

Document Visual Question Answering (DocVQA) represents a rapidly advancing field aimed at improving AI’s ability to interpret, analyze, and respond to questions based on complex documents that integrate text, images, tables, and other visual elements. This capability is increasingly valuable in finance, healthcare, and law settings, as it can streamline and support decision-making processes that rely on understanding dense and multifaceted information. Traditional document processing methods, however, often need to catch up when faced with these kinds of documents, highlighting the need for more sophisticated, multi-modal systems that can interpret information spread across different pages and varied formats.
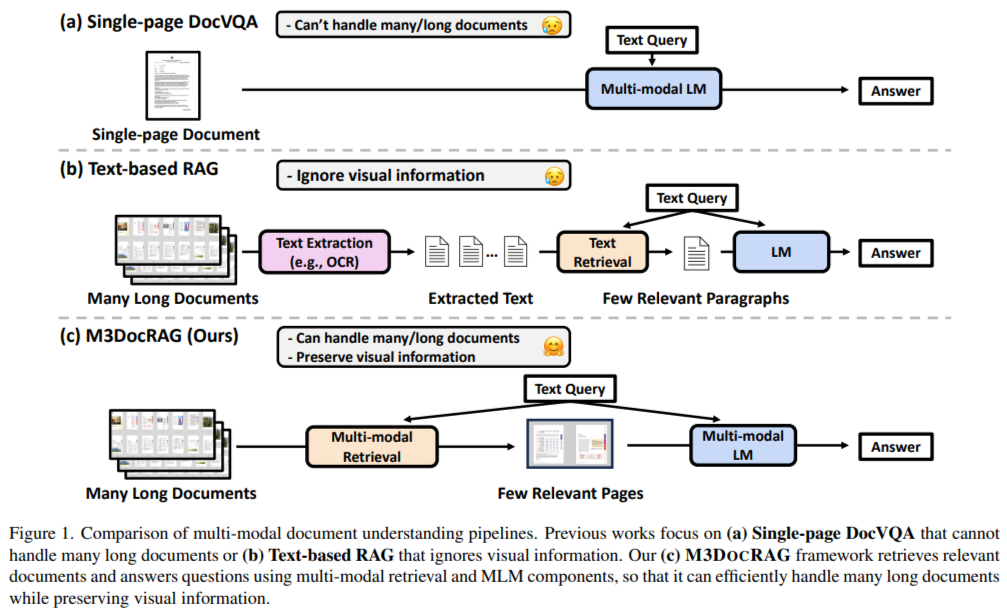
The primary challenge in DocVQA is accurately retrieving and interpreting information that spans multiple pages or documents. Conventional models tend to focus on single-page documents or rely on simple text extraction, which may ignore critical visual information such as images, charts, and complex layouts. Such limitations hinder AI’s ability to fully understand documents in real-world scenarios, where valuable information is often embedded in diverse formats across various pages. These limitations require advanced techniques that effectively integrate visual and textual data across multiple document pages.
Existing DocVQA approaches include single-page visual question answering (VQA) and retrieval-augmented generation (RAG) systems that use optical character recognition (OCR) to extract and interpret text. However, these methods must still be fully equipped to handle the multimodal requirements of detailed document comprehension. Text-based RAG pipelines, while functional, typically fail to retain visual nuances, which can lead to incomplete answers. This gap in performance highlights the necessity of developing a multimodal approach capable of processing extensive documents without sacrificing accuracy or speed.
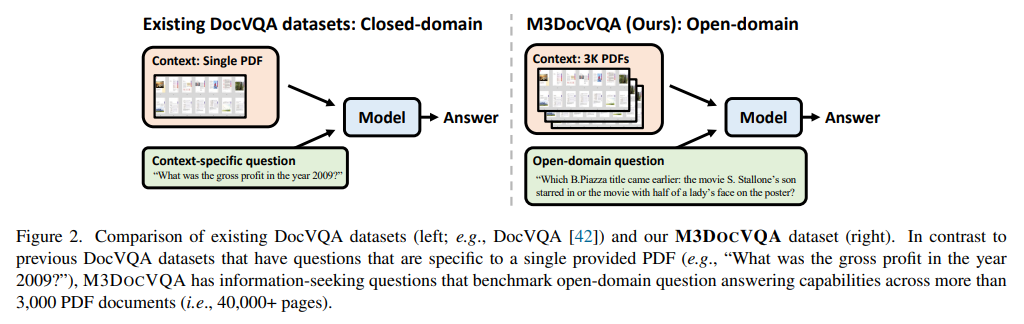
Researchers from UNC Chapel Hill and Bloomberg have introduced M3DocRAG, a groundbreaking framework designed to enhance AI’s capacity to perform document-level question answering across multimodal, multi-page, and multi-document settings. This framework includes a multimodal RAG system that effectively incorporates text and visual elements, allowing for accurate comprehension and question-answering across various document types. M3DocRAG’s design will enable it to work efficiently in closed-domain and open-domain scenarios, making it adaptable across multiple sectors and applications.
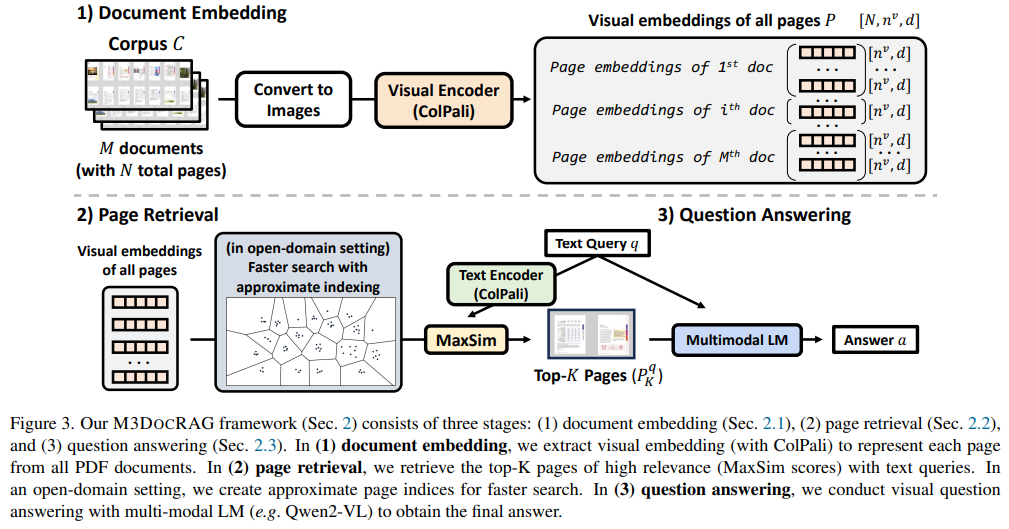
The M3DocRAG framework operates through three primary stages. First, it converts all document pages into images and applies visual embeddings to encode page data, ensuring that visual and textual features are retained. Second, it uses multi-modal retrieval models to identify the most relevant pages from a document corpus, using advanced indexing methods to optimize search speed and relevance. Finally, a multi-modal language model processes these retrieved pages to generate accurate answers to user questions. The visual embeddings ensure that essential information is preserved across multiple pages, addressing the core limitations of prior text-only RAG systems. M3DocRAG can operate on large-scale document sets, handling up to 40,000 pages spread over 3,368 PDF documents with a retrieval latency reduced to under 2 seconds per query, depending on the indexing method.

