
After the success of large language models (LLMs), the current research extends beyond text-based understanding to multimodal reasoning tasks. These tasks integrate vision and language, which is essential for artificial general intelligence (AGI). Cognitive benchmarks such as PuzzleVQA and AlgoPuzzleVQA evaluate AI’s ability to process abstract visual information and algorithmic reasoning. Even with advancements, LLMs struggle with multimodal reasoning, particularly pattern recognition and spatial problem-solving. High computational costs compound these challenges.
Prior evaluations relied on symbolic benchmarks such as ARC-AGI and visual assessments like Raven’s Progressive Matrices. However, these do not adequately challenge AI’s ability to process multimodal inputs. Recently, datasets like PuzzleVQA and AlgoPuzzleVQA have been introduced to assess abstract visual reasoning and algorithmic problem-solving. These datasets require models integrating visual perception, logical deduction, and structured reasoning. While previous models, such as GPT-4-Turbo and GPT-4o, demonstrated improvements, they still faced limitations in abstract reasoning and multimodal interpretation.


Researchers from the Singapore University of Technology and Design (SUTD) introduced a systematic evaluation of OpenAI’s GPT-[n] and o-[n] model series on multimodal puzzle-solving tasks. Their study examined how reasoning capabilities evolved across different model generations. The research aimed to identify gaps in AI’s perception, abstract reasoning, and problem-solving skills. The team compared the performance of models such as GPT-4-Turbo, GPT-4o, and o1 on PuzzleVQA and AlgoPuzzleVQA datasets, including abstract visual puzzles and algorithmic reasoning challenges.
The researchers conducted a structured evaluation using two primary datasets:
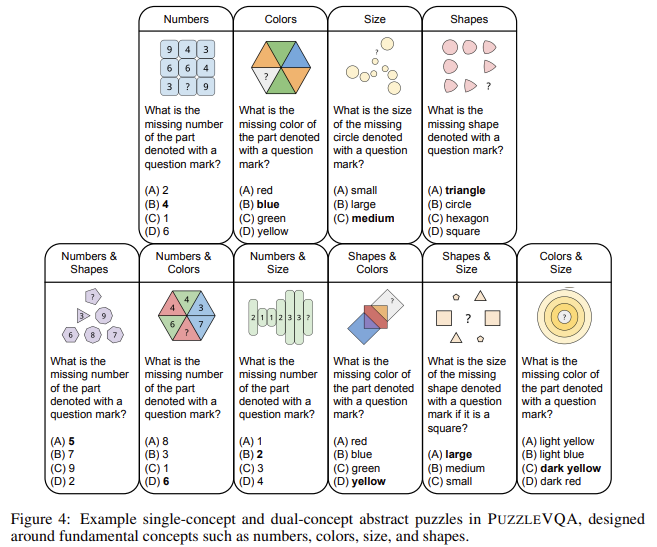
- PuzzleVQA: PuzzleVQA focuses on abstract visual reasoning and requires models to recognize patterns in numbers, shapes, colors, and sizes.
- AlgoPuzzleVQA: AlgoPuzzleVQA presents algorithmic problem-solving tasks that demand logical deduction and computational reasoning.
The evaluation was carried out using both multiple-choice and open-ended question formats. The study employed a zero-shot Chain of Thought (CoT) prompting for reasoning and analyzed the performance drop when switching from multiple-choice to open-ended responses. The models were also tested under conditions where visual perception and inductive reasoning were separately provided to diagnose specific weaknesses.

