
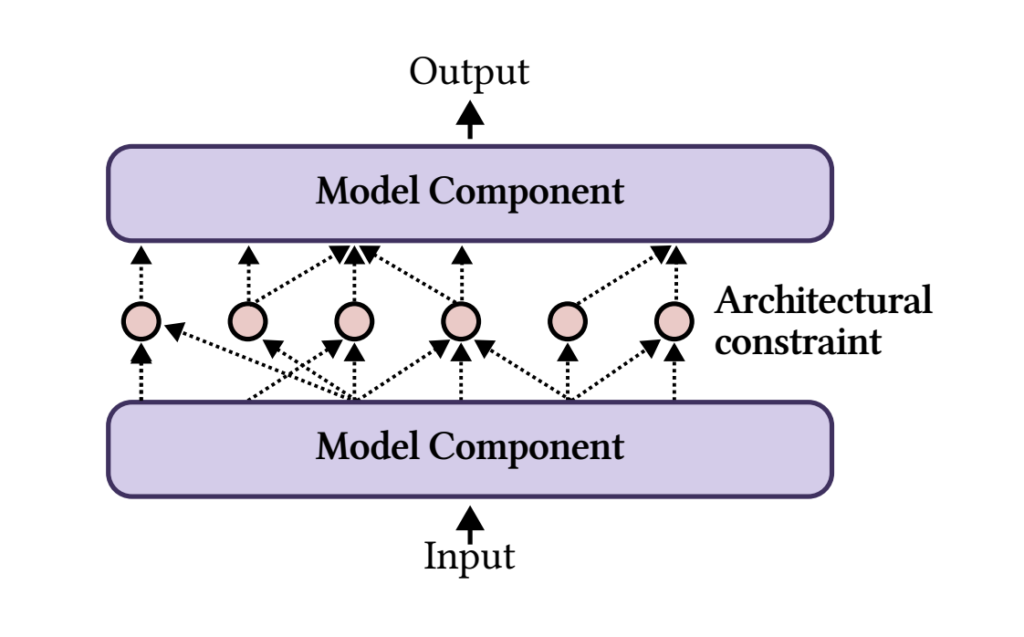
Ensuring AI models provide faithful and reliable explanations of their decision-making processes is still challenging. Faithfulness in the sense of explanations faithfully representing the underlying logic of a model prevents false confidence in AI systems, which is critical for healthcare, finance, and policymaking. Existing paradigms for interpretability—intrinsic (focused on inherently interpretable models) and post-hoc (providing explanations for pre-trained black-box models)—struggle to address these needs effectively. These fail to meet the current needs. This shortfall confines the use of AI to high-stakes scenarios, making it an urgent requirement to have innovative solutions.
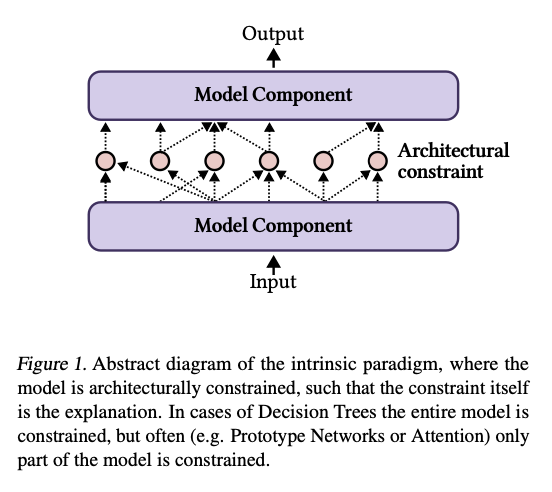
Intrinsic approaches revolve around models such as decision trees or neural networks with restricted architectures that offer interpretability as a byproduct of their design. However, these models often fail in general applicability and competitive performance. In addition, many only partially achieve interpretability, with core components such as dense or recurrent layers remaining opaque. In contrast, post-hoc approaches generate explanations for pre-trained models using gradient-based importance measures or feature attribution techniques. While these methods are more flexible, their explanations frequently fail to align with the model’s logic, resulting in inconsistency and limited reliability. Additionally, post-hoc methods often depend heavily on specific tasks and datasets, making them less generalizable. These limitations highlight the critical need for a reimagined framework that balances faithfulness, generality, and performance.
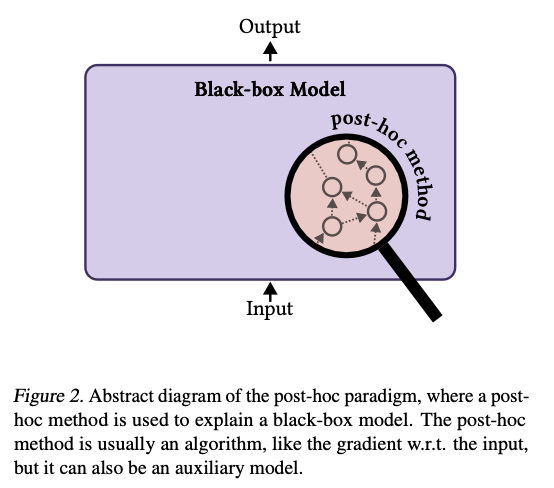
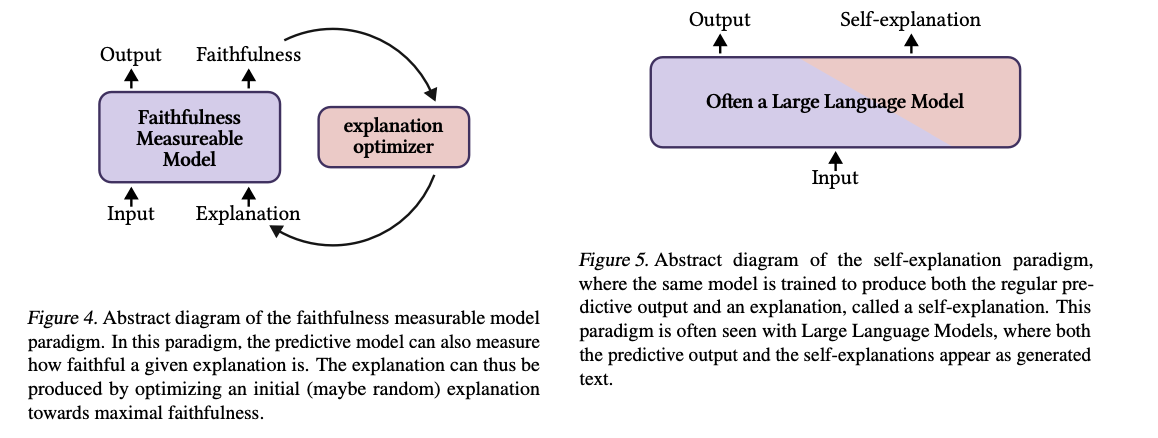
To address these gaps, researchers have introduced three groundbreaking paradigms for achieving faithful and interpretable models. The first, Learn-to-Faithfully-Explain, focuses on optimizing predictive models alongside explanation methods to ensure alignment with the model’s reasoning. The direction of improving faithfulness using optimization techniques – that is, joint or disjoint training, and second, Faithfulness-Measurable Models: This mechanism puts the means to measure explanation fidelity into the design for the model. Through such an approach, optimal explanation generation could be undertaken with the assurance that doing so would not impair a model’s structural flexibility. Finally, Self-Explaining Models generate predictions and explanations simultaneously, integrating reasoning processes into the model. While promising for real-time applications, this paradigm should be further refined to ensure explanations are reliable and consistent across runs. These innovations bring about a shift of interest from external explanation techniques towards systems that are inherently interpretable and trustworthy.

