages. The mE5 large-instruct model surpasses the performance of LaBSE, specifically designed for bitext mining, due to the expanded language coverage afforded by the synthetic data. The research validates the effectiveness of the proposed training methodology and the significant benefits of incorporating diverse linguistic data, showcasing the models’ ability to set new standards in multilingual text embedding.
Developing multilingual E5 text embedding models is a valuable advancement in NLP. By effectively addressing the limitations of prior models and introducing a robust methodology for training on diverse linguistic data, the research team has paved the way for more inclusive and efficient multilingual applications. These models enhance the performance of language-related tasks across different languages and significantly break down language barriers in digital communication, heralding a new era of global accessibility in information technology.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 37k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.
