Natural language processing (NLP) drives researchers to develop algorithms that enable computers to understand, interpret, and generate human languages. These efforts cover various applications, such as machine translation, sentiment analysis, and intelligent conversational agents. The problem concerns the inefficiencies and limitations of tokenizers used in large language models (LLMs). Tokenizers, which break down text into subwords, require substantial computational resources and extensive training. Furthermore, they often result in large, inefficient vocabularies with many near-duplicate tokens. These inefficiencies are particularly problematic for underrepresented languages, where performance could be improved significantly.
Traditional methods like Byte Pair Encoding (BPE) and Unigram tokenizers create vocabularies based on statistical frequencies in a reference corpus. BPE merges frequent token pairs, while Unigram removes the least influential tokens iteratively. Both methods are computationally intensive and lead to large vocabularies, which could be more efficient and prone to containing many redundant tokens.
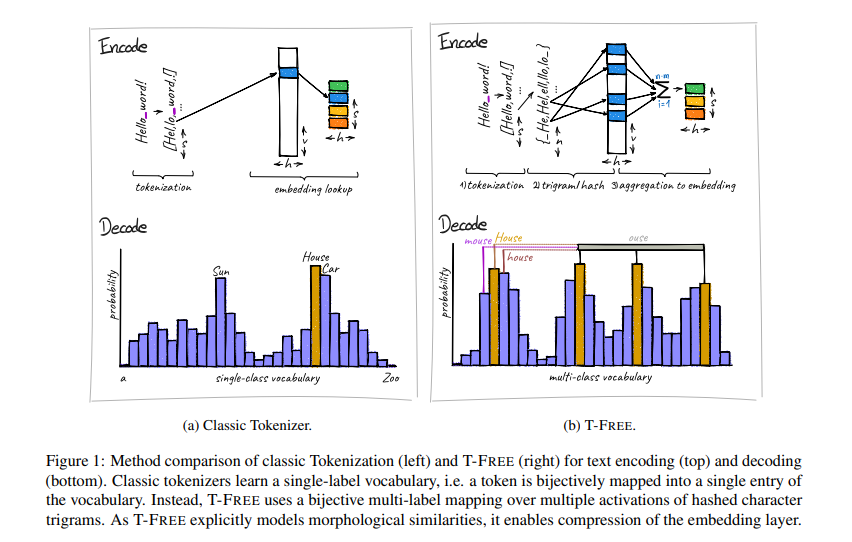
Researchers from Aleph Alpha, the Technical University of Darmstadt, the Hessian Center for Artificial Intelligence, and the German Center for Artificial Intelligence have introduced a novel approach called T-FREE. This tokenizer-free method embeds words directly through sparse activation patterns over character triplets, eliminating the need for traditional subword tokens. This new method significantly reduces the size of embedding layers and improves performance across languages.
T-FREE uses hashed character triplets to represent each word in the input text, capturing morphological similarities between words and allowing for efficient compression of the embedding layers. By modeling character overlaps, T-FREE maintains near-optimal performance across different languages without needing a pre-trained vocabulary. This approach addresses the inefficiencies and limitations of traditional tokenizers, offering a more streamlined and effective method for text encoding in LLMs.
The experimental evaluation of T-FREE demonstrated significant improvements over traditional tokenizers. Researchers achieved competitive downstream performance with a parameter reduction of more than 85% on text encoding layers. T-FREE also showed substantial improvements in cross-lingual transfer learning. T-FREE outperformed traditional tokenizers in benchmark tests, highlighting its effectiveness and efficiency in handling diverse languages and tasks. For instance, models using T-FREE achieved better results in German after only 20,000 additional training steps, nearly reaching the performance levels of English-trained models. In comparison, traditional tokenizers showed minimal improvement with the same amount of training.
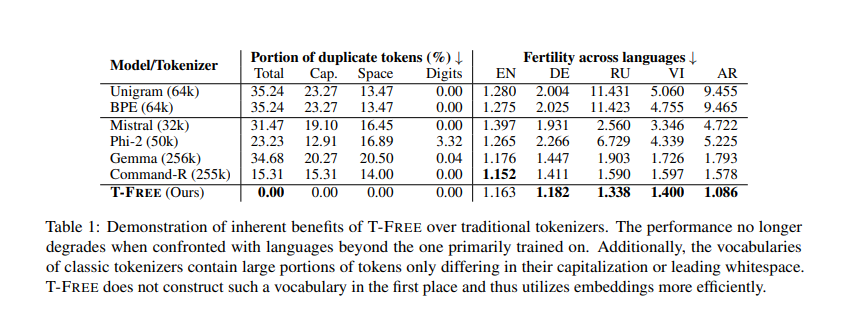
Detailed evaluations included hyperparameter ablations on 1 billion parameter models, revealing that T-FREE could achieve competitive scores with a significantly reduced vocabulary size. A vocabulary size of 8,000 entries was optimal, providing the best performance. In contrast, vocabulary sizes smaller than 2,000 resulted in significant performance drops. T-FREE’s design inherently eliminates duplicate tokens, further enhancing efficiency and performance. T-FREE reduced the number of parameters needed by 20%, using 2.77 billion parameters compared to 3.11 billion for traditional methods.
T-FREE’s robust hashing function for words and its ability to model word similarities contribute to more stable and efficient training dynamics. This approach also reduces the computational costs associated with pre-processing, training, and inference of LLMs. The design allows for explicit modeling and steering of the decoding process at inference time, potentially reducing hallucinations and enabling dynamic adjustments to the available dictionary.
In conclusion, T-FREE significantly advances text encoding for large language models. T-FREE addresses the major drawbacks of current tokenization approaches by eliminating the need for traditional tokenizers and introducing a memory-efficient method that leverages sparse representations. This new method offers a promising solution for more efficient and effective language modeling, particularly benefiting underrepresented languages and reducing the overall computational burden of LLMs.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.
