
Designing autonomous agents that can navigate complex web environments raises many challenges, in particular when such agents incorporate both textual and visual information. More classically, agents have limited capability since they are confined to synthetic, text-based environments with well-engineered reward signals, which restricts their applications to real-world web navigation tasks. A central challenge is that enabling a generally capable agent to interpret multimodal content—consisting of visual and textual inputs—without explicit feedback signals remains one of the hardest problems in AI. These agents will also have to learn and dynamically adapt to the real world of ever-changing online environments, which in many cases will need their continuous optimization and self-improvement for various web interfaces and navigation tasks.
Existing methods for web navigation rely on large language models such as GPT-4o or other closed-source multimodal models. While these are performing well in structured and text-only environments, their resilience in a complex real-world scenario remains low. Only a few of these, like WebVoyager and VisualWebArena, extend these models to multimodal settings by considering screenshots and texts, but they still rely on closed-source models and synthetic training settings. Due to limited multi-modal perception and lack of visual grounding for underlying representation, these models cannot generalize outside the controlled environment. Another limitation of the existing approaches is their dependence on well-defined reward signals that are mostly lacking in real-world tasks. While open-source vision-language models have become increasingly approachable, such as BLIP-2-T5 and LLaVA, shallow contextual understandings make them unsuitable for complex web navigation tasks. They are limited from application to unsupervised learning in real-world, multimodal scenarios.
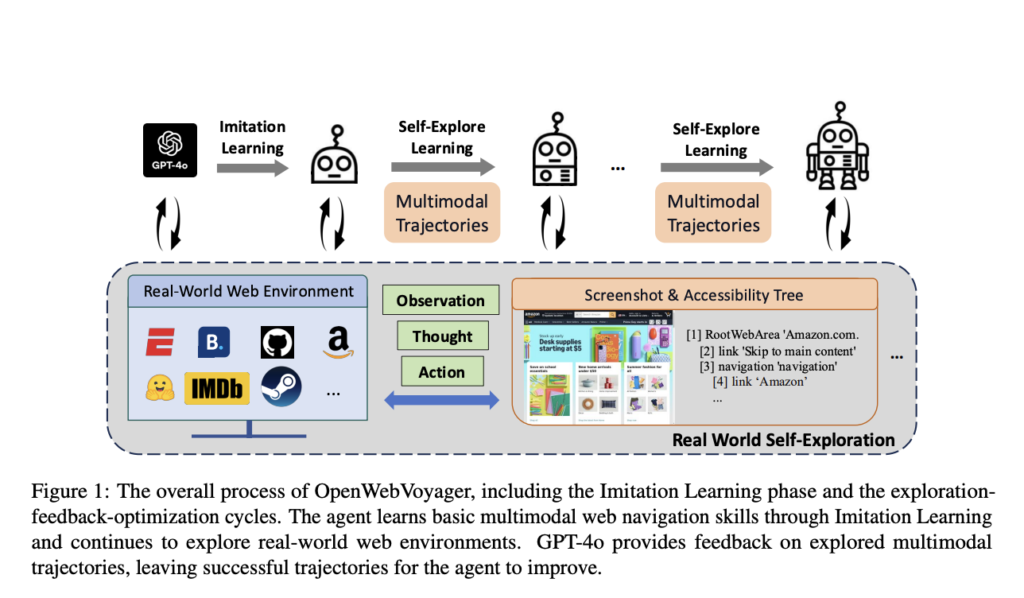
Researchers from Zhejiang University, Tencent AI Lab, and Westlake University introduce OpenWebVoyager, an open-source framework that fosters continuous, self-optimizing learning cycles in real-world web environments. Suitable local skill builders take the imitation learning (IL) in an iterative feedback loop where agents, by imitating the demonstrations of interactions with web pages, learn basic navigation skills first, after which their performances can be improved further by exploring new tasks, gathering feedback, and optimizing based on successful trajectories. With a vision-language model backbone, the Idefics2-8b-instruct, OpenWebVoyager can process images and text, allowing it to better understand real-world scenarios. The framework self-improves in an exploration-feedback-optimization cycle where GPT-4o continuously evaluates each trajectory concerning its correctness, hence updating the agent iteratively according to its performance. This, therefore, allows independent learning and optimization, moving one step further toward the scalability and adaptability of autonomous web agents.

