Large Language Models (LLMs) have advanced natural language processing tasks significantly. Recently, using LLMs for physical world planning tasks has shown promise. However, LLMs, primarily autoregressive models, often fail to understand the real world, leading to hallucinatory actions and trial-and-error behavior. Unlike LLMs, humans utilize global task knowledge and local state knowledge to mentally rehearse and execute tasks efficiently, avoiding blind trial-and-error and confusion during the planning and execution stages.
Existing work in LLM-based agent systems focuses on agent planning, external tool utilization, and code generation, often fine-tuning open-source LLMs. These approaches may lead to trial-and-error actions due to a lack of environmental cognition. Knowledge-augmented agent planning, using pre-trained knowledge or structured prompts, faces challenges in transferring across tasks.
Inspired by the human approach to planning, researchers from Zhejiang University – Ant Group Joint Laboratory of Knowledge Graph, National University of Singapore, and Alibaba Group developed a parametric World Knowledge Model (WKM) for agent planning. WKM is built on knowledge from both expert and explored trajectories. The agent model synthesizes task knowledge by comparing these trajectories and summarizes state knowledge for each planning step. This knowledge is integrated into expert trajectories to train the WKM. During planning, WKM provides global task knowledge and maintains dynamic state knowledge, guiding the agent and preventing hallucinatory actions through kNN retrieval and weighted predictions.
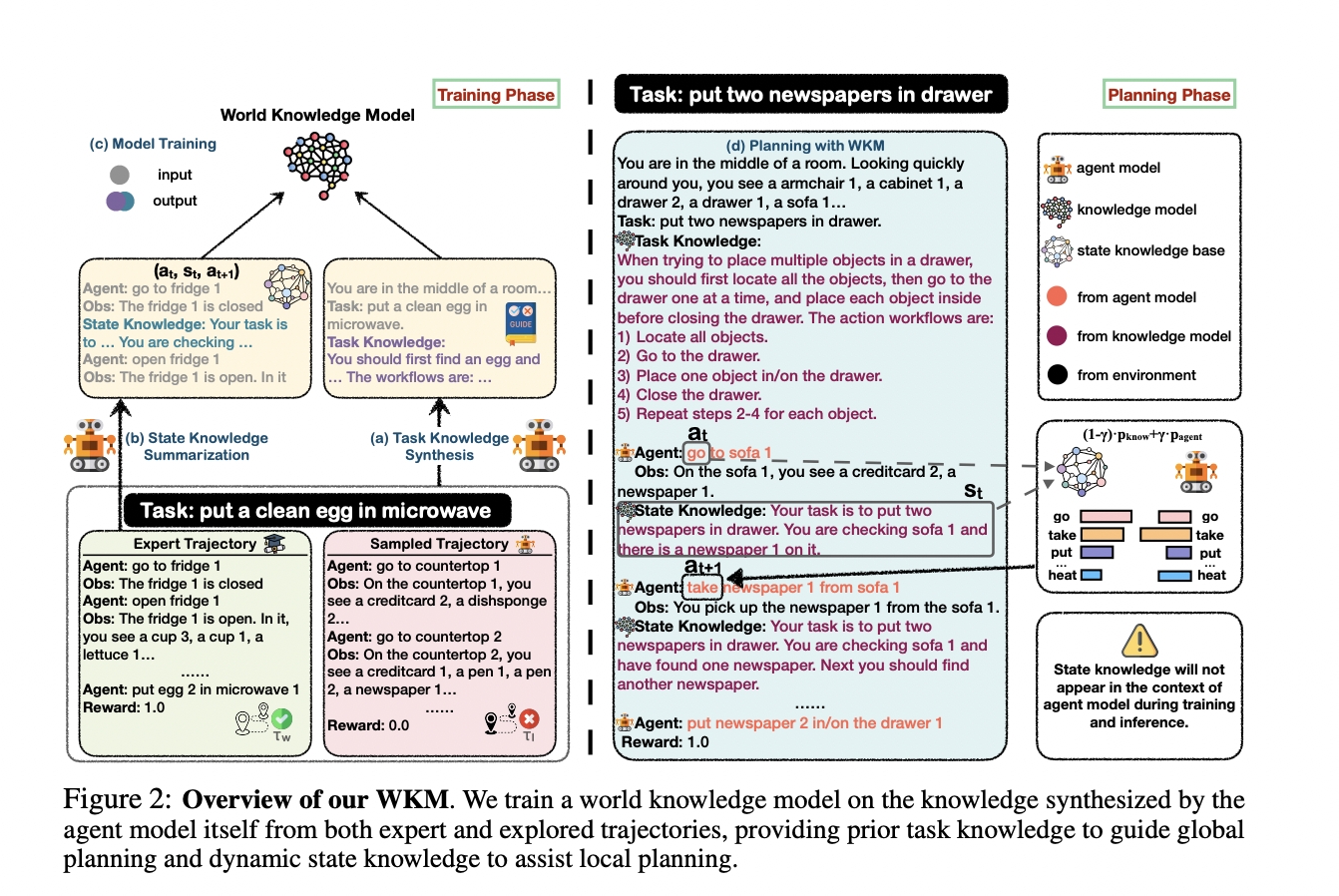
The agent model self-synthesizes task knowledge by comparing expert and sampled trajectories. An experienced agent generates high-quality rejected trajectories, enhancing task knowledge beyond supervised fine-tuning. Task knowledge guides global planning, avoiding blind trial-and-error. State knowledge, summarized at each planning step from expert trajectories, constrains local planning to prevent hallucinatory actions. A state knowledge base, formed by combining state knowledge with preceding and subsequent actions, facilitates retrieval without overloading the context, ensuring effective and accurate agent planning.
