

Diffusion models have pulled ahead of others in text-to-image generation. With continuous research in this field over the past year, we can now generate high-resolution, realistic images that are indistinguishable from authentic images. However, with the increasing quality of the hyperrealistic images model, parameters are also escalating, and this trend results in high training and inference costs. Ever-increasing computational expenses and model complexity take image models further away from consumers’ reach. This requires a high-quality and high-resolution image generator that is computationally efficient and runs very fast on cloud and edge devices.
Researchers from NVIDIA and MIT have created SANA, a text-to-image framework that can efficiently generate images up to 4096×4096 resolution. Sana can synthesize high-resolution, high-quality images with strong text-image alignment remarkably fast.SANA 0.6 B has just 590 M parameters to generate quality images. The model does not require massive servers to run; it could be deployed even on a laptop GPU. Sana superseded its competitors in terms of quality offered and service time. It performed better than Pix-Art Σ, which generated images at the resolution of 3840×2160 at a relatively slow rate. SANA mitigates training and inference costs with an improved autoencoder, a linear DiT, and a decoder – only a small LLM, Gemma, as a text encoder. The authors further propose automatic labeling and training strategies to improve the consistency between text and images. They utilize multiple VLMs to generate captions. This is followed by a clip score-based training strategy where authors dynamically select captions with high clip scores for multiple captions based on probability. At last, a Flow-DPM-Solver is put forth that reduces the inference sampling steps from 28-50 to 14-20 steps, all while outperforming current strategies.
To understand this paper, we must look at all the innovations sequentially :
Efficient AutoEncoders: Authors increased the compression ratio of AutoEncoders to 32 from 8 used previously, which reduced latent token consumption by 4 times. High-quality images generally contain high redundancy; thus, a reduction in compression ratio does not affect the quality of the reconstruction of the images. This redundancy is more of a bane in image generation as, besides eating up resources, it led to substandard quality of images.
A Better DiT: Next in the framework, the authors use a vanilla self-attention mechanism with linear attention blocks in DiT (Document Image Transformer) to decrease the complexity from O(N2) to O(N). The DiT authors also replaced the original MLP Feed Forward Networks with Mix-FFNs by incorporating a3×3 depthwise convolution, leading to better token aggregation.
Triton Acceleration: Authors used Triton for faster inference and training. It fused the forward and backward passes of the linear attention blocks. Fusing activation functions, precision conversions, padding operations, and divisions into Matrix multiplications reduced overheads of data transfer.

