In the latest release of published papers in Machine Intelligence Research, a team of researchers dives deep into the area of vision-language pretraining (VLP) and its applications in multi-modal tasks. The paper explores the idea of uni-modal training and how it differs from multi-modal adaptations. Then the report demonstrates the five important areas of VLP: feature extraction, model architecture, pretraining objectives, pretraining datasets, and downstream tasks. The researchers then review the existing VLP models and how they adapt and emerge in the field on different fronts.
The field of AI has always tried to train the models in a way where they perceive, think, and understand the patterns and nuances as Humans do. Various attempts have been made to incorporate as many data input fields as possible, such as visual, audio, or textual data. But most of these approaches have tried to solve the problem of “understanding” in a uni-modal sense.
A uni-modal approach is an approach where you asses a situation undertaking only one aspect of it, such as in a video, you are only focusing on the audio of it or the transcript of it, while in a multi-modal approach, you try to target as many available features as you can and incorporate them into the model. E.g., while analyzing a video, you undertake the audio, the transcription, and the speaker’s facial expression to truly “understand” the context.
The multi-modal approach renders itself challenging because its resource intensive and also for the fact that the need for large amounts of labeled data to train capable models has been difficult. Pretraining models based on transformer structures have addressed this issue by leveraging self-supervised learning and additional tasks to learn universal representations from large-scale unlabeled data.
Pretraining models in a uni-modal fashion, starting with BERT in NLP, have shown remarkable effectiveness by fine-tuning with limited labeled data for downstream tasks. Researchers have explored the viability of vision-language pretraining (VLP) by extending the same design philosophy to the multi-modal field. VLP uses pretraining models on large-scale datasets to learn semantic correspondences between modalities.
The researchers review the advancements made in VLP approach across five major areas. Firstly, they discuss how VLP models preprocess and represent images, videos, and text to obtain corresponding features, highlighting various models employed. Secondly, they also explore and examine the perspective of single-stream and its usability versus dual-stream fusion and encoder-only versus encoder-decoder design.
The paper explores more about the pretraining of VLP models, categorizing them into completion, matching, and particular types. These objectives are important as they help to define universal vision-language representations. The researchers then provide an overview of the two main categories of pre-training the datasets, image-language models and video-language models. The paper emphasizes how the multi-modal approach helps to achieve a better understanding and accuracy in terms of understanding context and producing better-mapped content. Lastly, the article presents the goals and details of downstream tasks in VLP, emphasizing their significance in evaluating the effectiveness of pre-trained models.
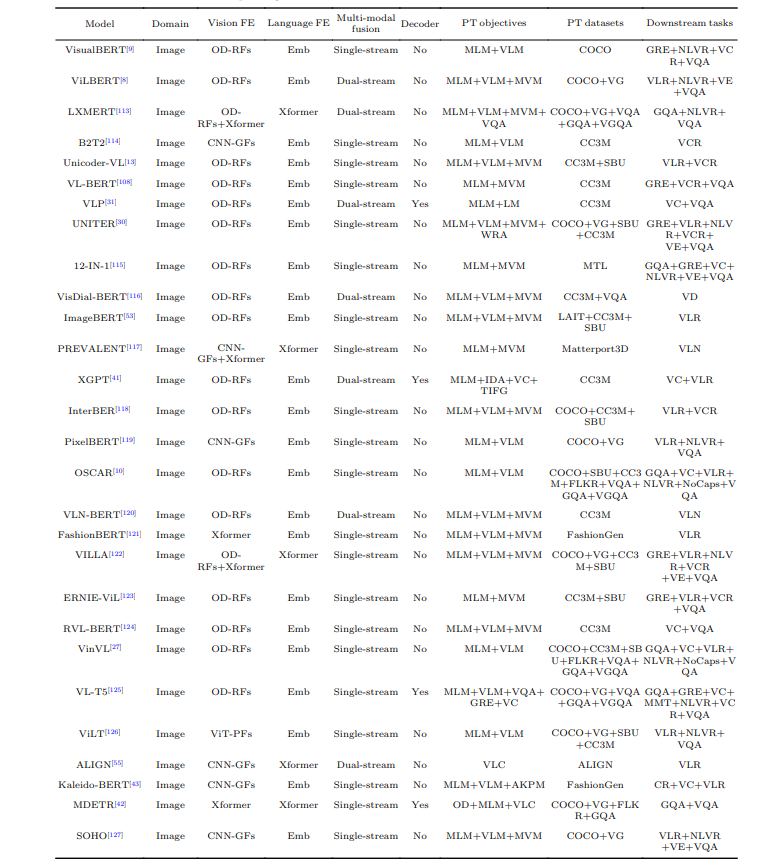
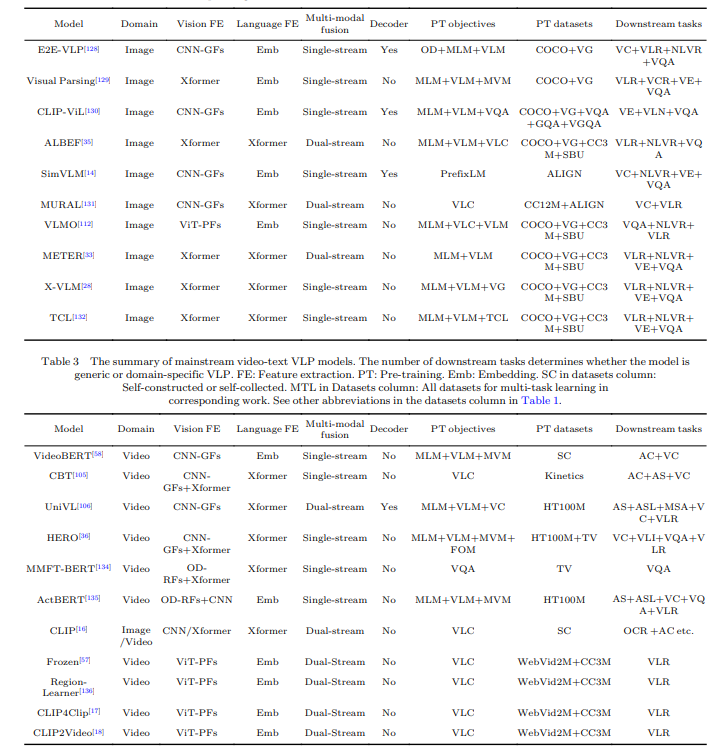
The paper provides a detailed overview of the SOTA VLP models. It lists those models and highlights their key features and performance. The models mentioned and covered are a solid foundation for cutting-edge technological advancement and can serve as a benchmark for future development.
Based on the research paper, The future of VLP architecture seems promising and dependable. They have proposed various areas of improvement, such as incorporating acoustic information, knowledgeable and cognitive learning, prompt tuning, model compression and acceleration, and out-of-domain pretraining. These areas of improvement are meant to inspire the new age of researchers to advance in the field of VLP and come out with breakthrough approaches.
Check Out The Paper and Reference Article. Don’t forget to join our 25k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
Featured Tools From AI Tools Club
🚀 Check Out 100’s AI Tools in AI Tools Club

Anant is a Computer science engineer currently working as a data scientist with experience in Finance and AI products as a service. He is keen to build AI-powered solutions that create better data points and solve daily life problems in an impactful and efficient way.
