Graph neural networks (GNNs) have emerged as powerful tools for capturing complex interactions in real-world entities and finding applications across various business domains. These networks excel at generating effective graph entity embeddings by encoding both node features and structural insights, making them invaluable for numerous downstream tasks. GNNs have succeeded in node-level financial fraud detection, link-level recommendation systems, and graph-level bioinformatics applications. However, the widespread adoption of GNNs faces significant challenges. Privacy regulations, intensifying business competition, and scalability issues in billion-level graph learning have raised concerns about direct data sharing. These factors complicate centralized data storage and model training on a single machine, necessitating new approaches to harness the power of GNNs while addressing these pressing concerns.
Federated Graph Learning (FGL) has been proposed as a solution to enable collaborative GNN training across multiple local systems while addressing privacy and scalability concerns. However, existing FGL benchmarks, such as FS-G and FedGraphNN, have significant limitations. These benchmarks are restricted to a narrow range of application domains, primarily focusing on citation networks and recommendation systems. They also lack the inclusion of recent state-of-the-art FGL methods, particularly those developed in 2023 and 2024. Also, current benchmarks fall short in simulating federated data strategies that account for graph properties, providing inadequate support for various graph-based downstream tasks, and offering limited evaluation perspectives.
The absence of a comprehensive benchmark for fair comparison hinders the development of FGL, despite growing research interest. The field faces challenges in addressing the diversity of graph-based downstream tasks (node, link, and graph levels), accommodating unique graph characteristics (feature, label, and topology), and managing the complexity of FGL evaluation (effectiveness, robustness, and efficiency). These factors collectively impede a thorough understanding of the current FGL landscape, highlighting the urgent need for a standardized and comprehensive benchmark to drive progress in this promising field.
Researchers from the Beijing Institute of Technology, Sun Yat-sen University, Peking University, and Beijing Jiaotong University present OpenFGL, a comprehensive benchmark proposed to address the limitations of existing FGL frameworks. This innovative platform integrates two commonly used FGL scenarios, 38 datasets spanning 16 application domains, 8 graph-specific distributed data simulation strategies, 18 state-of-the-art algorithms, and 5 graph-based downstream tasks. OpenFGL implements these components with a unified API, facilitating fair comparisons and future development in a user-friendly manner. The benchmark provides a thorough evaluation of existing FGL algorithms, offering valuable insights into effectiveness, robustness, and efficiency. OpenFGL emphasizes quantifying statistics in distributed graphs to formally define graph-based federated heterogeneity and highlights the potential of personalized, multi-client collaboration and privacy-preserving techniques. Also, it encourages FGL developers to prioritize algorithmic scalability and propose innovative federated collaborative paradigms to improve efficiency, especially for industry-scale datasets.

Problem formulation
OpenFGL benchmark focuses on two representative scenarios in federated graph learning (FGL): Graph-FL and Subgraph-FL. In Graph-FL, each client considers entire graphs as data samples, while in Subgraph-FL, nodes within a subgraph are treated as samples. The FGL system comprises K clients, with each client k managing a private dataset D(k) containing graph samples G(k)_i. The number of samples, NT, varies based on the scenario: in Graph-FL, it represents the number of graph samples, while in Subgraph-FL, NT is always 1.
The training process in OpenFGL follows a four-step communication round, illustrated using the FedAvg algorithm:
1. Receive Message: Clients initialize local models with the server’s model.
2. Local Update: Clients train on private data to optimize task-specific objectives.
3. Upload Message: Clients send updated models and sample counts to the server.
4. Global Aggregation: The server combines client models weighted by sample counts.
This architecture enables collaborative learning across distributed graph data while maintaining data privacy and addressing the challenges of federated learning in graph-based scenarios.
