Traditional approaches to training language models heavily rely on supervised fine-tuning, where models learn by imitating correct responses. While effective for basic tasks, this method limits a model’s ability to develop deep reasoning skills. As artificial intelligence applications continue to evolve, there is a growing demand for models that can generate responses and critically evaluate their own outputs to ensure accuracy and logical consistency.
A serious limitation of traditional training methods is that they are based on imitation of responses and restrict models from critical analysis of responses. As a result, imitation-based techniques fail to present proper logical depth when dealing with intricate reasoning problems, and generated outputs often resemble correct-sounding responses. More importantly, increases in dataset sizes do not automatically lead to improved generated response quality, negatively impacting the training of large models. These challenges draw attention to a need for different methods that better improve reasoning rather than increase computations.
Existing solutions attempt to mitigate these issues using reinforcement learning and instruction tuning. Reinforcement learning with human feedback has shown promising results but requires large-scale computational resources. Another approach involves self-critique, where models assess their outputs for errors, but this often lacks consistency. Despite these advancements, most training techniques still focus on optimizing performance through sheer data volume rather than improving fundamental reasoning capabilities, which limits their effectiveness in complex problem-solving scenarios.
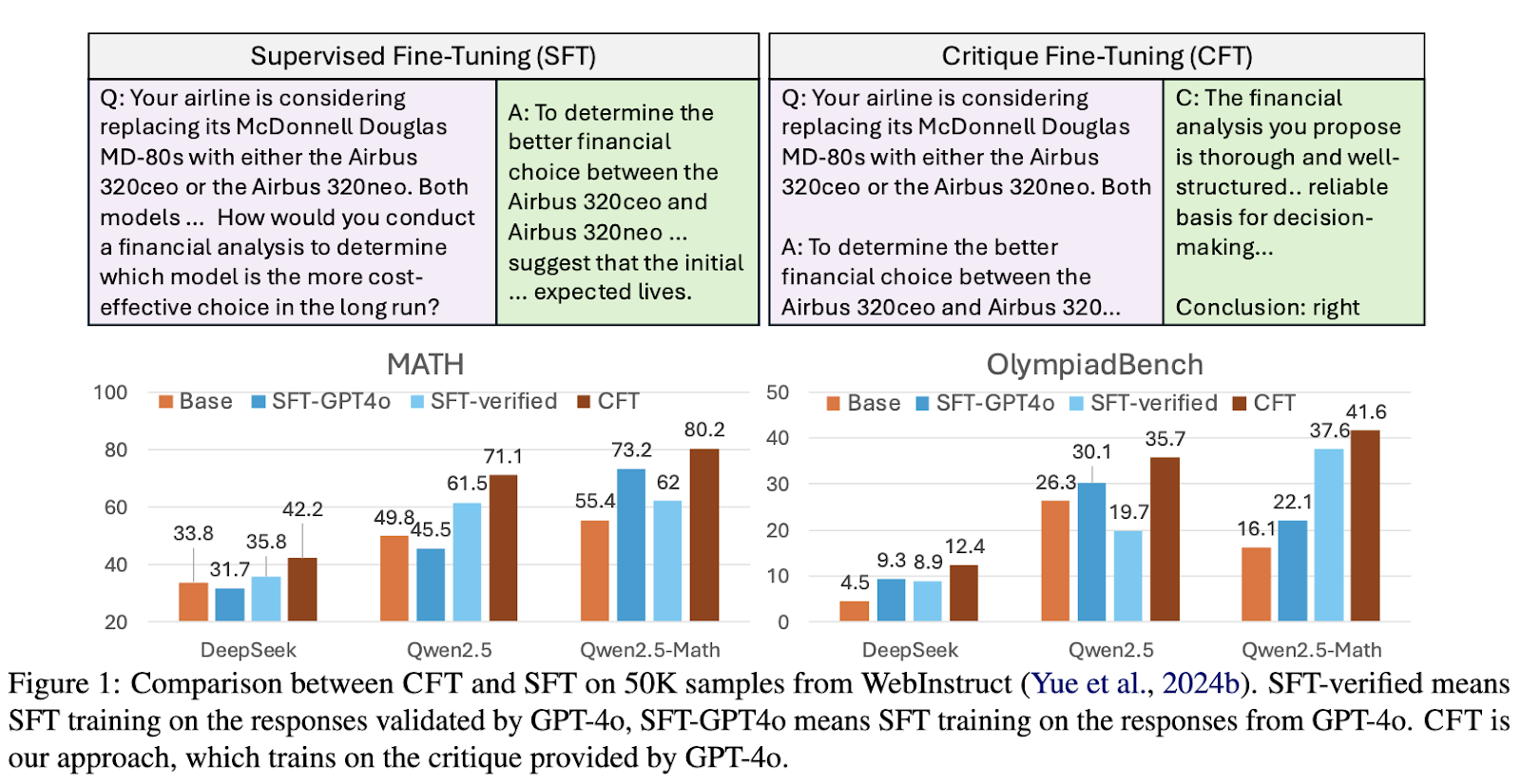
A research team from the University of Waterloo, Carnegie Mellon University, and the Vector Institute proposed Critique Fine-Tuning (CFT) as an alternative to conventional supervised fine-tuning. This approach shifts the focus from imitation-based learning to critique-based learning, where models are trained to assess and refine responses rather than replicate them. To achieve this, researchers constructed a dataset of 50,000 critique samples using GPT-4o, enabling models to identify response flaws and suggest improvements. This method is particularly effective for domains requiring structured reasoning, such as mathematical problem-solving.
The CFT methodology revolves around training models using structured critique datasets instead of conventional question-response pairs. During training, models are presented with a query and an initial response, followed by a critique that evaluates the response’s accuracy and logical coherence. By optimizing the model to generate critiques, researchers encourage a deeper analytical process that enhances reasoning capabilities. Unlike traditional fine-tuning, where models are rewarded for simply reproducing correct answers, CFT prioritizes identifying mistakes and suggesting improvements, leading to more reliable and explainable outputs.
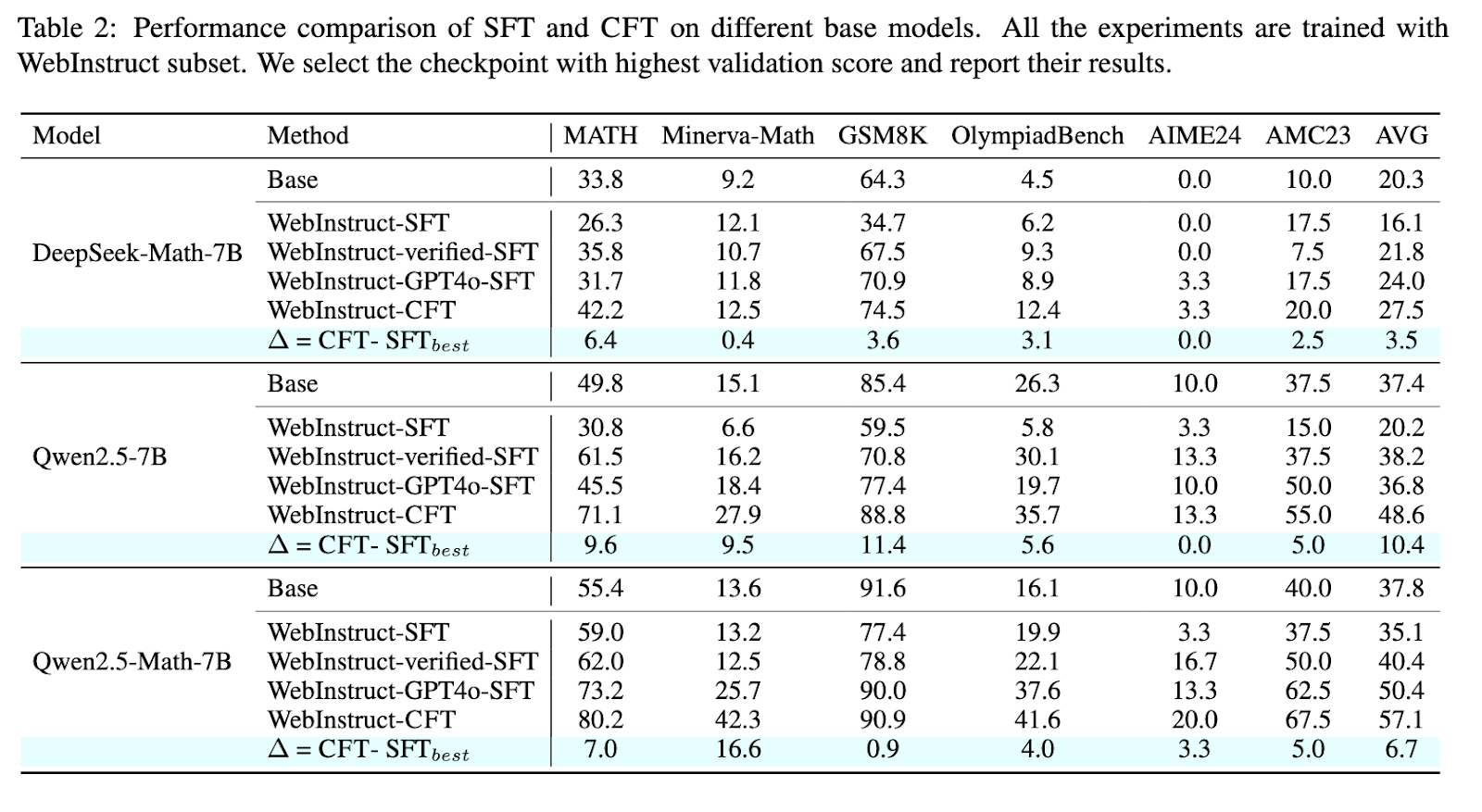
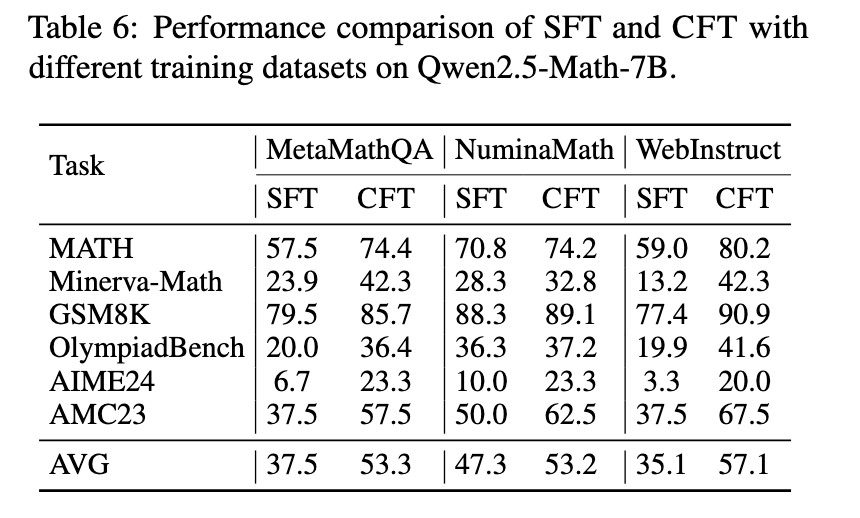
Experimental results demonstrate that CFT-trained models consistently outperform those trained using conventional methods. The researchers evaluated their approach across multiple mathematical reasoning benchmarks, including MATH, Minerva-Math, and OlympiadBench. Models trained using CFT showed a significant 4–10% performance improvement over their supervised fine-tuned counterparts. Specifically, Qwen2.5-Math-CFT, which was trained with as few as 50,000 examples, is comparable to and sometimes even superior to models competing against it with over 2 million samples in training. In addition, the framework yielded a 7.0% improvement in accuracy on the MATH benchmark and 16.6% on Minerva-Math compared to standard fine-tuning techniques. This significant improvement shows the efficiency of critique-based learning, which often promotes good results with significantly fewer training samples and computational resources.
The findings from this study emphasize the advantages of critique-based learning in language model training. By shifting from response imitation to critique generation, researchers have introduced a method that enhances model accuracy and fosters deeper reasoning skills. The ability to critically assess and refine responses rather than generate them allows models to handle complex reasoning tasks more effectively. This research offers a promising direction for improving artificial intelligence training methodologies while reducing computational costs. Future work could refine the approach by integrating additional critique mechanisms to enhance model reliability and generalization across diverse problem-solving domains.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 75k+ ML SubReddit.
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.