These approaches will be evaluated on synthetic datasets and real-world datasets where faithfulness and interpretability will be of great emphasis. Such optimization methods make use of Joint Amortized Explanation Models (JAMs) to get model predictions to align with explanatory accuracy. However, prevention mechanisms for explanation mechanisms must be used in order not to overfit any specific predictions. These frameworks ensure scalability and robustness for a wide array of usage by incorporating models such as GPT-2 and RoBERTa. Several practical challenges, including robustness to out-of-distribution data and minimizing computational overhead, will be balanced with interpretability and performance. These refinement steps form a pathway towards more transparent and reliable AI systems.

We find that this approach brings significant improvements toward faithful explanation without sacrificing prediction performance. The Learn-to-Faithfully-Explain paradigm improves faithfulness metrics by 15% over standard benchmarks, and Faithfulness-Measurable Models give robust and quantified explanations along with high accuracy. Self-explaining models hold promise for more intuitive and real-time interpretations but need further work toward reliability in their outputs. Taken collectively, these results establish that these new frameworks are both practical and well-suited for overcoming the critical shortcomings of present-day interpretability

This work introduces new paradigms that address the deficiencies of intrinsic and post-hoc paradigms for interpreting the output of complex systems in a transformative way. The focus is on faithfulness and reliability as guiding principles for developing safer and more trustworthy AI systems. In bridging the gap between interpretability and performance, these frameworks promise great progress in real-world applications. Future work should further develop these models to be scalable and impactful across various domains.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.


Aswin AK is a consulting intern at MarkTechPost. He is pursuing his Dual Degree at the Indian Institute of Technology, Kharagpur. He is passionate about data science and machine learning, bringing a strong academic background and hands-on experience in solving real-life cross-domain challenges.