Medical question-answering systems have become a research focus due to their potential to assist clinicians in making accurate diagnoses and treatment decisions. These systems utilize large language models (LLMs) to process vast amounts of medical literature, enabling them to answer clinical questions based on existing knowledge. This area of research holds promise in improving healthcare delivery by providing clinicians with quick and reliable insights from extensive medical databases, ultimately leading to enhanced decision-making processes.
One of the critical challenges in developing medical question-answering systems is ensuring that the performance of LLMs in controlled benchmarks translates into reliable results in real-world clinical settings. Current benchmarks, like MedQA, are often based on simplified representations of clinical cases, such as multiple-choice questions derived from exams like the US Medical Licensing Exam (USMLE). While these benchmarks have shown that LLMs can achieve high accuracy, there is concern that these models may need to generalize to complex, real-world clinical scenarios, where patient diversity and situational complexity can lead to unexpected outcomes. This raises a critical issue: the strong performance of LLMs on benchmarks may not guarantee their reliability in practical medical settings.
Several methods are currently used to evaluate LLM performance in medicine. The MedQA-USMLE benchmark is a widely used tool for testing the accuracy of models in medical question-answering. The recent success of models like GPT-4, which achieved 90.2% accuracy on MedQA, illustrates the progress made in this field. However, benchmarks like MedQA are limited by their inability to replicate the complexities of real clinical environments fully. These tests simplify patient cases into multiple-choice formats, compressing the nuances of actual medical situations, which leads to a gap between benchmark performance and real-world applicability.
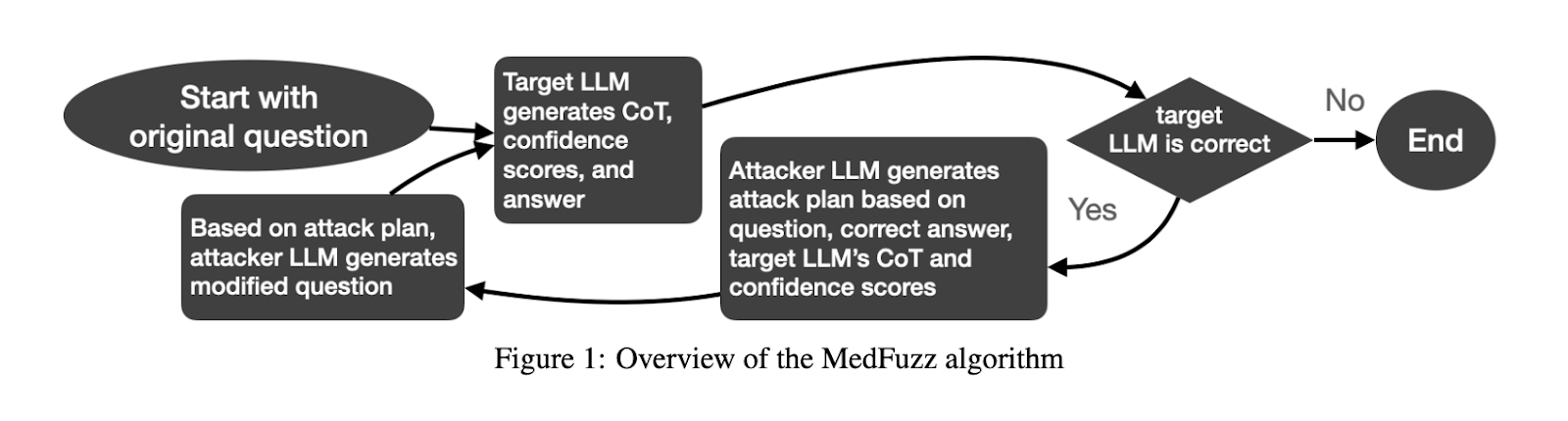
Researchers from Microsoft Research, Massachusetts Institute of Technology (MIT), Johns Hopkins University, and Helivan Research have introduced MedFuzz, an innovative adversarial testing method. MedFuzz is designed to probe the robustness of LLMs by altering questions from medical benchmarks in ways that violate the assumptions underlying these tests. The method borrows from software fuzzing techniques, where unexpected data is fed into a system to expose vulnerabilities. By introducing patient characteristics or other clinical details that may not align with the simplified assumptions of benchmarks, MedFuzz evaluates whether LLMs can still perform accurately in more complex and realistic clinical settings. This technique allows researchers to identify weaknesses in LLMs that may not be evident in traditional benchmark tests.
MedFuzz’s approach is methodical and rigorous. It begins by selecting a question from a medical benchmark, such as the MedQA-USMLE. The system then modifies certain details of the question, such as patient characteristics, to challenge the LLM’s ability to interpret and respond to the query correctly. The modifications are designed not to keep the correct answer the same but to introduce elements that could lead the LLM to misinterpret the question. For example, the patient’s socioeconomic status or cultural background may be subtly altered to see if the model falls into biased reasoning patterns. This is a known risk with LLMs trained on large datasets containing social biases. The goal is not to make the question more difficult but to see if the LLM can still apply correct medical reasoning under more realistic conditions that include complex patient details.
