
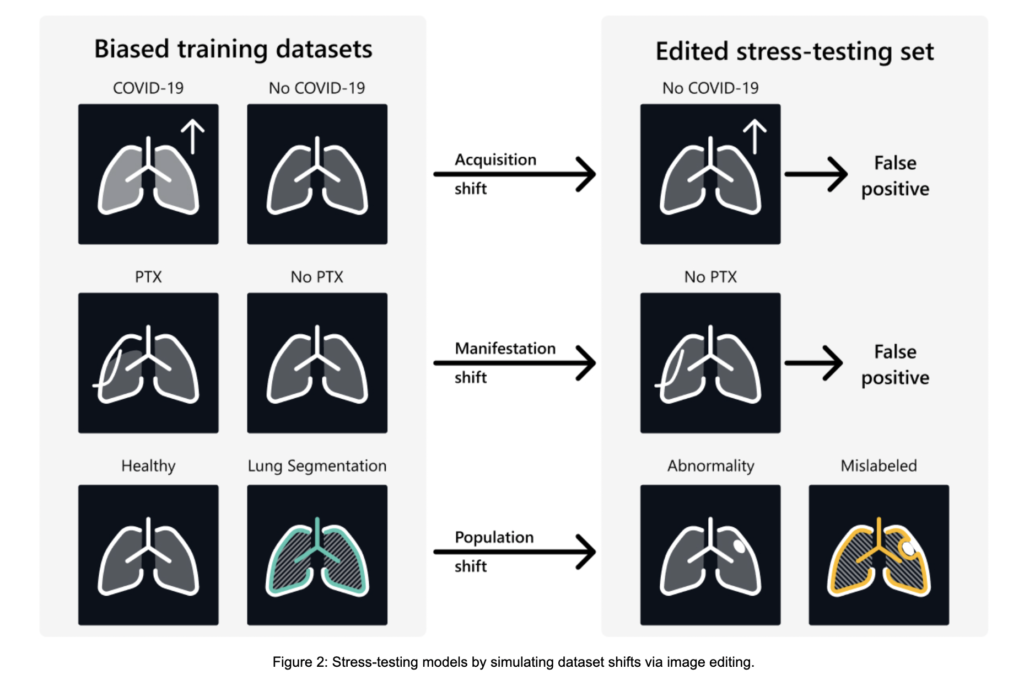
Biomedical vision models are increasingly used in clinical settings, but a significant challenge is their inability to generalize effectively due to dataset shifts—discrepancies between training data and real-world scenarios. These shifts arise from differences in image acquisition, changes in disease manifestations, and population variance. As a result, models trained on limited or biased datasets often perform poorly in real-world applications, posing a risk to patient safety. The challenge lies in developing methods to identify and address these biases before models are deployed in clinical environments, ensuring they are robust enough to handle the complexity and variability of medical data.
Current strategies to tackle dataset shifts often involve the use of synthetic data generated by deep learning models such as GANs and diffusion models. While these approaches have shown promise in simulating new scenarios, they are plagued by several limitations. Methods like LANCE and DiffEdit, which attempt to modify specific features within medical images, often introduce unintended changes, such as altering unrelated anatomical features or introducing visual artifacts. These inconsistencies reduce the reliability of these techniques in stress-testing models for real-world medical applications. For example, a single mask-based approach like DiffEdit struggles with spurious correlations, causing key features to be incorrectly altered, which limits its effectiveness.


A team of researchers from Microsoft Health Futures, the University of Edinburgh, the University of Cambridge, the University of California, and Stanford University propose RadEdit, a novel diffusion-based image-editing approach specifically designed to address the shortcomings of previous methods. RadEdit utilizes multiple image masks to precisely control which regions of a medical image are edited while preserving the integrity of surrounding areas. This multi-mask framework ensures that spurious correlations, such as the co-occurrence of chest drains and pneumothorax in chest X-rays, are avoided, maintaining the visual and structural consistency of the image. RadEdit’s ability to generate high-fidelity synthetic datasets allows it to simulate real-world dataset shifts, thereby exposing failure modes in biomedical vision models. This proposed method presents a significant contribution to stress-testing models under conditions of acquisition, manifestation, and population shifts, offering a more accurate and robust solution.

