Evaluating the retrieval and reasoning capabilities of large language models (LLMs) in extremely long contexts, extending up to 1 million tokens, is a significant challenge. Efficiently processing long texts is crucial for extracting relevant information and making accurate decisions based on extensive data. This challenge is particularly relevant for real-world applications, such as legal document analysis, academic research, and business intelligence. Addressing this issue is vital for advancing AI research, enabling the development of LLMs capable of performing complex tasks in practical, long-context scenarios.
Current methods for evaluating LLMs’ long-context capabilities include various benchmarks and datasets that test models at different token lengths. Examples include the LongBench dataset, which evaluates bilingual long text comprehension in tasks ranging from 5k to 15k tokens. However, these methods have limitations, such as not adequately assessing LLMs at the 1M token level and often focusing on single retrieval tasks. Existing approaches, like the passkey testing method and the Needle In A Haystack (NIAH) test, have shown that while some models can perform well in extracting single pieces of information, they struggle with more complex tasks that require synthesizing multiple pieces of data. These limitations hinder the applicability of current methods for evaluating the true long-context comprehension and reasoning capabilities of LLMs in realistic scenarios.
A team of researchers from Shanghai AI Laboratory and Tsinghua University introduce NeedleBench, a novel framework designed to evaluate the bilingual long-context capabilities of LLMs across multiple length intervals and text depth ranges. NeedleBench consists of progressively more challenging tasks, including Single-Retrieval Task (S-RT), Multi-Retrieval Task (M-RT), and Multi-Reasoning Task (M-RS), aimed at providing a comprehensive assessment of LLMs’ abilities. The key innovation is the introduction of the Ancestral Trace Challenge (ATC), which mimics real-world long-context reasoning challenges. The ATC tests models’ capabilities to handle multi-step logical reasoning tasks. This approach represents a significant contribution to the field by offering a more rigorous and realistic evaluation of LLMs’ long-context capabilities, addressing the limitations of existing methods.
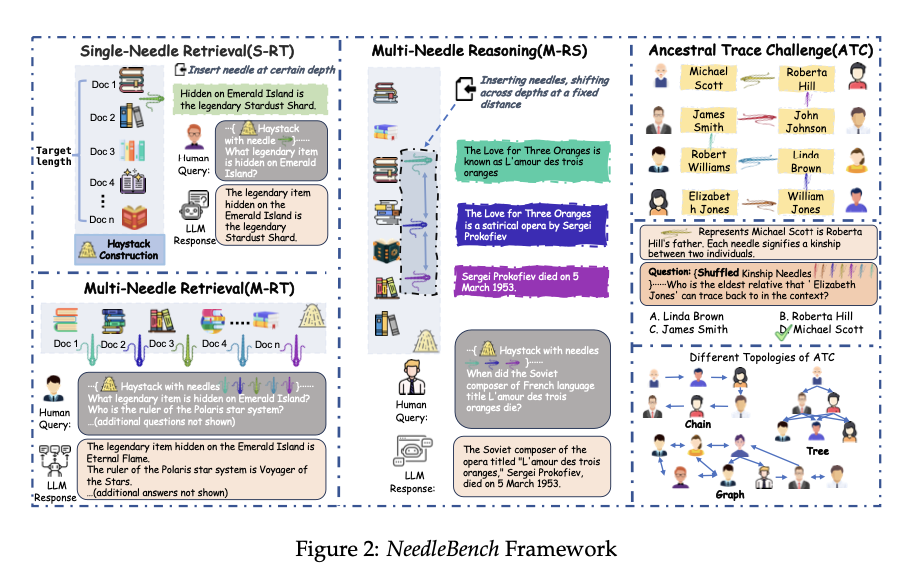
NeedleBench is designed with tasks that test models at various context lengths (4k, 8k, 32k, 128k, 200k, 1000k, and beyond) and different text depths. The dataset construction involves strategic insertion of key information (needles) at varying depths within extensive texts (haystack). For example, the Multi-Needle Reasoning Task (M-RS) uses the R4C dataset, an enhanced version of HotpotQA, translated into Chinese for bilingual evaluation. The NeedleBench framework also incorporates a fine-grained evaluation metric using Levenshtein distance to assess models’ accuracy in retrieving and reasoning over long texts. The proposed method details specific components such as buffer sizes, repetition counts, and scoring formulas, ensuring reproducibility and minimizing tokenizer discrepancies among different models.