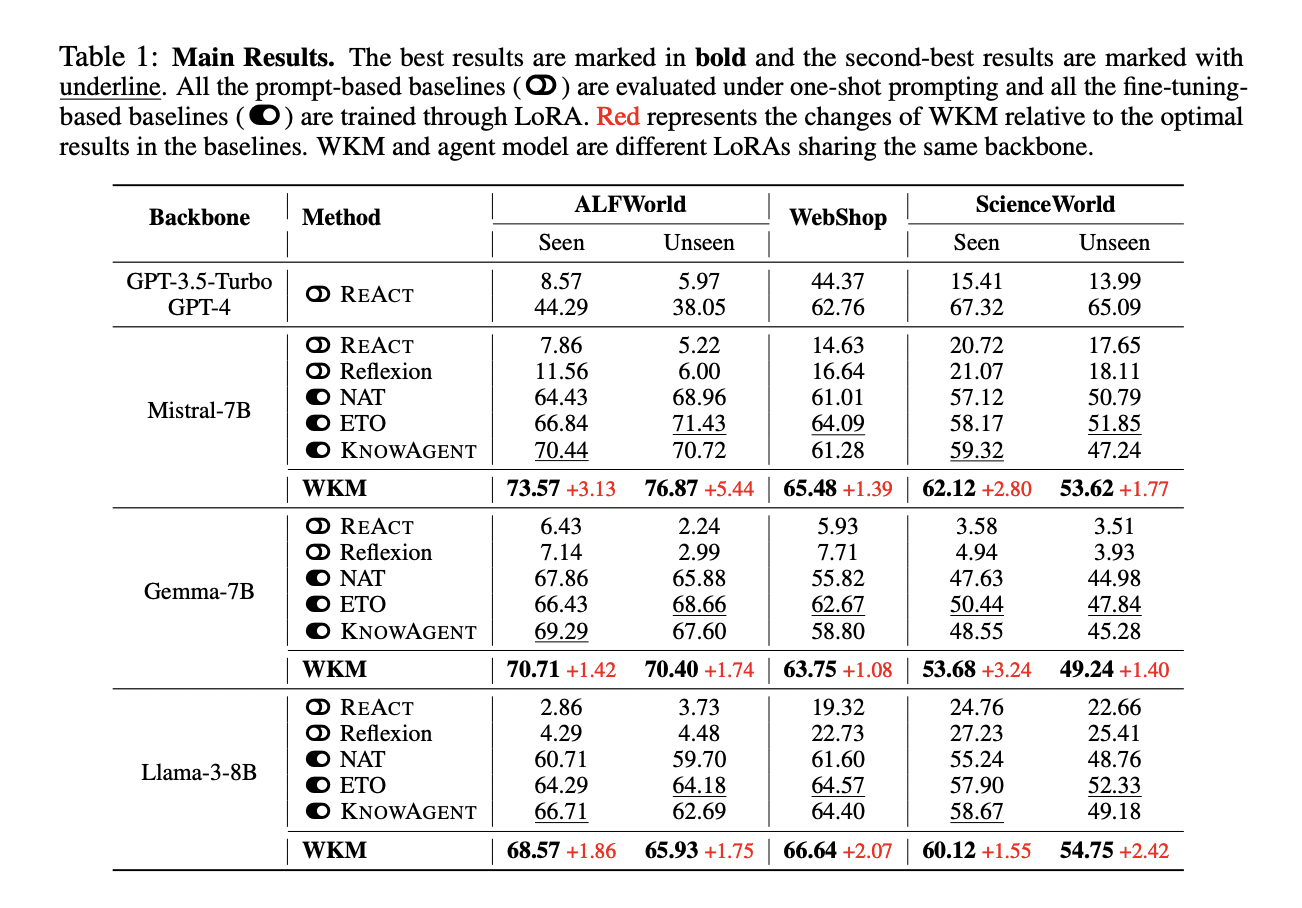
The method is evaluated on ALFWorld, WebShop, and ScienceWorld datasets, with unseen tasks testing generalization. ALFWorld uses binary rewards, while WebShop and ScienceWorld use dense rewards. The models tested include Mistral-7B, Gemma-7B, and Llama-3-8B, compared against prompt-based baselines (REACT, Reflexion), fine-tuning baselines (NAT, ETO), KNOWAGENT, and ChatGPT/GPT-4. The approach, through LoRA training alone, surpasses GPT-4 on ALFWorld (44.29→73.57 on seen, 38.05→76.87 on unseen) and WebShop (62.76→66.64), and fine-tuning baselines, demonstrating that integrating world knowledge is more effective than further fine-tuning on negative examples. WKM shows superior performance and generalization compared to human-designed knowledge methods like KNOWAGENT.
This research develops a parametric WKM to enhance language agent model planning. The WKM provides task knowledge for global planning and state knowledge for local planning. Results show WKM’s superior performance on GPT-4 and state-of-the-art models, outperforming strong baselines. Analytical experiments demonstrate WKM’s ability to reduce trial-and-error, improve generalization to unseen tasks, achieve weak-guide-strong, and extend to unified world knowledge training.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 43k+ ML SubReddit
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.