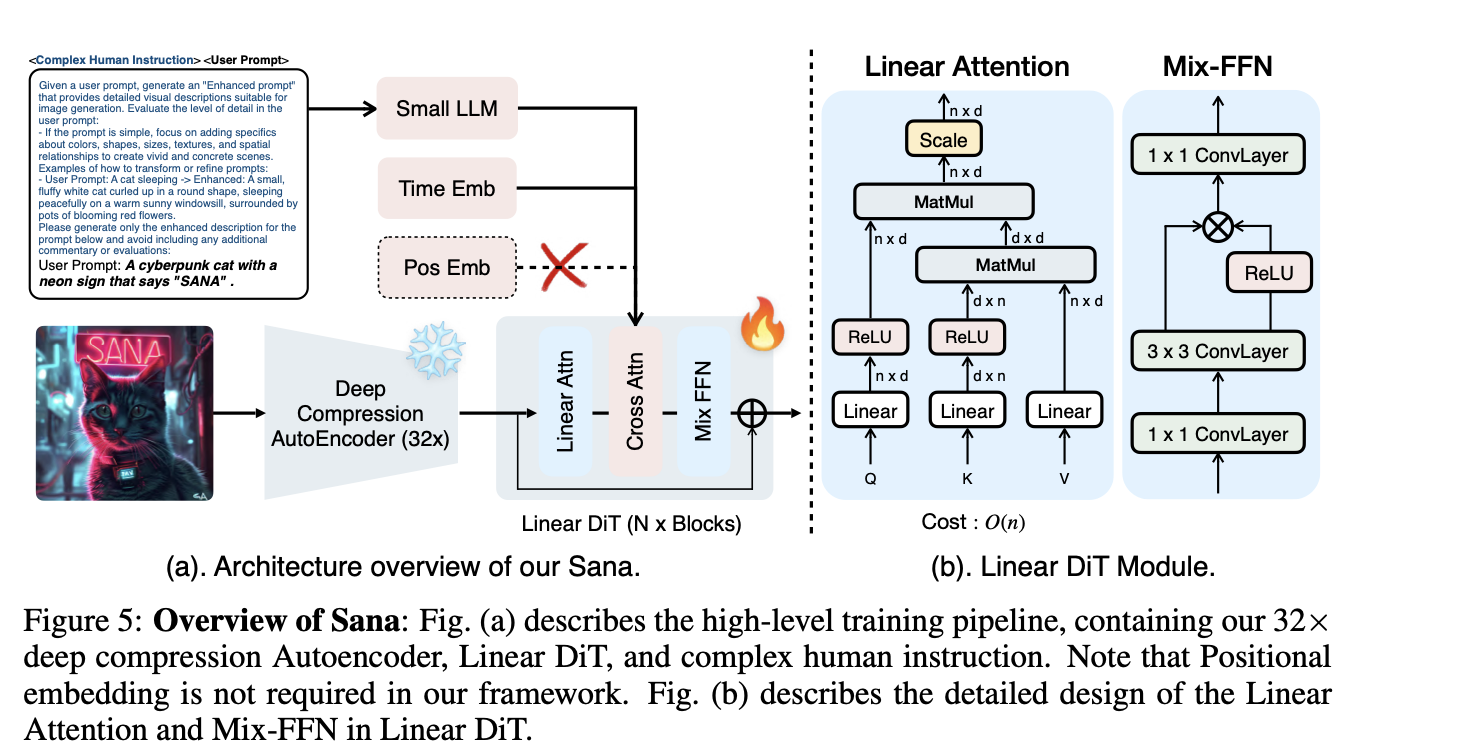
Text-Encoder Design: Authors utilize Gemma -2, a small decoder-based large language model. Its small architecture has better instruction following and reasoning abilities with Chain of Thought, and Context Learning provides better performance than huge encoder-based models like T5.
Multi-Caption Auto-labelling and CLIP-Score-based Caption Sampler: Authors used 4 Vision Language Models to label each training image. Multiple images increased the accuracy and diversity of captions. Further, the authors use a clip score-based sampler to sample high-quality text with greater probability.
Flow-Based Training and Inference: SANA proposes Flow-DPM-Solver, a modification of DPM-Solver++ with Rectified Flow formulation to achieve a lower signal-noise ratio. In addition to the above utility, the proposed workflow also predicts the velocity field, unlike the latter. Consequently, Flow-DPM-Solver converges at 14∼20 steps with better performance.
Edge Deployment: SANA is quantized with per token symmetric 8-bit integers for activation and weights. Moreover, to preserve a high semantic similarity to the 16-bit variant while incurring minimal runtime overhead, authors retained various layers of the model at complete precision. This optimization in deployment on the laptop increased speed by 2.4 times.
To sum up, SANA’s framework proposed many implementations that achieved new heights in image generation – 4K delivering 100 times better throughput than SOTA. A further challenge would be to see how SANA could be optimized for the video paradigm.
Check out the Paper, GitHub Page, and Demo. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.


Adeeba Alam Ansari is currently pursuing her Dual Degree at the Indian Institute of Technology (IIT) Kharagpur, earning a B.Tech in Industrial Engineering and an M.Tech in Financial Engineering. With a keen interest in machine learning and artificial intelligence, she is an avid reader and an inquisitive individual. Adeeba firmly believes in the power of technology to empower society and promote welfare through innovative solutions driven by empathy and a deep understanding of real-world challenges.