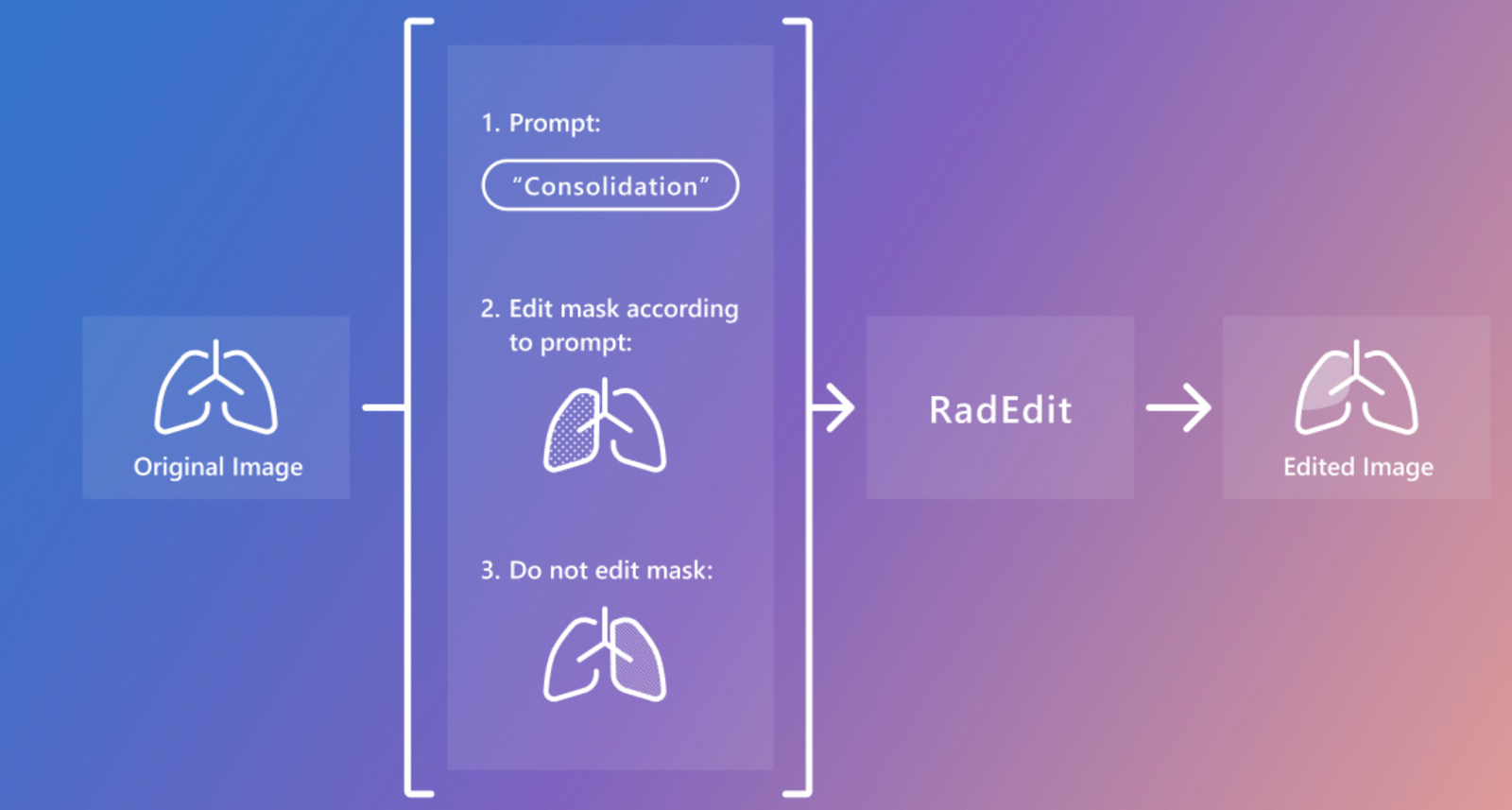
RadEdit is built upon a latent diffusion model trained on over 487,000 chest X-ray images from large datasets, including MIMIC-CXR, ChestX-ray8, and CheXpert. The system leverages dual masks—an edit mask for the regions to be modified and a keep mask for areas that should remain unaltered. This design ensures that edits are localized without disturbing other critical anatomical structures, which is crucial in medical applications. RadEdit uses the BioViL-T model, a domain-specific vision-language model for medical imaging, to assess the quality of its edits through image-text alignment scores, ensuring that synthetic images accurately represent medical conditions without introducing visual artifacts.
The evaluation of RadEdit demonstrated its effectiveness in stress-testing biomedical vision models across three dataset shift scenarios. In the acquisition shift tests, RadEdit exposed a significant performance drop in a weak COVID-19 classifier, with accuracy falling from 99.1% on biased training data to just 5.5% on synthetic test data, revealing the model’s reliance on confounding factors. For manifestation shift, when pneumothorax was edited out while retaining chest drains, the classifier’s accuracy dropped from 93.3% to 17.9%, highlighting its failure to distinguish between the disease and treatment artifacts. In the population shift scenario, RadEdit added abnormalities to healthy lung X-rays, leading to substantial decreases in segmentation model performance, particularly in Dice scores and error metrics. However, stronger models trained on diverse data showed greater resilience across all shifts, underscoring RadEdit’s ability to identify model vulnerabilities and assess robustness under various conditions.




In conclusion, RadEdit represents a groundbreaking approach to stress-testing biomedical vision models by creating realistic synthetic datasets that simulate critical dataset shifts. By leveraging multiple masks and advanced diffusion-based editing, RadEdit mitigates the limitations of prior methods, ensuring that edits are precise and artifacts are minimized. RadEdit has the potential to significantly enhance the robustness of medical AI models, improving their real-world applicability and ultimately contributing to safer and more effective healthcare systems.
Check out the Paper and Details. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 50k+ ML SubReddit.
Subscribe to the fastest-growing ML Newsletter with over 26k+ subscribers


Aswin AK is a consulting intern at MarkTechPost. He is pursuing his Dual Degree at the Indian Institute of Technology, Kharagpur. He is passionate about data science and machine learning, bringing a strong academic background and hands-on experience in solving real-life cross-domain challenges.