Monte Carlo Simulations take the spotlight when we discuss the photorealistic rendering of natural images. Photorealistic rendering, or, in layman’s words, creating indistinguishable “clones” of actual photos, needs sampling. The most logical and prevalent approach to this is to construct individual estimators that focus on each factor and combine them using multiple importance sampling (MIS) to yield an effective mixture sampling distribution with sub-optimal variance. However, to improve accuracy, it is necessary to approximate the actual product of the factors. This simple change of strategy does wonders, especially in cases of direct illumination. The importance of neural probabilistic models is now analyzed, and discrete normalizing flow (NF) is an excellent accomplishment in revolutionizing sampling distributions. NFs can be applied to Monte Carlo rendering effectively. Considering all the significant improvements NFs bring, their expensive computations bring no surprises, hindering their adoption. This article articulates how neural probabilistic models with warp composition solve this problem.
Researchers from McGill University and Adobe Research proposed a new compositional approach for product importance sampling based on normalizing flows that combine a head warp ( represented by a neural spline flow) with a large tail warp. This study introduces a novel neural architecture based on a circular variant of rational-quadratic splines. Finally, they propose a compact integration into current practical rendering systems to achieve at-par performance with a compact model.
To fully understand this study, let us comprehend the main components of this proposal and how they make up the architecture -:
1 ) Normalizing Flows- a class of generative models that can construct arbitrary probability distributions for flexible distributions using a series of bijective transformations or warps.
2) Warps – A bijective transformation that maps one probability distribution into another. In the context of rendering, warps transform a simple base distribution into more complex target distributions.
3) Neural Warp Composition- This is the main proposal of the paper, which consists of two parts: head warp and tail warp. Head Warp is a conditional neural network that maps a uniform base distribution into a simpler intermediate one. The intermediate distribution is learned by tail warp, which transforms samples from the same to the final target distribution
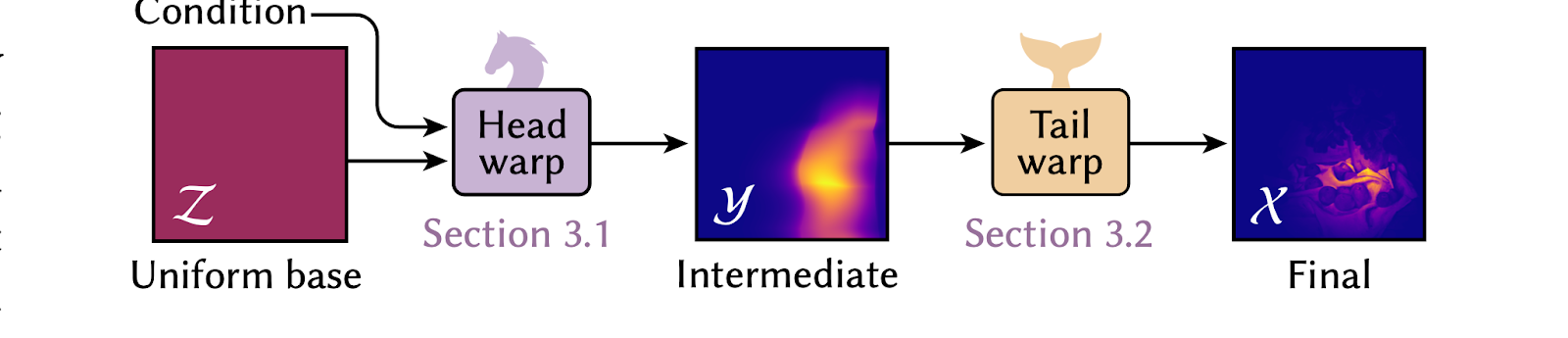
Achieving high performance in rendering means generating samples whose probability distribution is proportional to the product of an unconditional and a conditional density. The unconditional density has a complex shape, like an unshadowed environment map, whereas the latter is simple, like BDRF. Upon analysis, researchers realized that the process could be broken into two parts instead of using one complex conditional NF to achieve the target probability. Firstly, distribution is fed using a compact conditional head NF (instead of a complex NF), and then its output is fed to a complex unconditional tail warp.
Neural Warp Composition was integrated into Mitsuba 3’s, a well-known wavefront path-tracing renderer, to test the efficacy. Its performance was measured against major benchmarks at equal rendering time and equal sample count with Mean Squared Error as the performance metric.
Neural Warp Composition outperformed traditional methods in emitter sampling by effectively capturing lighting variations over surfaces; even at shallow resolution, proposed histograms gave quality final product distributions at a fraction of the inference cost. The model for microfacet materials outperformed traditional methods like MIS and RIS in the case of fixed roughness. It could not surpass RIS for varying roughness, but when a new experiment was conducted where researchers combined neural warp with BRDF sampling through MIS, further noise was canceled.
While Neural Warps significantly reduced variance in final product distributions when minimizing costs, a few challenges persisted, like the model struggled when product distributions were highly concentrated in small regions. It promises future work, and the researchers leave with a promise to incorporate end-to-end training of both material and sampling models and improve sampling efficiency for more complex materials.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit
[Upcoming Event- Oct 17 202] RetrieveX – The GenAI Data Retrieval Conference (Promoted)
Adeeba Alam Ansari is currently pursuing her Dual Degree at the Indian Institute of Technology (IIT) Kharagpur, earning a B.Tech in Industrial Engineering and an M.Tech in Financial Engineering. With a keen interest in machine learning and artificial intelligence, she is an avid reader and an inquisitive individual. Adeeba firmly believes in the power of technology to empower society and promote welfare through innovative solutions driven by empathy and a deep understanding of real-world challenges.
