Solving sequential tasks requiring multiple steps poses significant challenges in robotics, particularly in real-world applications where robots operate in uncertain environments. These environments are often stochastic, meaning robots face variability in actions and observations. A core goal in robotics is to improve the efficiency of robotic systems by enabling them to handle long-horizon tasks, which require sustained reasoning over extended periods of time. Decision-making is further complicated by robots’ limited sensors and partial observability of their surroundings, which restrict their ability to understand their environment completely. Consequently, researchers continuously seek new methods to enhance how robots perceive, learn, and act, making robots more autonomous and reliable.
Researchers’ major problem in this area centers around a robot’s inability to learn from past actions efficiently. Robots rely on methods like reinforcement learning (RL) to improve performance. However, RL requires many trials, often in the millions, for a robot to become proficient at completing tasks. This is impractical, especially in partially observable environments where robots cannot interact continuously due to the associated risks. Moreover, existing systems, such as decision-making models powered by large language models (LLMs), struggle to retain past interactions, forcing robots to repeat errors or relearn strategies they have already encountered. This inability to apply prior knowledge hinders their effectiveness in complex, long-term tasks.
While RL and LLM-based agents have shown promise, they exhibit several limitations. Reinforcement learning, for instance, is highly data-intensive and demands significant manual effort for designing reward functions. On the other hand, LLM-based agents, which are used for generating action sequences, often lack the ability to refine their actions based on past experiences. Recent methods have incorporated critics to evaluate the feasibility of decisions. However, they still fall short in one critical area: the ability to store and retrieve useful knowledge from past interactions. This gap means that while these systems can perform well in short-term or static tasks, their performance degrades in dynamic environments, requiring continual learning and adaptation.
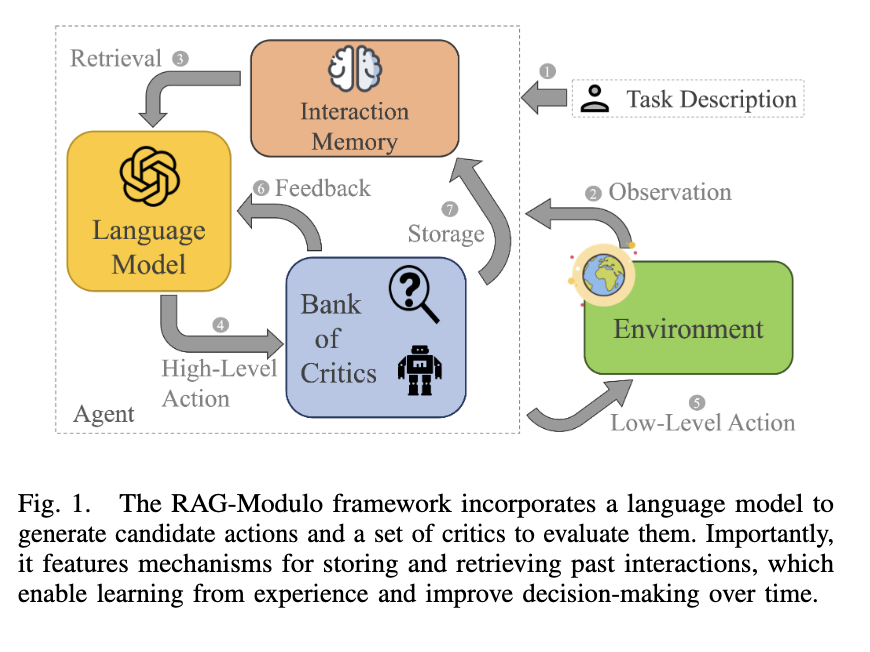
Researchers from Rice University have introduced the RAG-Modulo framework. This novel system enhances LLM-based agents by equipping them with an interaction memory. This memory stores past decisions, allowing robots to recall and apply relevant experiences when confronted with similar tasks in the future. By doing so, the system improves decision-making capabilities over time. Further, the framework uses a set of critics to assess the feasibility of actions, offering feedback based on syntax, semantics, and low-level policy. These critics ensure that the robot’s actions are executable and contextually appropriate. Importantly, this approach eliminates the need for extensive manual tuning, as the memory automatically adapts and tunes prompts for the LLM based on past experiences.
