Natural language processing has greatly improved language model finetuning. This process involves refining AI models to perform specific tasks more effectively by training them on extensive datasets. However, creating these large, diverse datasets is complex and expensive, often requiring substantial human input. This challenge has created a gap between academic research, which typically uses smaller datasets, and industrial applications, which benefit from vast, finely-tuned datasets.
Among many, one major problem in this field is the reliance on human-annotated data. Manually curating datasets is labor-intensive and costly, limiting the scale and diversity of the data that can be generated. Academic datasets often comprise hundreds or thousands of samples, while industrial datasets may contain tens of millions. This disparity has driven researchers to explore automated methods for generating instruction datasets that rival the quality of those produced through human labor.
Existing methods to address this problem include using large language models (LLMs) to modify and augment human-written content. While these methods have been somewhat successful, they still need to catch up regarding scalability and diversity. For instance, the Flan collection, used in training the T0 model family, expanded to include thousands of tasks but faced grammatical errors and text quality issues. Similarly, other datasets like Evol-Instruct and UltraChat involve sophisticated augmentation processes that require human oversight.
Researchers from the University of Maryland have proposed an innovative solution to this problem by introducing GenQA. This method leverages a single, well-crafted prompt to autonomously generate millions of diverse instruction examples. GenQA aims to create large-scale and highly diverse datasets by minimizing human intervention. The research team used LLMs to develop a variety of instruction examples, ranging from simple tasks to complex multi-turn dialogs across numerous subject areas.
The core technology behind GenQA involves using generator prompts to enhance the randomness and diversity of the outputs produced by LLMs. A single hand-written meta-prompt can extract millions of diverse questions from an LLM. This approach significantly reduces the need for human oversight. For example, one experiment generated over 11 million questions across nine different splits, each tailored to specific domains such as academics, mathematics, and dialogue. These questions were generated using several prompts that boosted the randomness of the LLM outputs, resulting in a diverse set of instruction examples.
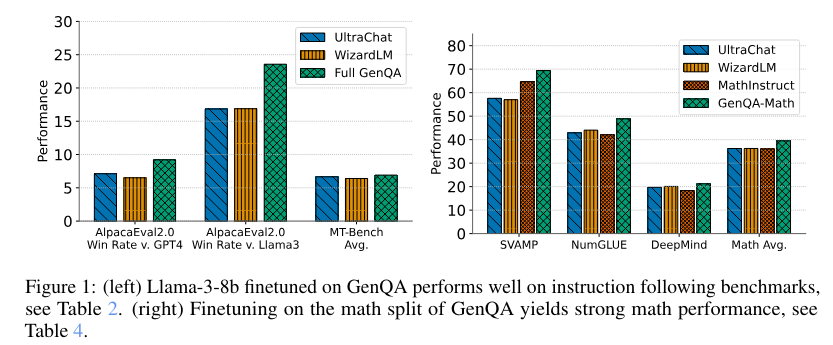
Regarding performance, the researchers tested the GenQA dataset by finetuning a Llama-3 8B base model. The results were impressive, with the model’s performance on knowledge-intensive and conversational benchmarks meeting or exceeding that of datasets like WizardLM and UltraChat. Specifically, the Llama-3-8B finetuned on GenQA performed exceptionally well on instruction-following benchmarks and mathematical reasoning tasks. For instance, on the MT-Bench, GenQA achieved an average score of 7.55, outperforming both WizardLM and UltraChat.
The detailed analysis revealed that GenQA’s generator prompts led to high diversity in the generated questions and answers. For example, the similarity scores of nearest neighbors were significantly lower for GenQA than static prompts, indicating a higher level of uniqueness. The dataset also included various splits, such as 4,210,076 questions in the academic domain and 515,509 math questions, showcasing its wide applicability.

In conclusion, with the introduction of GenQA by automating the dataset creation process, the researchers have demonstrated that generating large-scale, diverse datasets with minimal human intervention is possible. This approach reduces costs and bridges the gap between academic and industrial practices. The success of GenQA in finetuning a Llama-3 8B model underscores its potential to transform AI research and applications.
Check out the Paper and Dataset. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 45k+ ML SubReddit
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.
