LLMs excel in natural language processing tasks but face deployment challenges due to high computational and memory demands during inference. Recent research [MWM+24, WMD+23, SXZ+24, XGZC23, LKM23] aims to enhance LLM efficiency through quantization, pruning, distillation, and improved decoding. Sparsity, a key approach, reduces computation by omitting zero elements and lessens I/O transfer between memory and computation units. While weight sparsity saves computation, it struggles with GPU parallelization and accuracy loss. Activation sparsity, achieved via techniques like the mixture-of-experts (MoE) mechanism, also needs full efficiency and requires further study on scaling laws compared to dense models.
Researchers from Microsoft and the University of Chinese Academy of Sciences have developed Q-Sparse, an efficient approach for training sparsely-activated LLMs. Q-Sparse enables full activation sparsity by applying top-K sparsification to activations and using a straight-through estimator during training, significantly enhancing inference efficiency. Key findings include achieving baseline LLM performance with lower inference costs, establishing an optimal scaling law for sparsely-activated LLMs, and demonstrating effectiveness in various training settings. Q-Sparse works with full-precision and 1-bit models, offering a path to more efficient, cost-effective, and energy-saving LLMs.
Q-Sparse enhances the Transformer architecture by enabling full sparsity in activations through top-K sparsification and the straight-through estimator (STE). This approach applies a top-K function to the activations during matrix multiplication, reducing computational costs and memory footprint. It supports full-precision and quantized models, including 1-bit models like BitNet b1.58. Additionally, Q-Sparse uses squared ReLU for feed-forward layers to improve activation sparsity. For training, it overcomes gradient vanishing by using STE. Q-Sparse is effective for training from scratch, continue-training, and fine-tuning, maintaining efficiency and performance across various settings.
Recent studies show that LLM performance scales with model size and training data follow a power law. The researchers explore this for sparsely-activated LLMs, finding their performance also follows a power law with model size and an exponential statute with sparsity ratio. Experiments reveal that, with a fixed sparsity ratio, sparsely-activated models’ performance scales are similar to those of dense models. The performance gap between sparse and dense models diminishes with increasing model size. An inference-optimal scaling law indicates that sparse models can efficiently match or outperform dense models with proper sparsity, with optimal sparsity ratios of 45.58% for full precision and 61.25% for 1.58-bit models.
The researchers evaluated Q-Sparse LLMs in various settings, including training from scratch, continue-training, and fine-tuning. When training from scratch with 50B tokens, Q-Sparse matched dense baselines at 40% sparsity. BitNet b1.58 models with Q-Sparse outperformed dense baselines with the same compute budget. Continue-training of Mistral 7B showed that Q-Sparse achieved comparable performance to dense baselines but with higher efficiency. Fine-tuning results demonstrated that Q-Sparse models with around 4B activated parameters matched or exceeded the performance of dense 7B models, proving Q-Sparse’s efficiency and effectiveness across training scenarios.
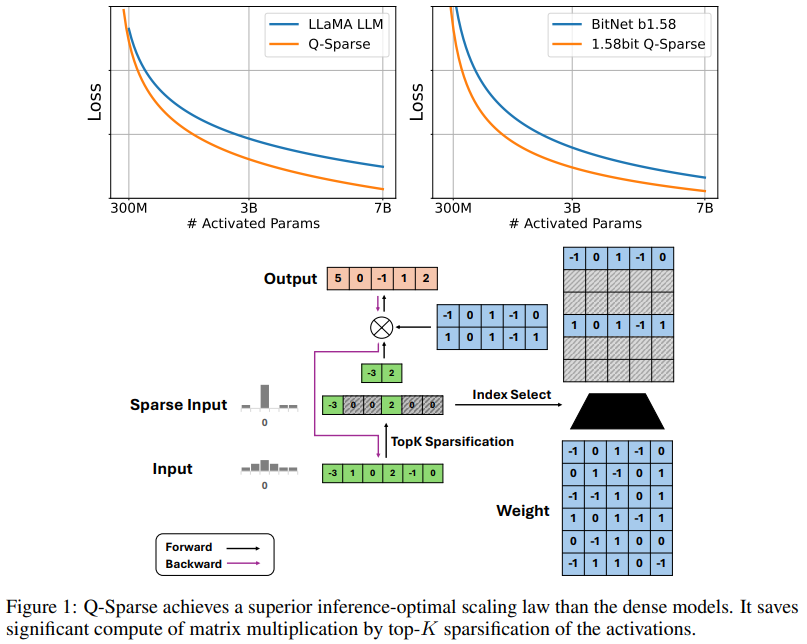
In conclusion, the results show that combining BitNet b1.58 with Q-Sparse offers significant efficiency gains, particularly in inference. The researchers plan to scale up training with more model sizes and tokens and integrate YOCO to optimize KV cache management. Q-Sparse complements MoE and will be adapted for batch processing to enhance its practicality. Q-Sparse performs comparably to dense baselines, enhancing inference efficiency through top-K sparsification and the straight-through estimator. It is effective across various settings and compatible with full-precision and 1-bit models, making it a pivotal approach for improving LLM efficiency and sustainability.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.