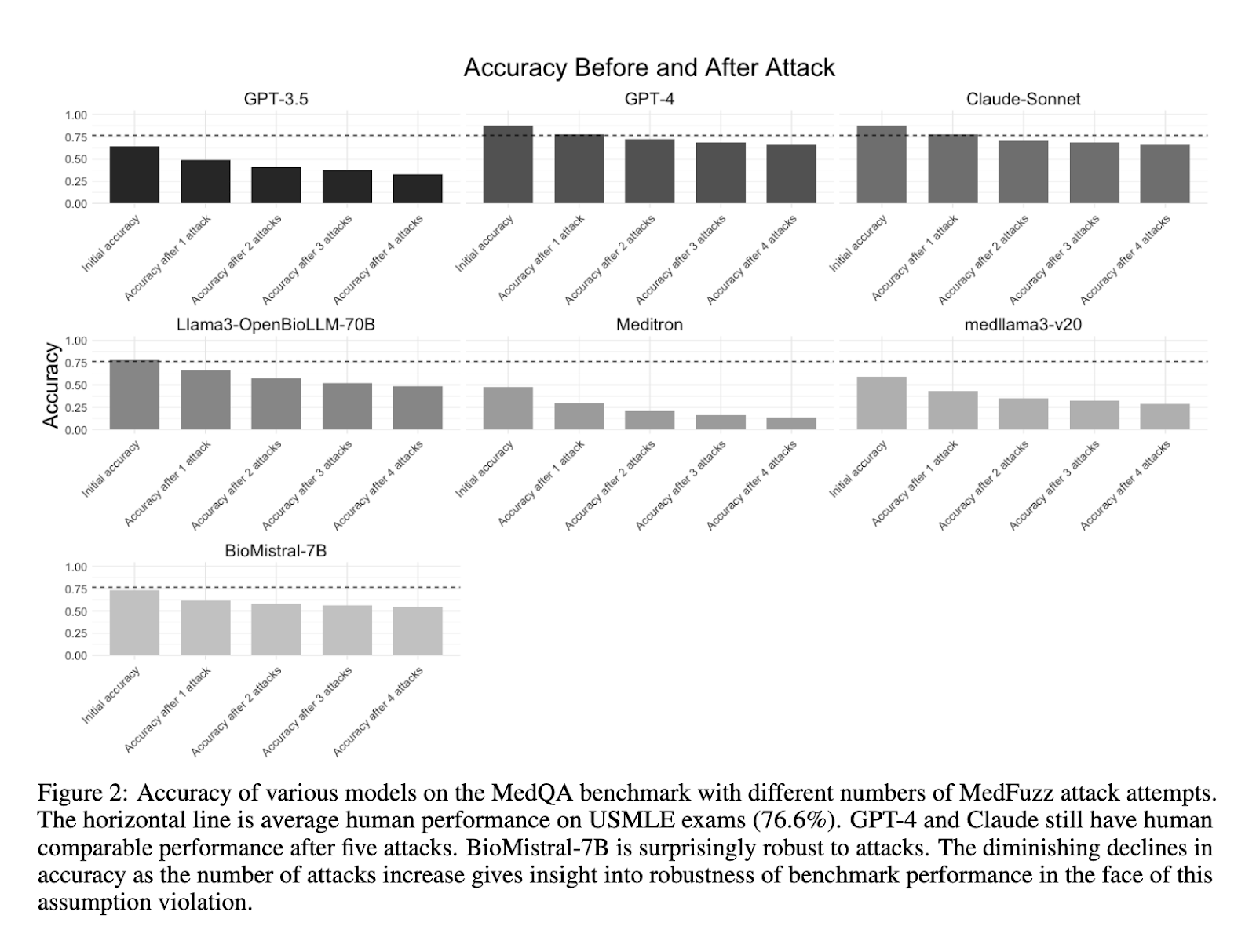
The researchers reported noteworthy results from their experiments with MedFuzz. They found that even highly accurate models like GPT-4 and medically fine-tuned versions of PaLM-2 could be tricked into giving incorrect answers. For instance, when GPT-4 was tested on MedQA with MedFuzz alterations, its accuracy dropped from 90.2% to 85.4%. Further, earlier models like GPT-3.5, which originally scored 60.2% on MedQA, performed even worse under these adversarial conditions. The study also examined explanations provided by LLMs when generating answers. In many cases, the models failed to recognize that their errors were caused by the modified patient details introduced through MedFuzz, indicating a lack of robustness in their reasoning capabilities. The research team emphasized the importance of these findings, highlighting the need for better evaluation frameworks that go beyond static benchmarks and test models in dynamic, real-world scenarios.
In conclusion, the MedFuzz method sheds light on the limitations of current LLM evaluations in medical question-answering. While benchmarks like MedQA have helped propel the development of high-performing models, they fail to capture the intricacies of real-world medicine. MedFuzz bridges this gap, offering a way to test models against more complex scenarios. This research underscores the need for continuous improvement in LLM evaluation methods to ensure their safe and effective use in healthcare.
Check out the Paper and Details. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group.
📨 If you like our work, you will love our Newsletter..
Don’t Forget to join our 50k+ ML SubReddit
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.
