Automatic speech recognition (ASR) has become a crucial area in artificial intelligence, focusing on the ability to transcribe spoken language into text. ASR technology is widely used in various applications such as virtual assistants, real-time transcription, and voice-activated systems. These systems are integral to how users interact with technology, providing hands-free operation and improving accessibility. As the demand for ASR grows, so does the need for models that can handle long speech sequences efficiently while maintaining high accuracy, especially in real-time or streaming scenarios.
One significant challenge with ASR systems is their ability to efficiently process long speech utterances, especially in devices with limited computing resources. ASR models’ complexity increases as the input speech’s length grows. For instance, many current ASR systems rely on self-attention mechanisms, like multi-head self-attention (MHSA), which capture global interactions between acoustic frames. While effective, these systems have quadratic time complexity, meaning that the time required to process speech grows with the length of the input. This becomes a critical bottleneck when implementing ASR on low-latency devices such as mobile phones or embedded systems, where speed and memory consumption are highly constrained.
Several methods have been proposed to reduce the computational load of ASR systems. MHSA, while widely used for its ability to capture fine-grained interactions, is inefficient for streaming applications due to its high computational & memory requirements. To address this, researchers have explored alternatives such as low-rank approximations, linearization, and sparsification of self-attention layers. Other innovations, like Squeezeformer and Emformer, aim to reduce sequence length during processing. However, these approaches only mitigate the impact of the quadratic time complexity without eliminating it, leading to marginal gains in efficiency.
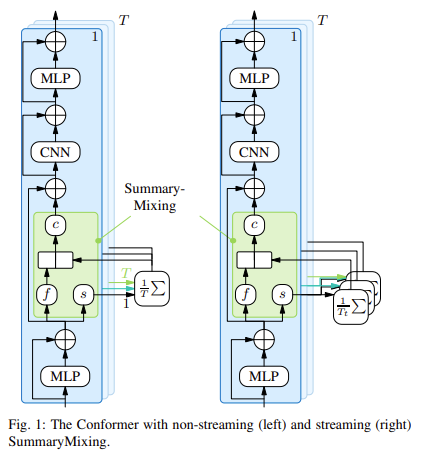
Researchers from the Samsung AI Center – Cambridge have introduced a novel method called SummaryMixing, which reduces the time complexity of ASR from quadratic to linear. This method, integrated into a conformer transducer architecture, enables more efficient speech recognition for streaming and non-streaming modes. The conformer-based transducer is a widely used model in ASR due to its ability to handle large sequences without sacrificing performance. SummaryMixing significantly enhances the conformer’s efficiency, particularly in real-time applications. The method replaces MHSA with a more efficient mechanism that summarizes the entire input sequence into a single vector, allowing the model to process speech faster and with less computational overhead.
The SummaryMixing approach involves transforming each frame of the input speech sequence using a local non-linear function while simultaneously summarizing the entire sequence into a single vector. This vector is then concatenated to each frame, preserving global relationships between frames while reducing computational complexity. This technique allows the system to maintain accuracy comparable to MHSA but at a fraction of the computational cost. For example, when evaluated on the Librispeech dataset, SummaryMixing outperformed MHSA by achieving a word error rate (WER) of 2.7% on the “dev-clean” set, compared to MHSA’s 2.9%. The method demonstrated even greater improvements in streaming scenarios, reducing the WER from 7.0% to 6.9% on longer utterances. Moreover, SummaryMixing requires significantly less memory, reducing peak VRAM usage by 16% to 19%, depending on the dataset.
The researchers conducted experiments to validate SummaryMixing’s efficiency further. On the Librispeech dataset, the system demonstrated a notable reduction in training time. Training with SummaryMixing required 15.5% fewer GPU hours than MHSA, resulting in faster model deployment. Regarding memory consumption, SummaryMixing reduced peak VRAM usage by 3.3 GB for long speech utterances, demonstrating its scalability for short and long sequences. The system’s performance was also tested on Voxpopuli, a more challenging dataset with diverse accents and recording conditions. Here, SummaryMixing achieved a WER of 14.1% in streaming scenarios, compared to 14.6% for MHSA, while using an infinite left-context, significantly improving accuracy for real-time ASR systems.
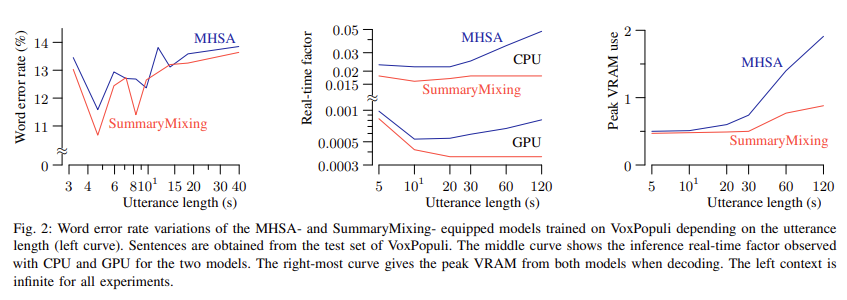
SummaryMixing’s scalability and efficiency make it an ideal solution for real-time ASR applications. The method’s linear time complexity ensures it can process long sequences without the exponential increase in computational costs associated with traditional self-attention mechanisms. In addition to improving WER and reducing memory usage, SummaryMixing’s ability to handle both streaming and non-streaming tasks with a unified model architecture simplifies the deployment of ASR systems across different use cases. Integrating dynamic chunk training and convolution further enhances the model’s ability to operate efficiently in real-time environments, making it a practical solution for modern ASR needs.

In conclusion, SummaryMixing represents a significant advancement in ASR technology by addressing the key challenges of processing efficiency, memory consumption, and accuracy. This method substantially improves self-attention mechanisms by reducing time complexity from quadratic to linear. The Librispeech and Voxpopuli datasets demonstrate that SummaryMixing outperforms traditional methods and scales well across various speech recognition tasks. The reduction in computational and memory requirements makes it suitable for deployment in resource-constrained environments, offering a promising solution for the future of ASR in real-time and offline applications.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
Aswin AK is a consulting intern at MarkTechPost. He is pursuing his Dual Degree at the Indian Institute of Technology, Kharagpur. He is passionate about data science and machine learning, bringing a strong academic background and hands-on experience in solving real-life cross-domain challenges.