OpenFGL focuses on two prevalent FGL scenarios: Graph-FL and Subgraph-FL. In Graph-FL, clients treat entire graphs as data samples, collaborating to develop powerful models while maintaining data privacy. This scenario is particularly relevant in AI4Science applications like drug discovery. Subgraph-FL, on the other hand, addresses real-world applications such as node-level fraud detection in finance and link-level recommendation systems. In this scenario, clients consider their data as subgraphs of a larger global graph, using nodes and edges as training samples.
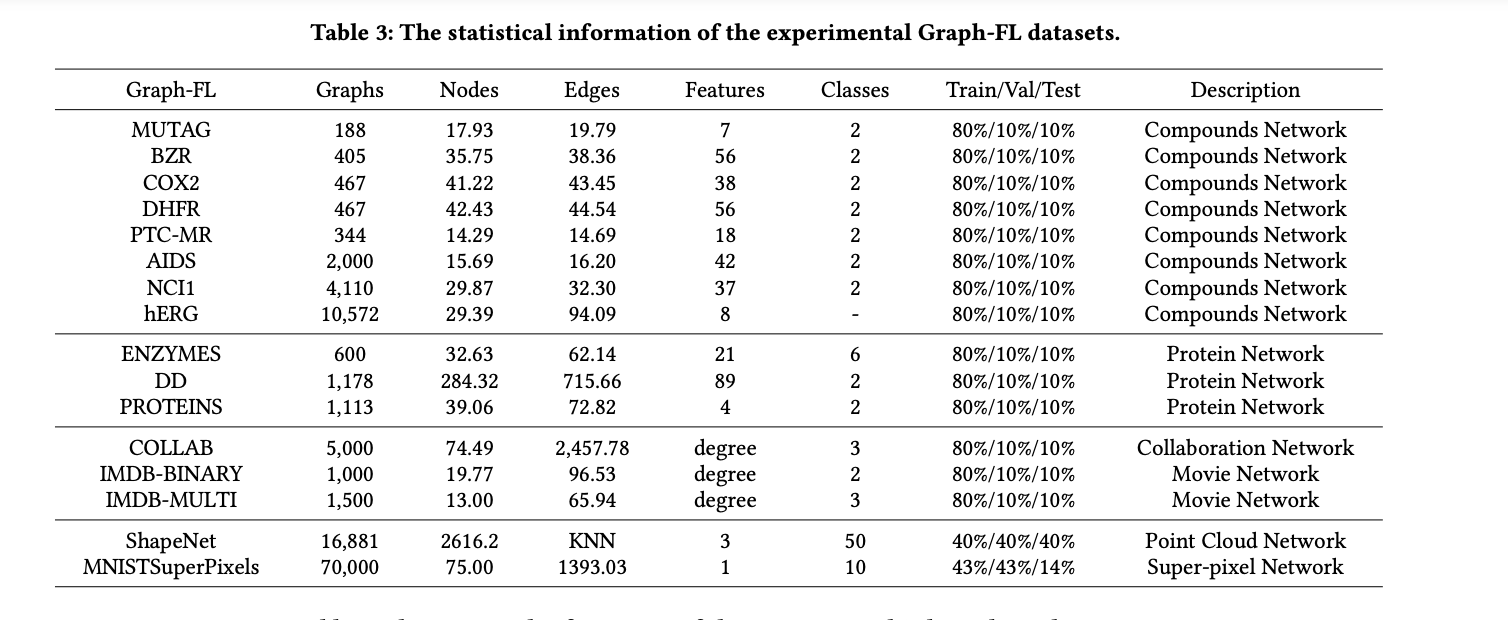
