
Have you ever wondered how current AI systems, like those powering chatbots and language models, can comprehend and generate natural language so effectively? The answer lies in their ability to memorize and combine knowledge fragments, a process that has long eluded traditional machine learning techniques. This paper explores a novel approach called “Memory Mosaics,” which aims to shed light on this intricate process and potentially pave the way for more transparent and disentangled AI systems.
While transformer-based models have undoubtedly revolutionized natural language processing, their inner workings remain largely opaque, akin to a black box. Researchers have long sought methods to disentangle and understand how these models process and combine information. Memory Mosaics, a learning system architecture with multiple associative memories working collectively to perform prediction tasks, offers a promising solution.
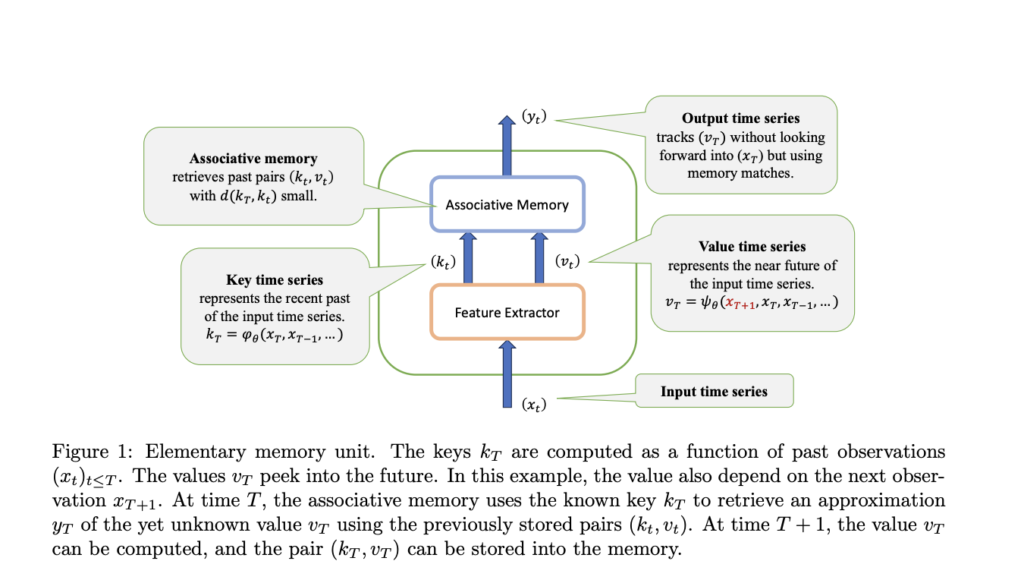
Associative memories, the core components of Memory Mosaics, store and retrieve key-value pairs. Here’s how they work:
- Formally, associative memory is a device that stores key-value pairs (k1, v1), (k2, v2), …, (kn, vn), where keys and values are vectors in Rd.
- Given a query key k, the retrieval process estimates the conditional probability distribution P(V|K) based on the stored pairs and returns the conditional expectation E(V|K=k) as the predicted value.
- This conditional expectation can be computed using Gaussian kernel smoothing, drawing parallels to classical attention mechanisms.
- However, Memory Mosaics differ from transformers in notable ways, such as lacking position encoding, not distinguishing between keys and queries, and explicitly representing the prediction targets through value extraction functions.
During training, the key and value extraction functions are optimized, allowing each associative memory unit to specialize in memorizing relevant aspects of the input data efficiently.
The true power of Memory Mosaics lies in its ability to achieve “predictive disentanglement.” This process involves breaking down the overall prediction task into smaller, independent subtasks, which are then assigned to individual associative memory units.