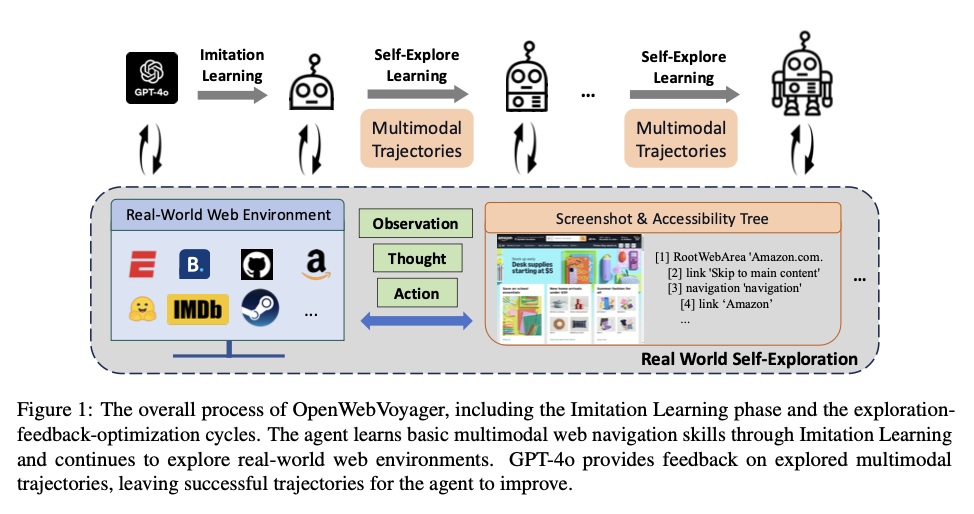
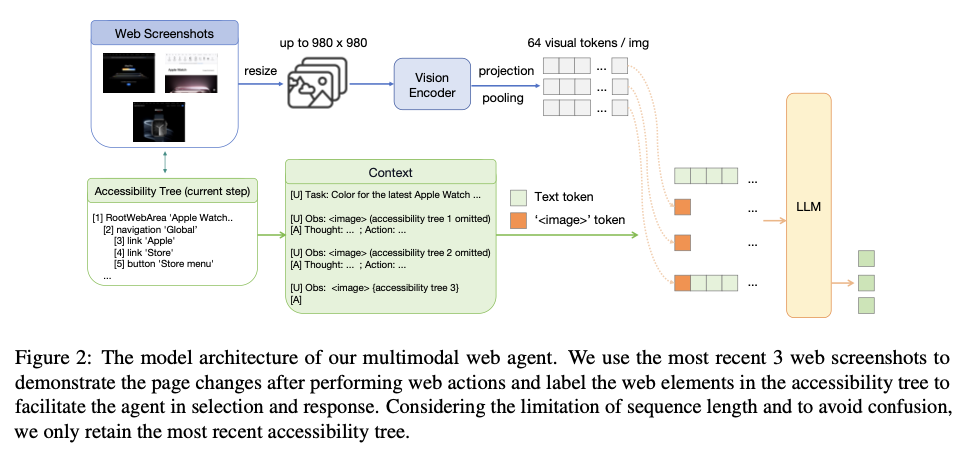
For implementation, OpenWebVoyager employed Idefics2-8b-instruct, which is an optimized model for handling textual and visual data. In the initial imitation learning phase, tasks were accumulated from 48 websites related to diversified domains of e-commerce, travel, and news with 1516 task-specific queries. Its training data consists of multimodal web trajectories with basic operations instructions that guide the agent. OpenWebVoyager uses the complementary input of accessibility trees and screenshots in multimodal ways to execute complex page layouts after going through an iterative optimization cycle. Each iteration consists of sampling new queries, trajectory success checks, and retention of successful trajectories for improvement of the model. Such a self-instructional method allows OpenWebVoyager to reach all the variable visual elements well and make operational decisions based on dynamical multimodal web page features. In addition, the model of OpenWebVoyager processes up to three screenshots per task, ensuring that it does a more complete job of visual-textual grounding in effectively carrying out those tasks.