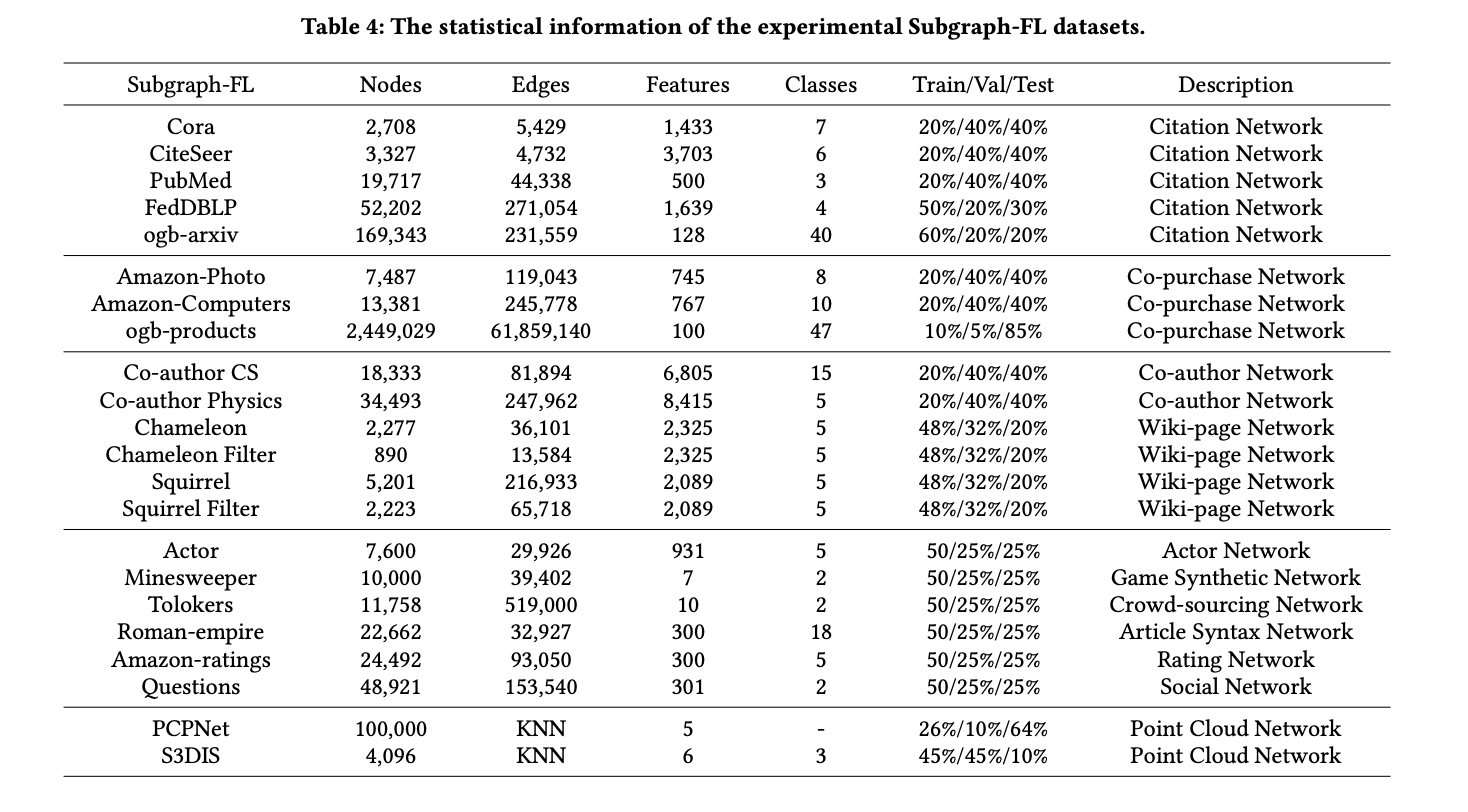
The benchmark incorporates a diverse collection of public datasets from various domains to evaluate FGL algorithms comprehensively. For Graph-FL, experiments are conducted on compound networks, protein networks, collaboration networks, movie networks, super-pixel networks, and point cloud networks. Subgraph-FL experiments utilize citation networks, co-purchase networks, co-author networks, wiki-page networks, actor networks, game synthetic networks, crowd-sourcing networks, article syntax networks, rating networks, social networks, and point cloud networks.
