
The rise of Transformer-based models has significantly advanced the field of natural language processing. However, the training of these models is often computationally intensive, requiring substantial resources and time. This research addresses the issue of improving the training efficiency of Transformer models without compromising their performance. Specifically, it seeks to explore whether the benefits of normalization, often applied as a separate component, can be integrated throughout the Transformer architecture in a more cohesive manner.
Researchers from NVIDIA propose a novel architecture called the Normalized Transformer (nGPT), which incorporates representation learning on the hypersphere. In this approach, all vectors involved in the embeddings, MLP, attention matrices, and hidden states are normalized to unit norm. This normalization allows the input tokens to move across the surface of a hypersphere, with each model layer incrementally contributing towards the final output prediction. By conceptualizing the entire transformation process as movement on a hypersphere, the researchers aim to make the training process both faster and more stable. The nGPT model reportedly reduces the number of training steps required by a factor of 4 to 20, depending on the sequence length.
The structure of the Normalized Transformer revolves around a systematic normalization process. All embeddings, as well as attention and MLP matrices, are constrained to lie on a hypersphere, ensuring uniform representation across all network layers. Specifically, the embeddings and the outputs from the attention mechanism and MLP are normalized, treating each vector operation as a dot product representing cosine similarity. Furthermore, instead of using traditional weight decay and additional normalization layers like LayerNorm or RMSNorm, the authors introduce learnable scaling parameters to control the impact of normalization. The normalization and optimization process in nGPT is designed as a variable-metric optimization on the hypersphere, with the update steps controlled by learnable eigen learning rates that adaptively adjust each layer’s contributions.
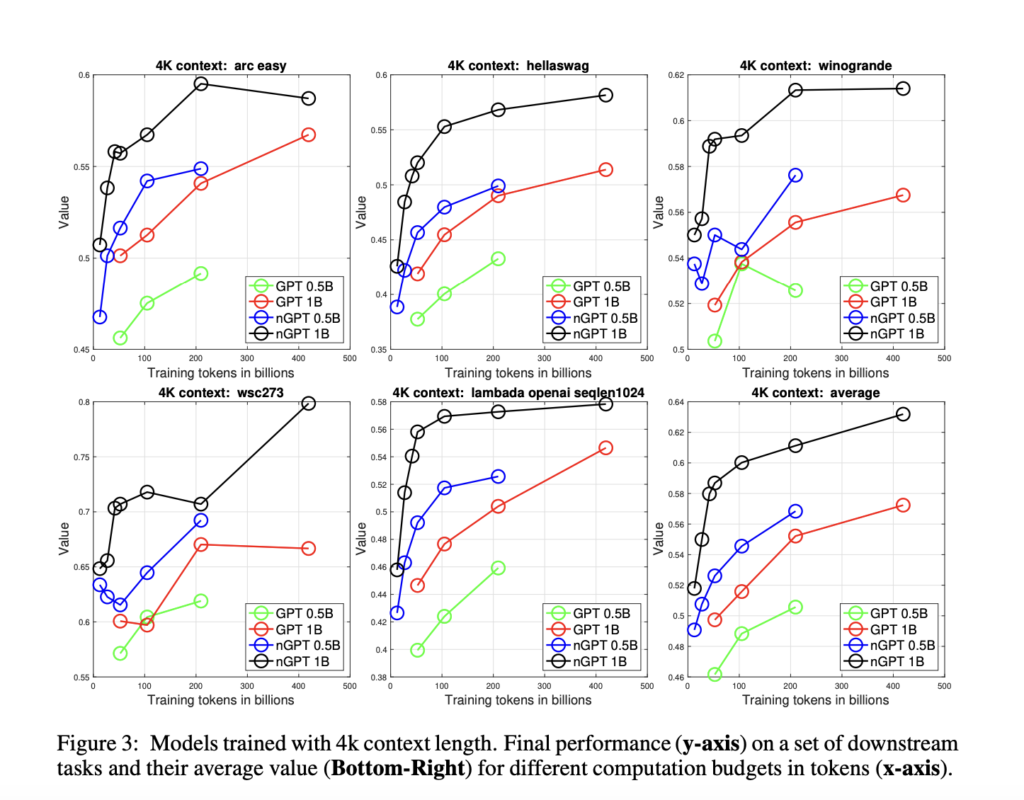
The results of the research are compelling. The authors conducted experiments using the OpenWebText dataset, training both a baseline GPT model and the new nGPT model. For the same training budget, nGPT demonstrated a significant reduction in validation loss compared to GPT, particularly at longer context lengths. For instance, with a context length of 4k tokens, nGPT achieved the same validation loss as GPT with only one-tenth of the iterations. The experiments also confirmed that nGPT consistently outperformed the baseline GPT on a range of downstream tasks, providing not only faster convergence but also improved generalization. The introduction of hyperspherical representation learning led to better embedding separability, which correlated with higher accuracy on benchmark tests.
In conclusion, the Normalized Transformer (nGPT) presents a significant advancement in the efficient training of large language models. By unifying the findings of previous studies on normalization and embedding representation, the authors created a model that is more efficient in terms of computational resources while still maintaining high performance. The approach of utilizing the hypersphere as the foundation for all transformations allows for more stable and consistent training, potentially paving the way for future optimizations in the architecture of Transformer models. The researchers suggest that this method could be extended to more complex encoder-decoder architectures and other hybrid model frameworks.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit.


Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.