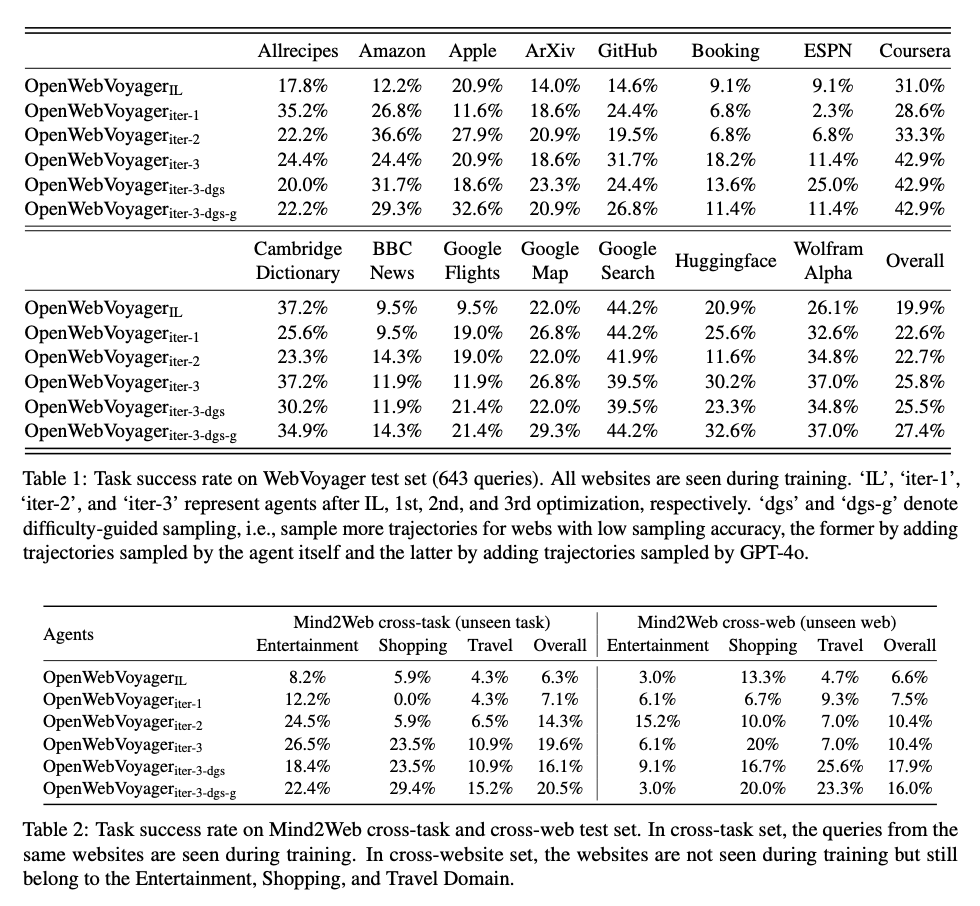
The large success rate improvement by OpenWebVoyager in several web navigation benchmarks shows rapid growth through the iterative cycles. Starting with a 19.9% success rate after the imitation learning phase, the performance of the agent has gone up to 25.8% after three optimization cycles on the WebVoyager test set. During evaluation tests on unseen tasks and domains with the Mind2Web cross-task and cross-website sets, the agent improves baseline success rates from 6.3% to 19.6% on previously encountered domains, while its success rate increases by almost 4% on the new sites. It is these improvements over the baselines that underlined the effectiveness of the approach in OpenWebVoyager, through which the agent develops its web navigation capabilities with sustained accuracy and scalability across diverse web situations.

In conclusion, OpenWebVoyager represents a breakthrough in multimodal web navigation by creating an adaptable, self-optimizing framework that improves itself over iterative cycles. By combining imitation learning with exploration and automated feedback, OpenWebVoyager’s approach advances the scope of autonomous web agents, allowing for scalability across diverse domains without extensive retraining. This innovative framework holds the potential to improve real-world web navigation in fields ranging from e-commerce to information retrieval, marking a significant stride toward self-sufficient, multimodal AI agents in dynamic online environments.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[Sponsorship Opportunity with us] Promote Your Research/Product/Webinar with 1Million+ Monthly Readers and 500k+ Community Members


Aswin AK is a consulting intern at MarkTechPost. He is pursuing his Dual Degree at the Indian Institute of Technology, Kharagpur. He is passionate about data science and machine learning, bringing a strong academic background and hands-on experience in solving real-life cross-domain challenges.