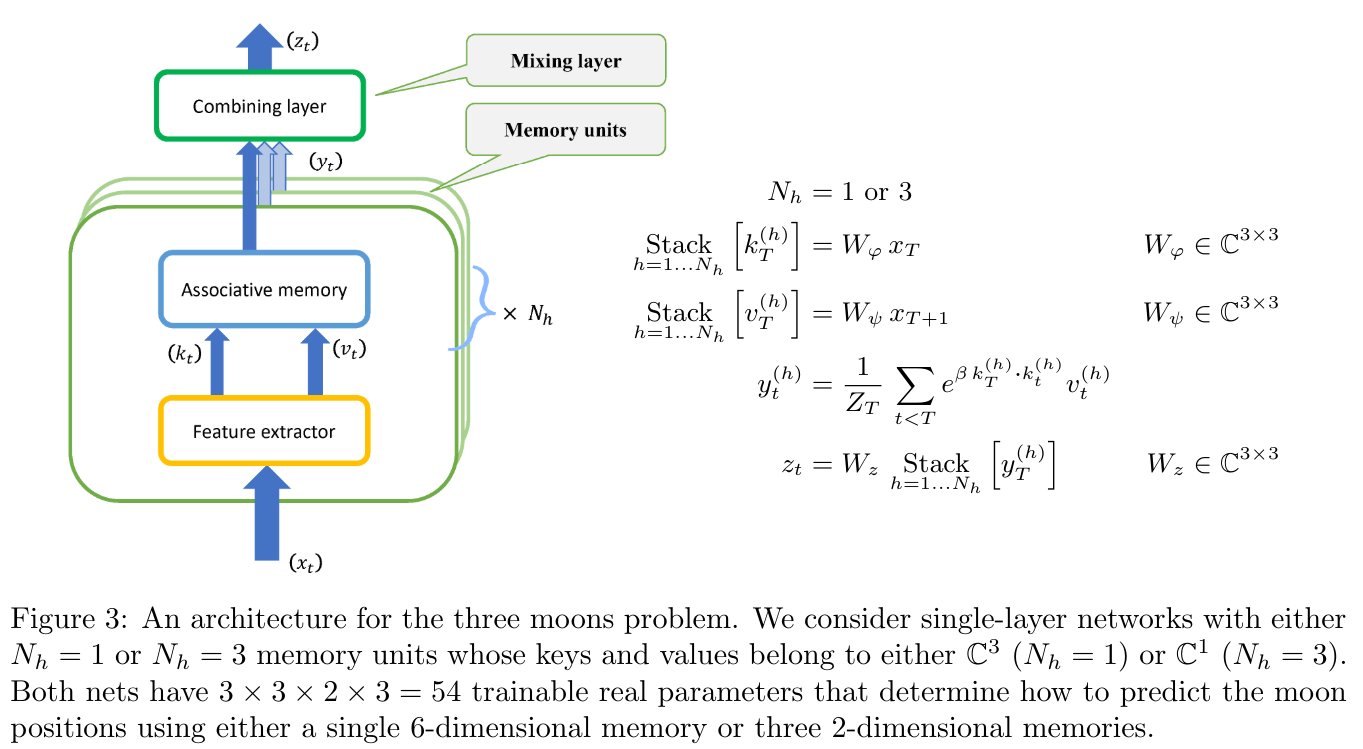
To illustrate this concept, consider the example used by the researchers: Imagine three moons orbiting a remote planet. While astronomers may not fully understand celestial mechanics, they can observe periodic motions and aim to predict future moon positions. One astronomer proposes compiling a single table containing the daily positions of all three moons, assuming that if the current configuration matches a previous observation, the future positions will follow the same pattern. Another astronomer suggests creating three separate tables, one for each moon, arguing that the future position of each moon can be independently predicted based on its current position and past observations.
This analogy highlights the essence of predictive disentanglement. By allowing each memory unit to focus on a specific subtask (predicting the position of a single moon), the overall prediction problem becomes more efficiently solvable than memorizing all three moons’ combined positions simultaneously.