The RAG-Modulo framework maintains a dynamic memory of the robot’s interactions, enabling it to retrieve past actions and results as in-context examples. When facing a new task, the framework draws upon this memory to guide the robot’s decision-making process, thus avoiding repeated mistakes and enhancing efficiency. The critics embedded within the system act as verifiers, providing real-time feedback on the viability of actions. For example, if a robot attempts to perform an infeasible action, such as picking up an object in an occupied space, the critics will suggest corrective steps. As the robot continues to perform tasks, its memory expands, becoming more capable of handling increasingly complex sequences. This approach ensures continual learning without frequent reprogramming or human intervention.
The performance of RAG-Modulo has been rigorously tested in two benchmark environments: BabyAI and AlfWorld. The system demonstrated a marked improvement over baseline models, achieving higher success rates and reducing the number of infeasible actions. In BabyAI-Synth, for instance, RAG-Modulo achieved a success rate of 57%, while the closest competing model, LLM-Planner, reached only 43%. The performance gap widened in the more complex BabyAI-BossLevel, where RAG-Modulo attained a 57% success rate compared to LLM-Planner’s 37%. Similarly, in the AlfWorld environment, RAG-Modulo exhibited superior decision-making efficiency, with fewer failed actions and shorter task completion times. In the AlfWorld-Seen environment, the framework achieved an average in-executability rate of 0.09 compared to 0.16 for LLM-Planner. These results demonstrate the system’s ability to generalize from prior experiences and optimize robot performance.