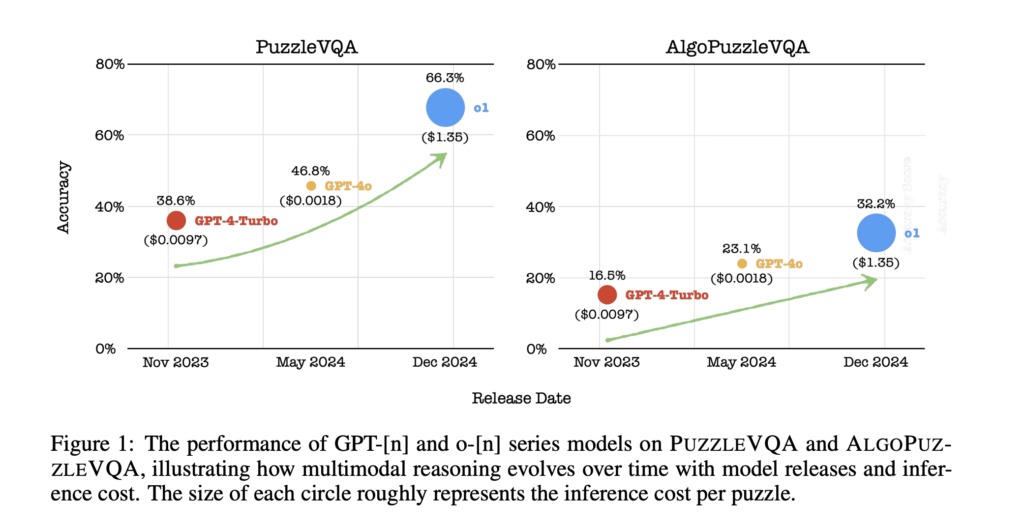
The study observed steady improvements in reasoning capabilities across different model generations. GPT-4o showed better performance than GPT-4-Turbo, while o1 achieved the most notable advancements, particularly in algorithmic reasoning tasks. However, these gains came with a sharp increase in computational cost. Despite overall progress, AI models still struggled with tasks that required precise visual interpretation, such as recognizing missing shapes or deciphering abstract patterns. While o1 performed well in numerical reasoning, it had difficulty handling shape-based puzzles. The difference in accuracy between multiple-choice and open-ended tasks indicated a strong dependence on answer prompts. Also, perception remained a major challenge across all models, with accuracy improving significantly when explicit visual details were provided.

In a quick recap, the work can be summarized in a few detailed points:
- The study observed a significant upward trend in reasoning capabilities from GPT-4-Turbo to GPT-4o and o1. While GPT-4o showed moderate gains, the transition to o1 resulted in notable improvements but came at a 750x increase in computational cost compared to GPT-4o.
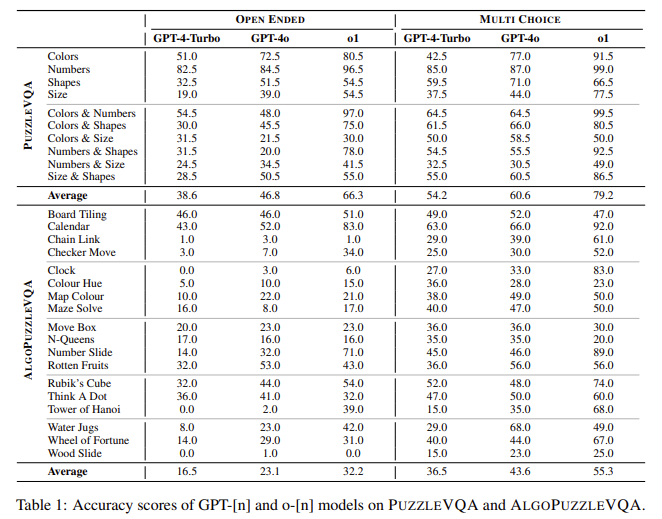
- Across PuzzleVQA, o1 achieved an average accuracy of 79.2% in multiple-choice settings, surpassing GPT-4o’s 60.6% and GPT-4-Turbo’s 54.2%. However, in open-ended tasks, all models exhibited performance drops, with o1 scoring 66.3%, GPT-4o at 46.8%, and GPT-4-Turbo at 38.6%.
- In AlgoPuzzleVQA, o1 substantially improved over previous models, particularly in puzzles requiring numerical and spatial deduction. o1 scored 55.3%, compared to GPT-4o’s 43.6% and GPT-4-Turbo’s 36.5% in multiple-choice tasks. However, its accuracy declined by 23.1% in open-ended tasks.
- The study identified perception as the primary limitation across all models. Injecting explicit visual details improved accuracy by 22%–30%, indicating a reliance on external perception aids. Inductive reasoning guidance further boosted performance by 6%–19%, particularly in numerical and spatial pattern recognition.
- o1 excelled in numerical reasoning but struggled with shape-based puzzles, showing a 4.5% drop compared to GPT-4o in shape recognition tasks. Also, it performed well in structured problem-solving but faced challenges in open-ended scenarios requiring independent deduction.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 75k+ ML SubReddit.


Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.