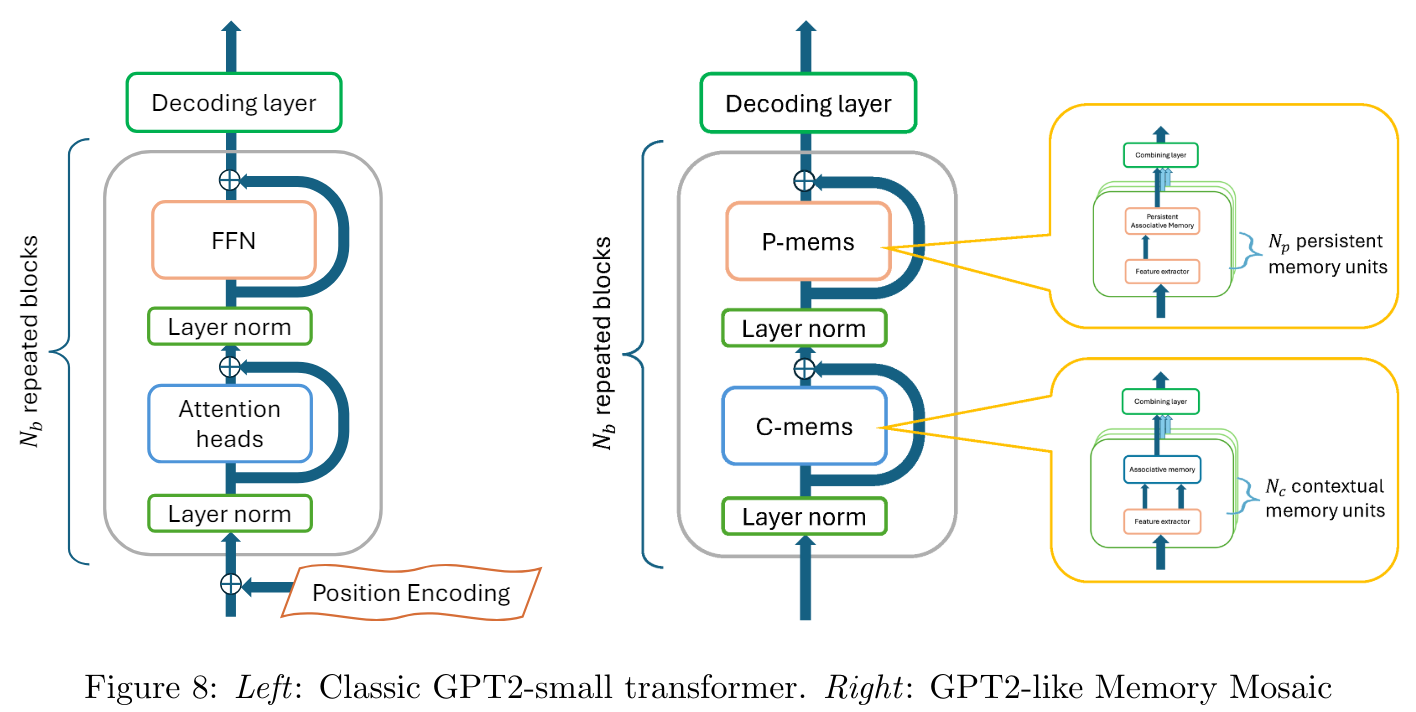
Building upon this principle, Memory Mosaics employs a hierarchical structure with layered memories. While some memory units operate at a contextual level, memorizing and predicting based on the immediate input sequence, others serve as persistent memories, retaining knowledge distilled from the training process itself.
This architecture, referred to as Memory Mosaics closely resembles transformers in its overall structure. However, it replaces the attention heads and feed-forward networks with contextual and persistent memory units (shown in Figure 8), respectively. The key and value extraction functions, along with the combination strategies, are learned during training, enabling the network to disentangle and reassemble knowledge fragments as needed.

The researchers rigorously evaluated Memory Mosaics’ performance, pitting it against traditional transformer architectures and other state-of-the-art models. The results are encouraging:
- On language modeling tasks, such as generating continuations for prompts designed to test factual, logical, and narrative consistency, Memory Mosaics performed comparably to or better than transformers.
- When tested on out-of-distribution data, like predicting text from Simple English Wikipedia articles, Memory Mosaics exhibited superior in-context learning abilities, outperforming transformers after observing enough context to identify the distribution shift.
- On the RegBench benchmark, which assesses a model’s ability to learn artificial languages defined by probabilistic finite automata, Memory Mosaics significantly outperformed transformers, recurrent neural networks, and state-space models across a wide range of training set sizes.
- Memory Mosaics’ attention patterns revealed a notably flat distribution, suggesting a more balanced consideration of contextual information compared to transformers’ tendency to fixate on specific positions or overlook distant tokens.
While further research is required to scale these findings to larger models, the implications are profound. Memory Mosaics offer a transparent and interpretable approach to compositional learning systems, shedding light on the intricate process of knowledge fragmentation and recombination that underpins language understanding and generation.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 42k+ ML SubReddit


Vineet Kumar is a consulting intern at MarktechPost. He is currently pursuing his BS from the Indian Institute of Technology(IIT), Kanpur. He is a Machine Learning enthusiast. He is passionate about research and the latest advancements in Deep Learning, Computer Vision, and related fields.