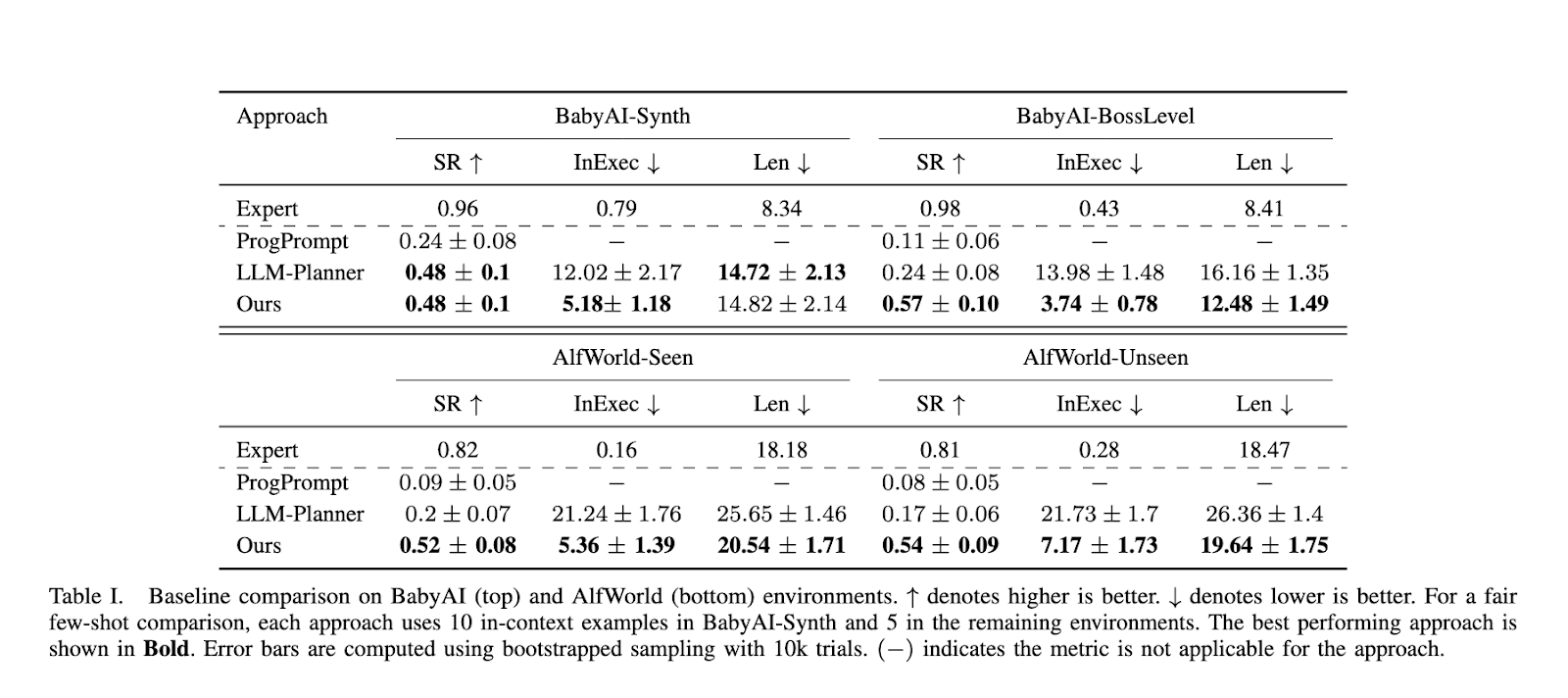
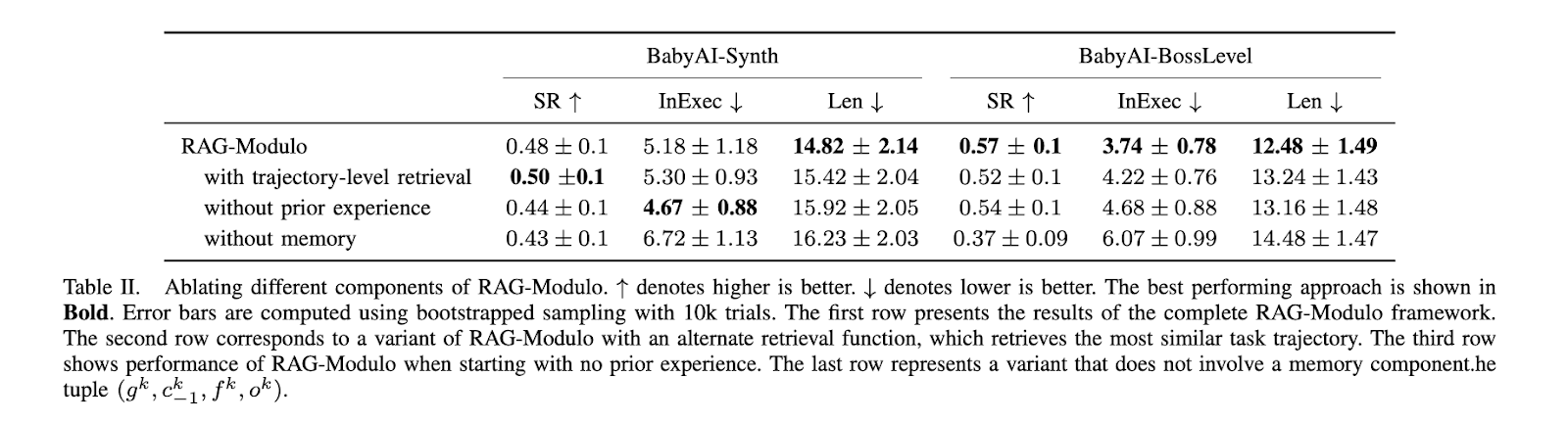
Regarding task execution, RAG-Modulo also reduced the average episode length, highlighting its ability to accomplish tasks more efficiently. In BabyAI-Synth, the average episode length was 12.48 steps, whereas other models required over 16 steps to complete the same tasks. This reduction in episode length is significant because it increases operational efficiency and lowers the computational costs associated with running the language model for longer durations. By shortening the number of actions needed to achieve a goal, the framework reduces the overall complexity of task execution while ensuring that the robot learns from every decision it makes.
The RAG-Modulo framework presents a substantial leap forward in enabling robots to learn from past interactions and apply this knowledge to future tasks. By addressing the critical challenge of memory retention in LLM-based agents, the system provides a scalable solution for handling complex, long-horizon tasks. Its ability to couple memory with real-time feedback from critics ensures that robots can continuously improve without requiring excessive manual intervention. This advancement marks a significant step toward more autonomous, intelligent robotic systems capable of learning and evolving in real-world environments.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.
