Language model routing is a growing field focused on optimizing the utilization of large language models (LLMs) for diverse tasks. With capabilities spanning text generation, summarization, and reasoning, these models are increasingly applied to varied input data. The ability to dynamically route specific tasks to the most suitable model has become a crucial challenge, aiming to balance efficiency with accuracy in handling these multifaceted tasks.
One major challenge in deploying LLMs is selecting the most suitable model for a given input task. While numerous pre-trained LLMs are available, their performance can vary significantly based on the task. Determining which model to use for a specific input traditionally involves relying on labeled datasets or human annotations. These resource-intensive methods pose significant barriers to scaling and generalization, particularly in applications requiring real-time decisions or a wide range of capabilities.
Existing approaches for routing tasks to LLMs typically involve auxiliary training or heuristic-based selection. These methods often depend on labeled datasets to rank or predict the best-performing model for a given input. While effective to some degree, these strategies are limited by the availability of high-quality annotated data and the computational costs of training auxiliary models. As a result, the broader applicability of these methods remains constrained.
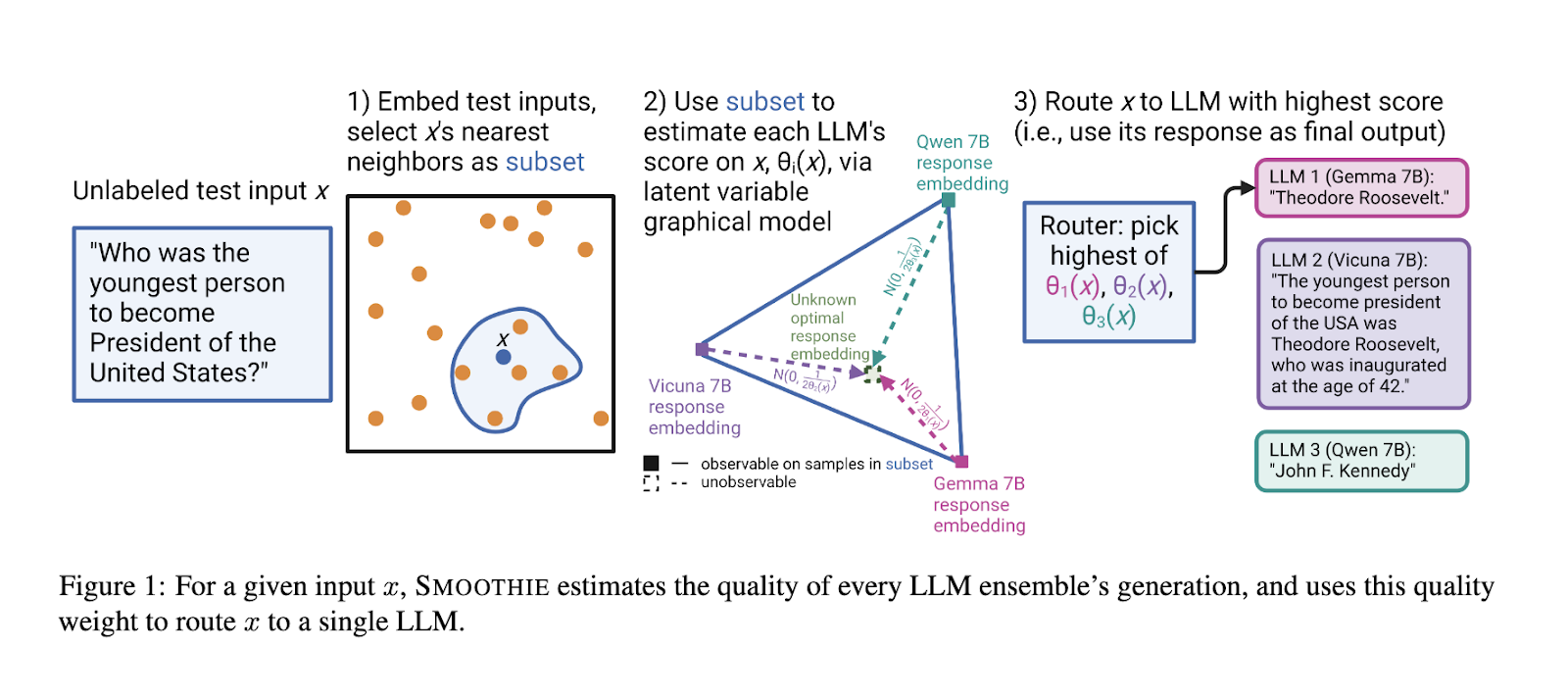
Researchers from Stanford University have introduced SMOOTHIE, an innovative unsupervised language model routing approach designed to overcome the limitations of labeled data. SMOOTHIE leverages principles from weak supervision, employing a latent variable graphical model to evaluate the outputs of multiple LLMs. By estimating sample-specific quality scores, the method routes each input to the LLM most likely to produce optimal results. This approach provides a novel solution by eliminating the dependency on labeled datasets, significantly reducing resource requirements.