OpenFGL introduces eight federated data simulation strategies to address the challenge of acquiring distributed graphs. These strategies include Feature Distribution Skew, Label Distribution Skew, Cross-Domain Data Skew, Topology Shift (for Graph-FL), and various community-based splits for Subgraph-FL. These approaches simulate realistic federated scenarios while maintaining controllable heterogeneity across clients, enabling a thorough evaluation of FGL algorithms’ adaptability and robustness.
OpenFGL integrates a diverse range of GNN backbones to provide a broad spectrum of graph learning paradigms on the client side. Graph-FL, implements various well-designed polling strategies based on the Graph Isomorphism Network (GIN), including TopKPooling, SAGPooling, EdgePooling, and PANPooling, along with weight-free MeanPooling. For Subgraph-FL, OpenFGL includes prevalent models such as GCN, GAT, GraphSAGE, SGC, and GCNII.
The benchmark incorporates a comprehensive set of federated learning algorithms, ranging from traditional computer vision-based methods to specialized FGL algorithms. These include FedAvg, FedProx, Scaffold, MOON, FedDC, FedProto, FedNH, and FedTGP from CV-based FL, as well as GCFL+ and FedStar for Graph-FL, and FedSage+, Fed-PUB, FedGTA, FGSSL, FedGL, AdaFGL, FGGP, FedDEP, and FedTAD for Subgraph-FL.
OpenFGL advocates for in-depth data analysis to understand FGL heterogeneity, focusing on Feature KL Divergence, Label Distribution (including homophily metrics), and Topology Statistics. The benchmark evaluates effectiveness using various metrics for different tasks, such as Accuracy and F1 score for classification, MSE for regression, AP and AUC-ROC for link prediction, and clustering accuracy for node clustering.
To assess robustness, OpenFGL examines FGL algorithms under various challenging scenarios, including data noise, sparsity, limited client communication, generalization to complex applications, and privacy preservation using Differential Privacy. Efficiency evaluation considers both theoretical algorithm complexity and practical aspects like communication cost and running time.
OpenFGL conducts a comprehensive investigation of FGL algorithms, addressing key questions related to effectiveness, robustness, and efficiency. The study aims to provide insights into the following areas:
Effectiveness:
1. The advantages of federated collaboration compared to local training.
2. Performance comparison between FGL algorithms and federated implementations of GNNs in Graph-FL and Subgraph-FL scenarios.
Robustness:
3. Algorithm performance under local noise and sparsity conditions affecting features, labels, and edges.
4. Impact of low client participation rates on FGL algorithm performance.
5. Generalization capabilities of FGL algorithms across various graph-specific distributed scenarios.
6. Support for differential privacy (DP) protection in FGL algorithms.
Efficiency:
7. Theoretical algorithm complexity of FGL methods.
8. Practical running efficiency of FGL algorithms.
These questions are designed to provide a comprehensive evaluation of FGL algorithms, covering their performance, adaptability to challenging conditions, and computational efficiency. The results of this extensive analysis offer valuable insights for researchers and practitioners in the field of federated graph learning, guiding future developments and applications of these algorithms in real-world scenarios.
The OpenFGL benchmark study revealed significant insights into the effectiveness of FGL algorithms across Graph-FL and Subgraph-FL scenarios. In the Graph-FL scenario, researchers found that federated collaboration yielded more substantial benefits for larger-scale datasets, utilizing abundant data sources. However, existing Graph-FL algorithms showed room for improvement, particularly in single-source domains and scenarios with limited data semantics. The Subgraph-FL scenario demonstrated more advanced development, with numerous state-of-the-art baselines available. The study highlighted that the positive impact of federated collaboration depends on uniform distribution of node features, labels, and topology across clients. Also, FedTAD and AdaFGL emerged as top performers in most Subgraph-FL cases. The research emphasized the need for Subgraph-FL algorithms to address real-world deployment complexities, especially in large-scale scenarios and graph-specific federated heterogeneity challenges.
