Federated learning enables collaborative model training by aggregating gradients from multiple clients, thus preserving their private data. However, gradient inversion attacks can compromise this privacy by reconstructing the original data from the shared gradients. While effective on image data, these attacks need help with text due to their discrete nature, leading to only approximate recovery of small batches and short sequences. This challenges LLMs in sensitive fields like law and medicine, where privacy is crucial. Despite federated learning’s promise, its privacy guarantees are undermined by these gradient inversion attacks.
Researchers from INSAIT, Sofia University, ETH Zurich, and LogicStar.ai have developed DAGER, an algorithm that precisely recovers entire batches of input text. DAGER exploits the low-rank structure of self-attention layer gradients and the discrete nature of token embeddings to verify token sequences in client data, enabling exact batch recovery without prior knowledge. This method, effective for encoder and decoder architectures, uses heuristic search and greedy approaches, respectively. DAGER outperforms previous attacks in speed, scalability, and reconstruction quality, recovering batches up to size 128 on large language models like GPT-2, LLaMa-2, and BERT.
Gradient leakage attacks fall into two main types: honest-but-curious attacks, where the attacker passively observes federated learning updates, and malicious server attacks, where the attacker can modify the model. This paper focuses on the more challenging, honest-but-curious setting. Most research in this area targets image data, with text-based attacks typically requiring malicious adversaries or having limitations like short sequences and small batches. DAGER overcomes these limitations by supporting large batches and sequences for encoder and decoder transformers. It also works for token prediction and sentiment analysis without strong data priors, demonstrating exact reconstruction for transformer-based language models.
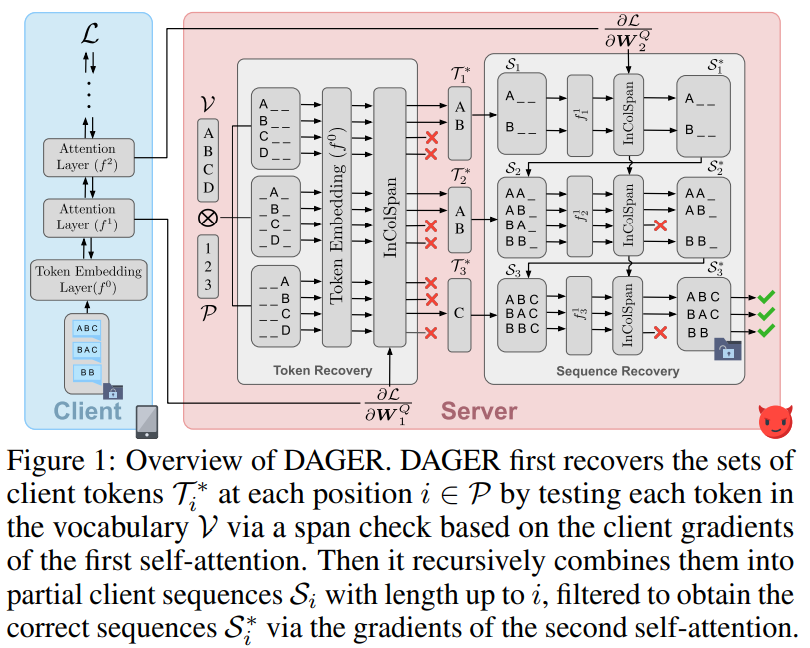
DAGER is an attack that recovers client input sequences from gradients shared in transformer-based language models, focusing on decoder-only models for simplicity. It leverages the rank deficiency of the gradient matrix of self-attention layers to reduce the search space of potential inputs. Initially, DAGER identifies correct client tokens at each position by filtering out incorrect embeddings using gradient subspace checks. Then, it recursively builds partial client sequences, verifying their correctness through subsequent self-attention layers. This two-stage process allows DAGER to reconstruct the full input sequences efficiently by progressively extending partial sequences with verified tokens.
The experimental evaluation of DAGER demonstrates its superior performance compared to previous methods in various settings. Tested on models like BERT, GPT-2, and Llama2-7B, and datasets such as CoLA, SST-2, Rotten Tomatoes, and ECHR, DAGER consistently outperformed TAG and LAMP. DAGER achieved near-perfect sequence reconstructions, significantly surpassing baselines in decoder- and encoder-based models. Its efficiency was highlighted by reduced computation times. The evaluation also confirmed DAGER’s robustness to long sequences and larger models, maintaining high ROUGE scores even for larger batch sizes, showcasing its scalability and effectiveness in diverse scenarios.
In conclusion, the embedding dimension limits DAGER’s performance on decoder-based models, and exact reconstructions are unachievable when the token count exceeds this dimension. Future research could explore DAGER’s resilience against defense mechanisms like DPSGD and its application to more complex FL protocols. For encoder-based models, large batch sizes pose computational challenges due to the growth of the search space, making exact reconstructions difficult. Future work should focus on heuristics to reduce the search space. DAGER highlights the vulnerability of decoder-based LLMs to data leakage, emphasizing the need for robust privacy measures in collaborative learning.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 43k+ ML SubReddit
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.