Results from empirical testing show M3DocRAG’s strong performance across three key DocVQA benchmarks: M3D OC VQA, MMLongBench-Doc, and MP-DocVQA. These benchmarks simulate real-world challenges like multi-page reasoning and open-domain question answering. M3DocRAG achieved a 36.5% F1 score on the open-domain M3D OC VQA benchmark and state-of-the-art performance in MP-DocVQA, which requires single-document question answering. The system’s ability to accurately retrieve answers across different evidence modalities (text, tables, images) underpins its robust performance. M3DocRAG’s flexibility extends to handling complex scenarios where answers depend on multi-page evidence or non-textual content.

Key findings from this research highlight the M3DocRAG system’s advantages over existing methods in several crucial areas:
- Efficiency: M3DocRAG reduces retrieval latency to under 2 seconds per query for large document sets using optimized indexing, enabling quick response times.
- Accuracy: The system maintains high accuracy across varied document formats and lengths by integrating multi-modal retrieval with language modeling, achieving top results in benchmarks like M3D OC VQA and MP-DocVQA.
- Scalability: M3DocRAG effectively manages open-domain question answering for large datasets, handling up to 3,368 documents or 40,000+ pages, which sets a new standard for scalability in DocVQA.
- Versatility: This system accommodates diverse document settings in closed-domain (single-document) or open-domain (multi-document) contexts and efficiently retrieves answers across different evidence types.



In conclusion, M3DocRAG stands out as an innovative solution in the DocVQA field, designed to overcome the traditional limitations of document comprehension models. It brings a multi-modal, multi-page, and multi-document capability to AI-based question answering, advancing the field by supporting efficient and accurate retrieval in complex document scenarios. By incorporating textual and visual features, M3DocRAG bridges a significant gap in document understanding, offering a scalable and adaptable solution that can impact numerous sectors where comprehensive document analysis is critical. This work encourages future exploration in multi-modal retrieval and generation, setting a benchmark for robust, scalable, and real-world-ready DocVQA applications.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[AI Magazine/Report] Read Our Latest Report on ‘SMALL LANGUAGE MODELS‘


Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.