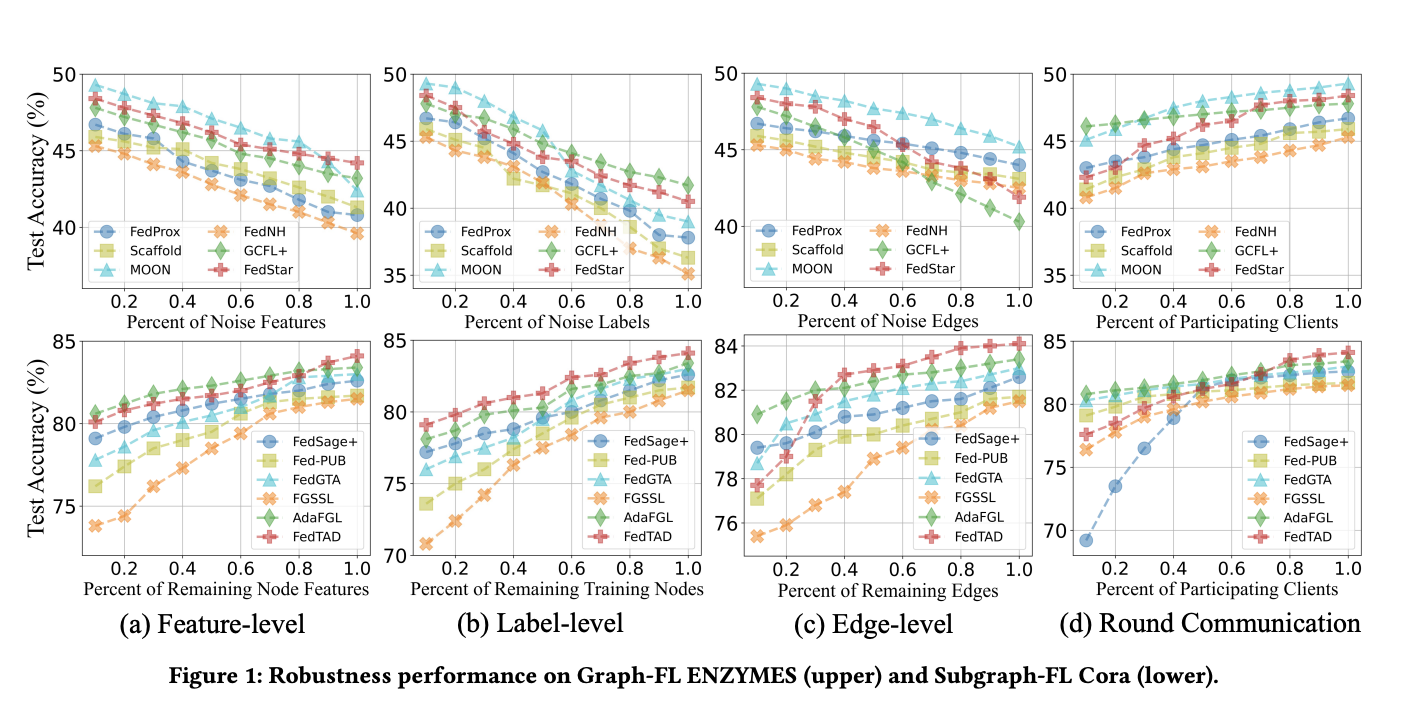
The OpenFGL benchmark also conducted a comprehensive robustness analysis of FGL algorithms, examining their performance under various challenging conditions. In local noise scenarios, FGL algorithms showed high sensitivity to edge noise compared to topology-agnostic FL algorithms, while demonstrating superior robustness under feature and label noise. The study revealed that personalized strategies are crucial for addressing noise scenarios, though they fall slightly short in handling edge noise.

