Community Question Answering (CQA) platforms, exemplified by Quora, Yahoo! Answers, and StackOverflow, serve as interactive hubs for information exchange. Despite their popularity, the varying quality of responses poses a challenge for users who must navigate through numerous answers to find relevant information efficiently. Answer selection becomes pivotal, aiming to pinpoint the most pertinent responses from a pool of options. This task is complex due to syntactic variations and the presence of noise in answers. Traditional methods and newer technologies like attention mechanisms address these challenges, yet there’s room for enhancing the interaction between questions and answers.
Traditional methods for answer selection in CQA encompass content/user modeling and adaptive support. Content/user modeling involves extracting features from user interactions, while adaptive support aids user collaboration through question retrieval and routing. Attention mechanisms, widely used in question-answering tasks, enhance features and facilitate cross-sequence relationships. Large language models (LLMs) like chatGPT have garnered attention in natural language processing, particularly in Q&A tasks.
Researchers from PricewaterhouseCoopers introduced Question-Answer cross-attention networks (QAN), they used the external knowledge generated by the large language model LLaMa to enhance answer selection performance by LLM. BERT was utilized for pre-training on question subjects, bodies, and answers, along with cross-attention mechanisms, capturing comprehensive semantic information and interactive features. Integration of llama-7b-hf, a large language model, enhances alignment between questions and answers. Prompt optimization from four perspectives enables LLM to select correct answers more effectively, offering insights into prompt optimization strategies. These contributions lead to state-of-the-art performance on SemEval2015 and SemEval2017 datasets, surpassing existing models.

The QAN model comprises three layers. Firstly, it employs BERT to capture contextual representations of question subjects, bodies, and answers in token form. Next, the cross-attention mechanism analyzes relationships between question subject-answer and question body-answer pairs, computing relevance and generating similarity matrices. Subsequently, the Interaction and Prediction Layer processes interaction features and assigns labels to each answer based on conditional probabilities. It incorporates bidirectional GRU for context acquisition, followed by max and mean pooling of questions and answers to obtain fixed-length vectors. These vectors are concatenated to produce a global representation that is passed to an MLP classifier to determine semantic equivalence in the question-answer pair.
QAN outperforms all baseline models on three evaluation metrics, with advancements attributed to the pre-trained BERT model and attention mechanism. Six variants of QAN were evaluated on the Yahoo! Answers dataset. Variations included excluding BERT in favor of task-specific word embeddings or character embeddings, eliminating cross attention, or the interaction and prediction layer. Some variants combined outputs directly or treated question subjects and bodies as one entity during pre-training with BERT. These variations aimed to assess the impact of different components on answer selection performance.
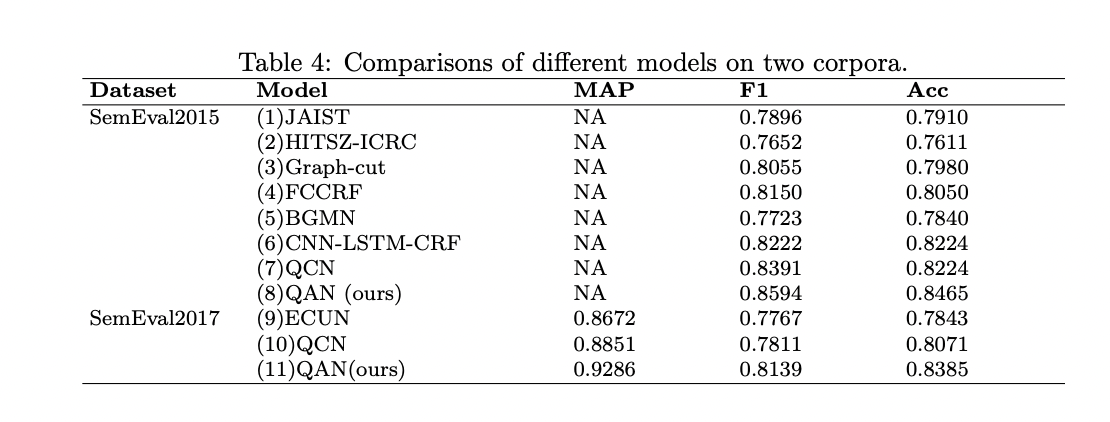
The proposed QAN model utilizes BERT to capture context features of question subjects, bodies, and answers. With a cross-attention mechanism, it gathers comprehensive interactive information between questions and answers. By integrating attention-questions and attention-answers, the QAN model achieves state-of-the-art performance. Also, integrating large language models with knowledge enhancement improves answer selection accuracy.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 43k+ ML SubReddit | Also, check out our AI Events Platform
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.