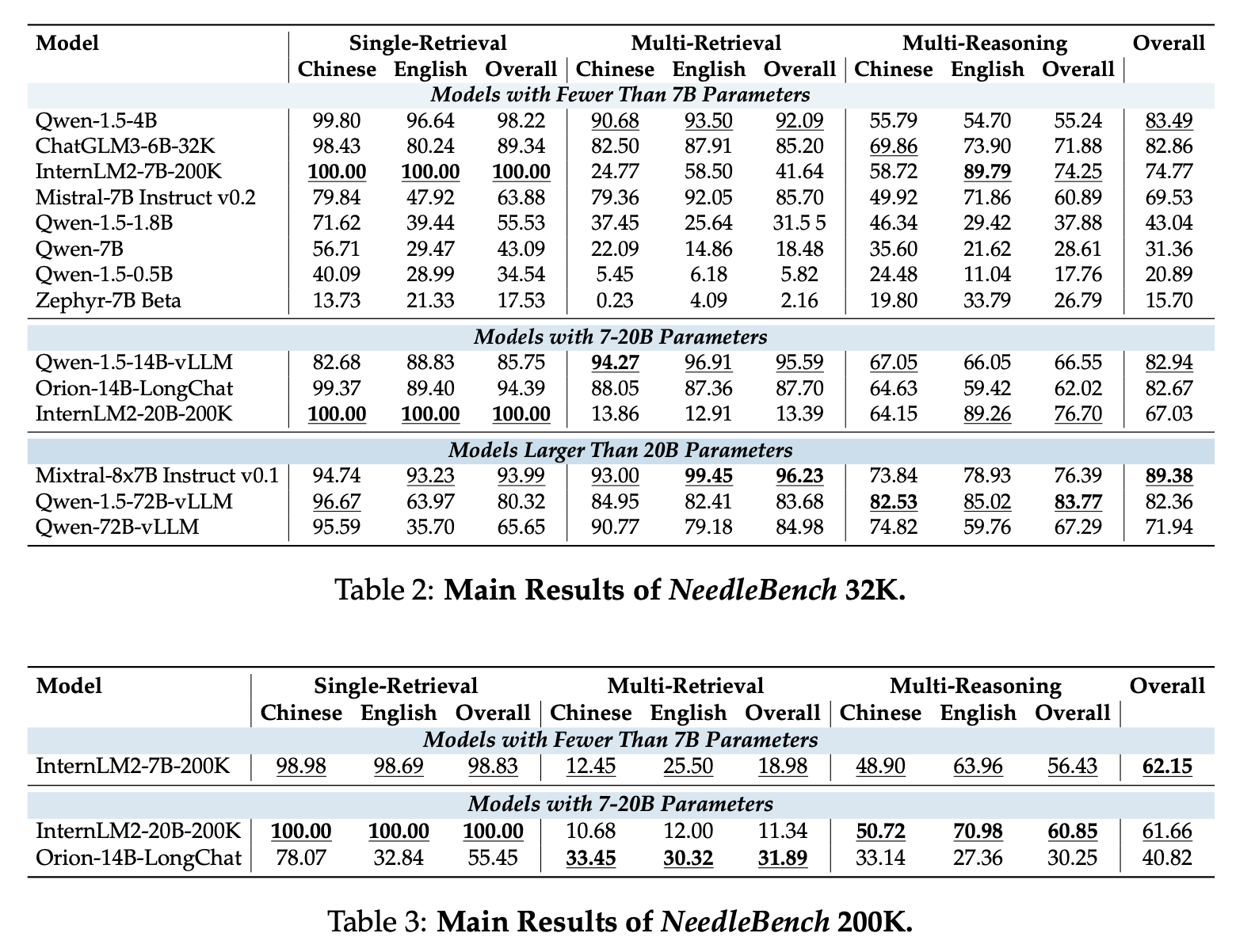
The researchers present comprehensive evaluation results of mainstream open-source LLMs on NeedleBench tasks at various token lengths. Key performance metrics include recall accuracy for retrieval tasks and reasoning accuracy for multi-step logical tasks. The results indicate significant room for improvement in current LLMs’ practical long-context applications. For example, the InternLM2-7B-200K model achieved perfect scores in Single-Retrieval tasks but showed a decline in Multi-Retrieval tasks due to overfitting. The researchers highlight that larger models, such as Qwen-1.5-72B-vLLM, generally perform better in complex reasoning tasks. A particularly important table compares the performance of different models on NeedleBench 32K, showing significant improvements in accuracy for the proposed method compared to existing baselines.
In conclusion, NeedleBench provides a novel framework for evaluating the long-context capabilities of LLMs. The NeedleBench framework, along with the Ancestral Trace Challenge, offers a comprehensive assessment of models’ abilities to handle complex retrieval and reasoning tasks in extensive texts. The contributions are significant for advancing AI research, as they address the critical challenge of long-context comprehension and reasoning, offering more accurate and efficient solutions compared to existing methods. The findings highlight the need for further improvements in LLMs to enhance their applicability in real-world long-context scenarios.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
Aswin AK is a consulting intern at MarkTechPost. He is pursuing his Dual Degree at the Indian Institute of Technology, Kharagpur. He is passionate about data science and machine learning, bringing a strong academic background and hands-on experience in solving real-life cross-domain challenges.