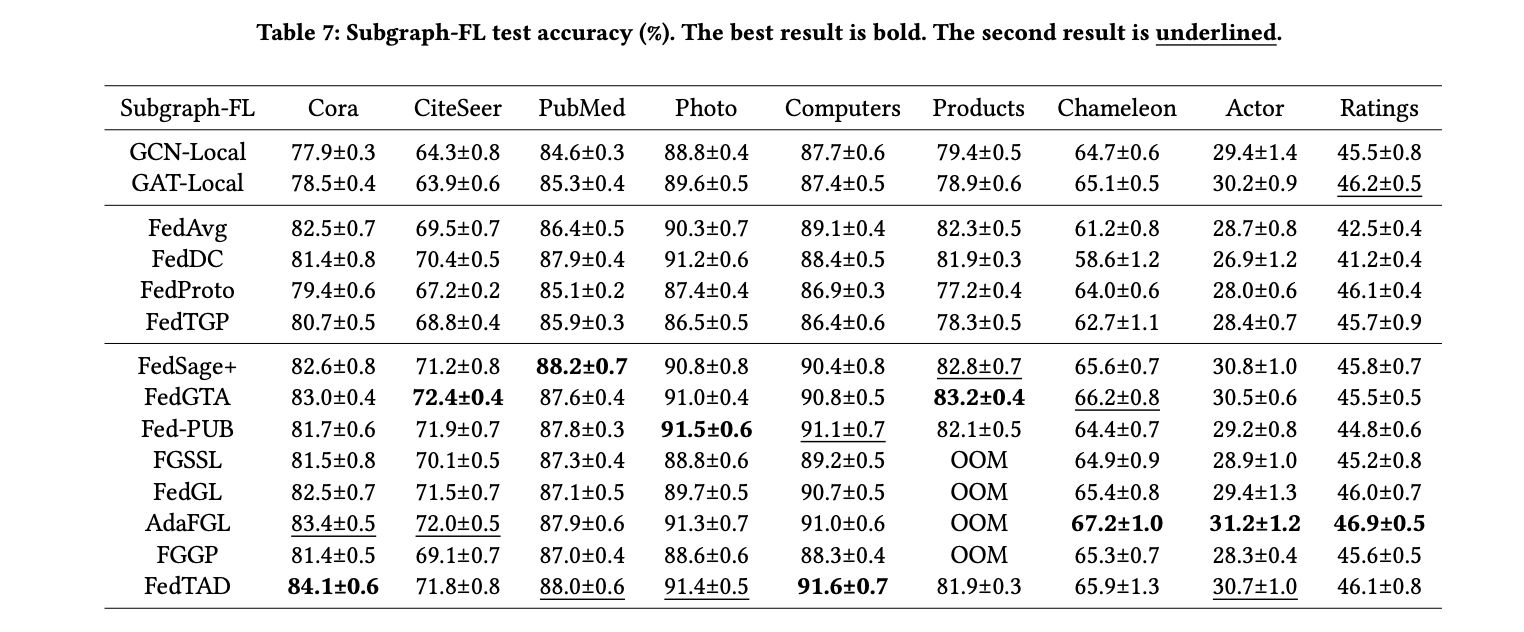
For local sparsity, algorithms leveraging multi-client collaboration, such as FedSage+, AdaFGL, and FedTAD, demonstrated better robustness, particularly when combined with topology mining techniques. In low client participation scenarios, FGL algorithms that rely less on server messages and focus on well-designed local training mechanisms or customized global messages for each client performed better.
The generalization capabilities of FGL algorithms varied across different data simulations, with client-specific designs showing potential drawbacks in scenarios aiming for generalization. The study also examined privacy preservation using DP, revealing a trade-off between predictive performance and privacy protection. Overall, the robustness analysis highlighted the importance of multi-client collaboration, personalized strategies, and careful consideration of privacy-preserving techniques in FGL algorithm design.
