Large language models (LLMs) can understand and generate human-like text across various applications. However, despite their success, LLMs often need help in mathematical reasoning, especially when solving complex problems requiring logical, step-by-step thinking. This research field is evolving rapidly as AI researchers explore new methods to enhance LLMs’ capabilities in handling advanced reasoning tasks, particularly in mathematics. Improving mathematical reasoning is crucial for academic purposes and practical applications, such as AI-driven systems in scientific fields, financial modeling, and technological innovation.
Mathematical reasoning in AI is an area that presents unique challenges. While current LLMs perform well in general tasks, they need help with intricate mathematical problems that demand multi-step reasoning and logical deduction. This limitation largely stems from a need for more structured and high-quality mathematical data during the models’ pretraining. Without sufficient exposure to complex mathematical problems formatted stepwise, these models fail to break down problems into manageable parts, impacting their overall performance in tasks that require logical thinking. The lack of curated, problem-specific datasets also makes it difficult to train models in a way that would develop these skills effectively.
Existing approaches to addressing this problem involve using synthetic data to augment the training corpora for LLMs. While synthetic data generation has proven valuable in many areas of AI, including general reasoning tasks, its application in mathematical reasoning still needs to be developed. The primary issue is that existing methods of generating synthetic data often need to incorporate the detailed, step-by-step problem-solving processes necessary for improving logical reasoning. For mathematical tasks, data must be formatted to teach models how to solve problems by breaking them into sub-problems and tackling each component individually. The lack of structure in most synthetic data generation methods renders them suboptimal for improving the mathematical capabilities of LLMs.
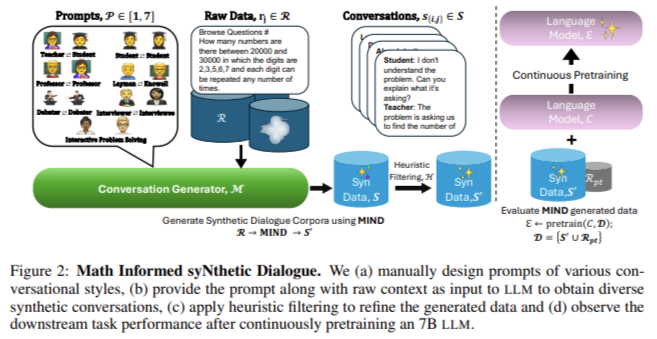
Researchers from NVIDIA, Carnegie Mellon University, and Boston University introduced a novel approach called MIND (Math Informed syNthetic Dialogue). This method generates synthetic conversations that simulate the step-by-step process of solving complex mathematical problems. The MIND technique leverages a large dataset known as OpenWebMath, which contains billions of tokens of mathematical web content. The method utilizes these web-based mathematical texts and transforms them into structured dialogues, enhancing the reasoning abilities of LLMs. MIND enables the generation of conversations in seven different styles, including settings like “Teacher-Student” and “Two Professors,” to explore various ways of presenting and explaining mathematical concepts.
The technology behind MIND works by prompting an LLM with a raw text from OpenWebMath and instructing it to break down the problem into a series of conversational turns. Each conversation style contributes to decomposing a mathematical problem into its core components, allowing the model to focus on each part in a detailed and logical manner. The researchers used multiple heuristic filters to refine the synthetic conversations, ensuring they remained relevant and accurate. Through this method, the MIND-generated dialogues retain the complexity of the original mathematical problems while providing a structured approach to reasoning that enhances the model’s ability to solve multi-step problems.
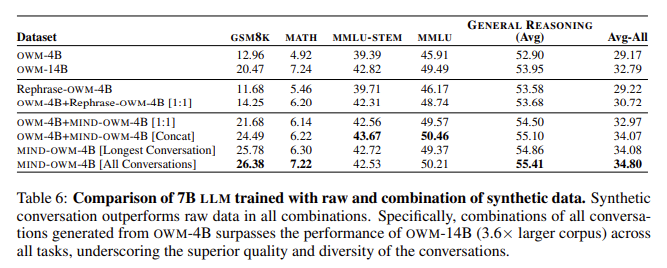
The research team’s experiments showed that LLMs trained with the MIND-generated data outperformed those trained solely on raw data. For example, models pretrained using MIND showed a 13.42% improvement in accuracy on the GSM 8K dataset, which measures the model’s ability to solve math word problems, and a 2.30% gain on the MATH dataset. Furthermore, the MIND-trained models showed superior results in specialized knowledge tasks, such as MMLU (Massive Multitask Language Understanding), with a 4.55% improvement, and MMLU-STEM, where the gain was 4.28%. These improvements are not limited to mathematical reasoning alone, as the MIND approach also boosted general reasoning performance by 2.51%, proving the broader applicability of structured conversational data for enhancing LLMs.
Key Takeaways from the Research:
- MIND-generated data resulted in a 13.42% improvement in solving math word problems (GSM 8K) and a 2.30% improvement in the MATH dataset.
- Performance gains in specialized knowledge tasks, including a 4.55% improvement on MMLU and a 4.28% gain in MMLU-STEM tasks.
- General reasoning tasks showed a 2.51% increase in performance, indicating broader applicability.
- MIND-generated dialogues provide a structured approach to problem-solving, improving LLMs’ ability to break down complex mathematical problems.
- The method scales effectively with data, offering a cost-efficient way to improve LLMs’ reasoning abilities.

In conclusion, the research presented through MIND introduces a transformative approach to improving the mathematical reasoning capabilities of large language models. By generating diverse synthetic dialogues, MIND bridges the gap left by conventional pretraining methods that rely heavily on unstructured data. The structured nature of the conversations generated by MIND provides LLMs with a framework for solving complex problems that require logical and multi-step reasoning, offering a scalable solution for enhancing AI performance in this crucial domain. The ability of MIND to integrate both raw and synthetic data further amplifies its effectiveness, as models benefit from the structured learning process while retaining the diverse information contained in raw data sources.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase Inference Engine (Promoted)
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.