SMOOTHIE consists of two primary variations: SMOOTHIE-GLOBAL and SMOOTHIE-LOCAL. SMOOTHIE-GLOBAL derives quality estimates for all test data, creating a broad model performance evaluation. Conversely, SMOOTHIE-LOCAL refines this process by focusing on the nearest neighbors of a sample in the embedding space, enhancing precision in routing. The methodology employs embedding representations of observable outputs and latent variables to model differences between generated outputs and hypothetical true outputs. These differences are represented as a multivariate Gaussian, allowing the researchers to derive closed-form estimators for quality scores. The method also incorporates kernel smoothing in SMOOTHIE-LOCAL to further tailor quality estimates to individual samples, ensuring that routing decisions are dynamically optimized.
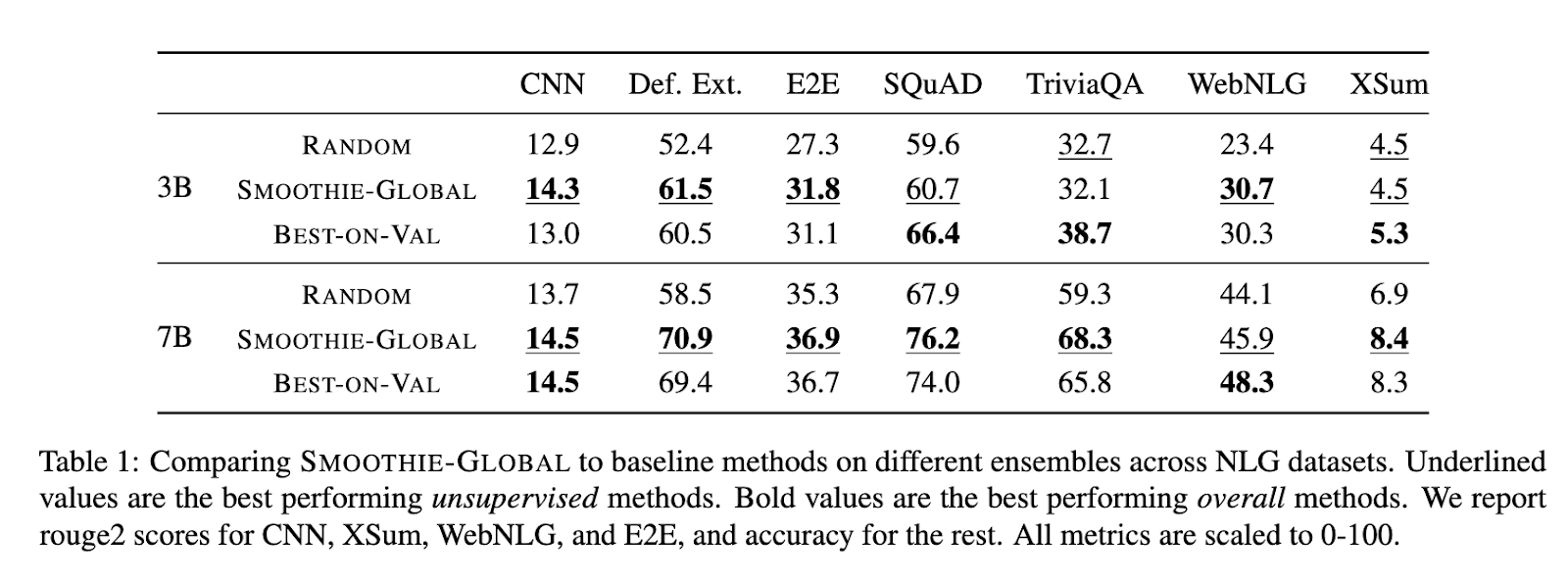
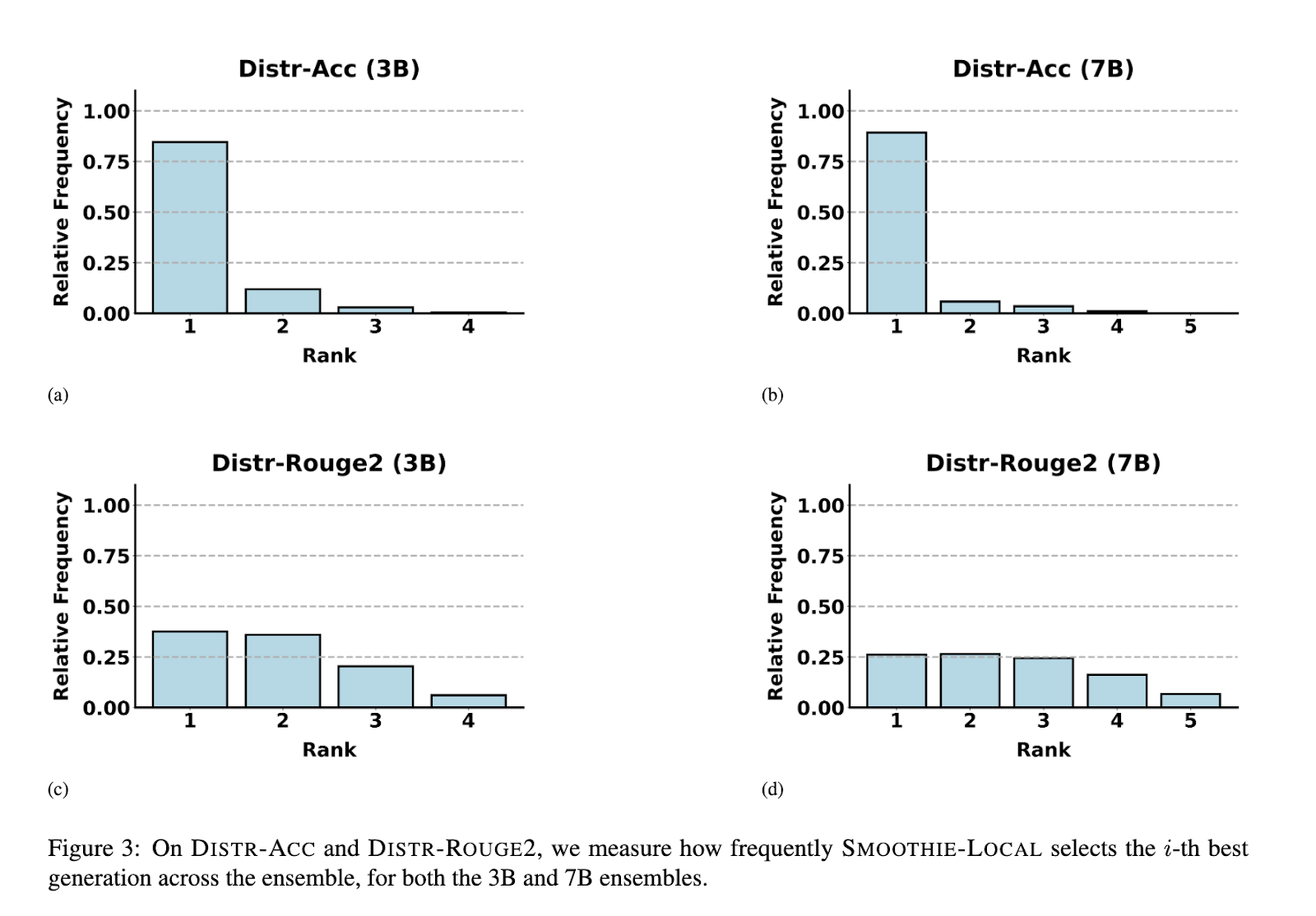
The performance of SMOOTHIE was evaluated extensively across multiple datasets and settings. SMOOTHIE-GLOBAL demonstrated its capability to identify the best-performing model in 9 out of 14 tasks. For instance, on datasets such as AlpacaEval, SMOOTHIE-GLOBAL improved win rates by up to 15 percentage points compared to random-selection baselines and by 8 points on SQuAD. The LOCAL variant further excelled, outperforming global and supervised routing methods in multi-task scenarios. In mixed-task datasets, SMOOTHIE-LOCAL improved task accuracy by up to 10 points over baseline methods. Furthermore, it achieved strong correlations between estimated and actual model quality, with a rank correlation coefficient of 0.72 on natural language generation tasks and 0.94 on MixInstruct. SMOOTHIE’s local routing enabled smaller models to outperform larger counterparts in several configurations, highlighting its effectiveness in resource-efficient scenarios.
The results underscore SMOOTHIE’s potential to transform LLM routing by addressing the reliance on labeled data and auxiliary training. Combining weak supervision techniques with innovative quality estimation models enables robust and efficient routing decisions in multi-capability environments. The research presents a scalable and practical solution for enhancing LLM performance, paving the way for broader adoption in real-world applications where task diversity and accuracy are paramount.
This research signifies a pivotal advancement in the field of language model routing. Addressing challenges in task-specific LLM selection with an unsupervised approach opens avenues for improving the deployment of LLMs across diverse applications. The introduction of SMOOTHIE streamlines the process and ensures a significant enhancement in output quality, demonstrating the growing potential of weak supervision in artificial intelligence.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.