OpenFGL benchmark conducted a thorough analysis of the theoretical algorithm complexity for various FL and FGL algorithms. This analysis covered client memory, server memory, inference memory, client time, server time, and inference time complexities. The study revealed that the dominating complexity term for most algorithms is O(Lmf) or O(kmf), where L is the number of layers, k is the number of feature propagation steps, m is the number of edges, and f is the feature dimension.
Key findings from the complexity analysis include:
- Scalability remains a challenge for FGL algorithms, especially in billion-level scenarios, despite the distributed paradigm.
- Many recent FGL approaches focus on well-designed client-side updates, introducing additional computational overhead for local training. Examples include contrastive learning (CL) and ensemble learning techniques.
- Some methods, like FedSage+, Fed-PUB, and FedGTA, exchange additional information during communication, leading to varying time-space complexities based on their specific designs.
- Server-side optimization strategies, such as those employed by FedGL and FedTAD, show potential for improving federated training but may incur additional computational costs.
- Prototype-based FL methods (e.g., FedProto, FedNH, FedTGP) reduce communication complexity by exchanging class-specific embeddings instead of full model weights.
The OpenFGL benchmark also conducted an efficiency evaluation of FGL algorithms, focusing on practical aspects such as communication costs and running time. The study revealed several key findings:
- Prototype-based methods, including FedProto, FedTGP, and FGGP, demonstrated significant advantages in reducing communication costs. These algorithms transmit prototype representations instead of full model weights, leading to more efficient data transfer. However, they often require additional computation on either the client or server side to maintain performance, which can negate their time efficiency advantages.
- Cross-client collaborative methods, such as FedGL and FedSage+, faced challenges in deployment efficiency. The added delays resulting from inter-client communication and synchronization reduced their overall performance in terms of running time.
- Decoupled approaches, exemplified by AdaFGL, showed significant efficiency advantages. These methods aim to maximize local computational capacity while minimizing communication costs, striking a balance between performance and efficiency.
Based on these observations, the study concluded that FGL algorithms leveraging prototypes and decoupled techniques (i.e., multi-client collaboration followed by local updates) demonstrate substantial potential for applications with stringent efficiency requirements. This insight highlights the importance of balancing communication efficiency with computational load distribution in the design of FGL algorithms for real-world deployments.
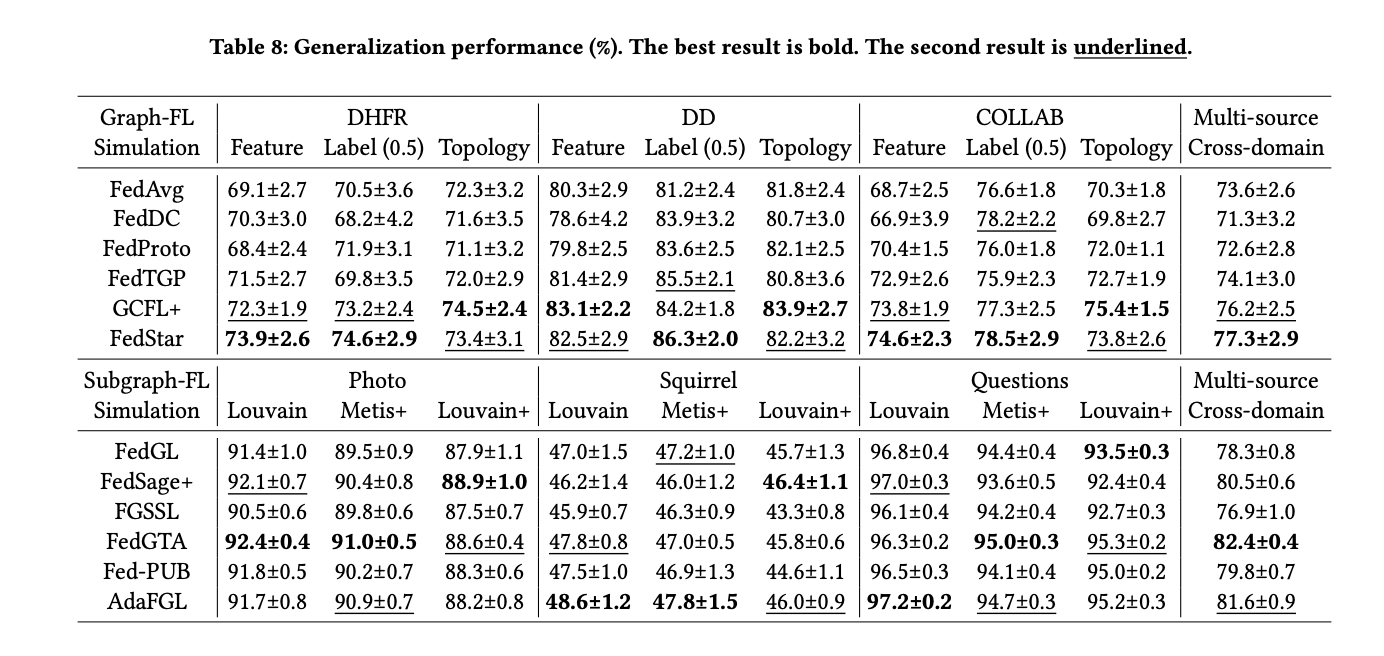
