Video generation has improved with models like Sora, which uses the Diffusion Transformer (DiT) architecture. While text-to-video (T2V) models have advanced, they often find it hard to create clear and consistent videos without extra references. Text-image-to-video (TI2V) models address this limitation by using an initial image frame as grounding to improve clarity. Reaching Sora-level performance is still difficult as it is hard to combine image-based inputs with the model effectively, and higher-quality datasets are needed to improve the model’s output, making it tough to achieve the same level of success as Sora.

Current methods explored integrating image conditions into U-Net architectures, but applying these techniques to DiT models remained unresolved. While diffusion-based approaches dominated text-to-video generation by using LDMs, scaling models, and shifting to transformer-based architectures, many studies focused on isolated aspects, overlooking their combined impact on performance. Techniques like cross-attention in PixArt-α, self-attention in SD3, and stability tricks such as QK–norm showed some improvements but became less effective as models scaled. Despite advancements, no unified model successfully combined T2V and TI2V capabilities, limiting progress toward more efficient and versatile video generation.
To solve this, researchers from Apple and the University of California developed a comprehensive framework that systematically examined the interaction between model architectures, training methods, and data curation strategies. The resulting STIV method is a simple and scalable text-image-conditioned video generation approach. Using frame replacement, it incorporates image conditions into a Diffusion Transformer (DiT) and applies text conditioning through a joint image-text conditional classifier-free guidance. This design enables STIV to perform text-to-video (T2V) and text-image-to-video simultaneously (TI2V) tasks. Additionally, STIV can be easily expanded to applications like video prediction, frame interpolation, multi-view generation, and long video generation.

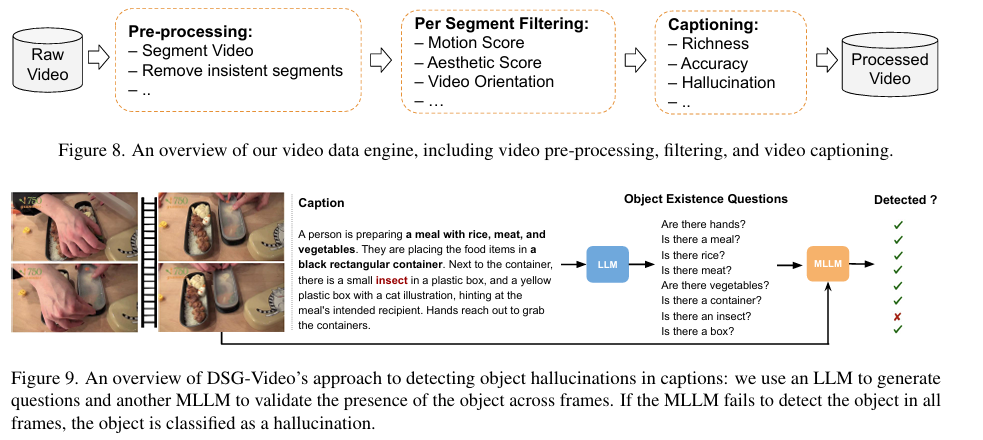
Researchers investigated the setup, training, and evaluation process for text-to-video (T2V) and text-to-image (T2I) models. The models used the AdaFactor optimizer, with a specific learning rate and gradient clipping, and were trained for 400k steps. Data preparation involved a video data engine that analyzed video frames, performed scene segmentation, and extracted features like motion and clarity scores—the training utilized curated datasets, including over 90 million high-quality video-caption pairs. Key evaluation metrics, including temporal quality, semantic alignment, and video-image alignment, were assessed using VBench, VBench-I2V, and MSRVTT. The study also explored ablation techniques, such as using different architectural designs and training strategies, including Flow Matching, CFG-Renormalization, and AdaFactor Optimizer. Experiments on model initialization showed that joint initialization from lower and higher resolution models improved performance. Additionally, using more frames during training enhanced metrics, particularly motion smoothness and dynamic range.
The T2V and STIV models significantly improved after scaling from 600M to 8.7B parameters. In T2V, the VBench-Semantic score increased from 72.5 to 74.8 with larger model sizes and improved to 77.0 when the resolution was raised from 256 to 512. Fine-tuning with high-quality data boosted the VBench-Quality score from 82.2 to 83.9, with the best model achieving a VBench-Semantic score of 79.5. Similarly, the STIV model showed advancements, with the STIV-M-512 model achieving a VBench-I2V score of 90.1. In video prediction, the STIV-V2V model outperformed T2V with an FVD score of 183.7 compared to 536.2. The STIV-TUP model delivered fantastic results in frame interpolation, with FID scores of 2.0 and 5.9 on MSRVTT and MovieGen datasets. In the multi-view generation, the proposed STIV model maintained the 3D coherency and achieved comparable performance to Zero123++ with Pa SNR of 21.64 and LPIPS of 0.156. In long video generation, it generated 380 frames, which showed its performance with potential for further progress.

In the end, the proposed framework provided a scalable and flexible solution for video generation by integrating text and image conditioning within a unified model. It demonstrated strong performance on public benchmarks and adaptability across various applications, including controllable video generation, video prediction, frame interpolation, long video generation, and multi-view generation. This approach highlighted its potential to support future advancements in video generation and contribute to the broader research community!
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.
Divyesh is a consulting intern at Marktechpost. He is pursuing a BTech in Agricultural and Food Engineering from the Indian Institute of Technology, Kharagpur. He is a Data Science and Machine learning enthusiast who wants to integrate these leading technologies into the agricultural domain and solve challenges.