OpenFGL benchmark conducted a comprehensive evaluation of FGL algorithms, focusing on their effectiveness, robustness, and efficiency across various scenarios. In the Graph-FL scenario, federated collaboration demonstrated significant benefits, particularly for larger-scale datasets with abundant data sources. However, existing Graph-FL algorithms showed room for improvement in single-source domains and scenarios with limited data semantics. The Subgraph-FL scenario exhibited more advanced development, with numerous state-of-the-art baselines available. The study revealed that the positive impact of federated collaboration depends on the uniform distribution of node features, labels, and topology across clients. Also, FedTAD and AdaFGL emerged as top performers in most Subgraph-FL cases, highlighting the potential of these algorithms for real-world applications.

The efficiency evaluation of FGL algorithms revealed significant insights into their practical performance. Prototype-based methods like FedProto, FedTGP, and FGGP demonstrated notable advantages in reducing communication costs by transmitting prototype representations instead of full model weights. However, these methods often required additional computation on either the client or server side to maintain performance, which negated their time efficiency advantages. Cross-client collaborative approaches, such as FedGL and FedSage+, faced challenges in deployment efficiency due to added delays from inter-client communication and synchronization. In contrast, decoupled approaches like AdaFGL showed significant efficiency advantages by maximizing local computational capacity while minimizing communication costs. These findings suggest that FGL algorithms leveraging prototypes and decoupled techniques have substantial potential for applications with stringent efficiency requirements.
This study presents OpenFGL benchmark providing a comprehensive evaluation of FGL algorithms, revealing both promising advancements and significant challenges in real-world deployments. The study highlighted several key areas for future research and development in FGL. Quantifying distributed graphs and addressing FGL heterogeneity is crucial for improving effectiveness. The complex interplay of node features, labels, and topology in graph data necessitates more sophisticated methods for describing and handling graph-based heterogeneity challenges. Personalized FGL techniques and multi-client collaboration emerge as promising approaches to enhance robustness, particularly in scenarios involving client-specific noise, low participation rates, and data sparsity. Privacy preservation remains a critical concern, with current FGL algorithms potentially compromising privacy in pursuit of performance. Future research should focus on developing algorithms with stricter privacy requirements and exploring advanced privacy-preserving technologies. Finally, to address efficiency challenges, decoupled and scalable FGL approaches are needed to handle large-scale datasets and reduce communication delays. The field of FGL is still evolving, with numerous research opportunities across various graph types and learning paradigms. Continued enhancements to benchmarks like OpenFGL will be essential in supporting future research prospects and advancing the state-of-the-art in federated graph learning.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and LinkedIn. Join our Telegram Channel.
If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.
