

In recent years, computer vision has made significant strides by leveraging advanced neural network architectures to tackle complex tasks such as image classification, object detection, and semantic segmentation. Transformative models like Transformers and Convolutional Neural Networks (CNNs) have become fundamental tools, driving substantial improvements in visual recognition performance. These advancements have paved the way for more efficient and accurate systems in various applications, from autonomous driving to medical imaging.
One of the crucial challenges in computer vision is the quadratic complexity of the attention mechanism used in transformers, which hinders their efficiency in handling long sequences. This issue is particularly critical in vision tasks where the sequence length, defined by the number of image patches, can significantly impact computational resources and processing time. Addressing this problem is crucial for improving the scalability and performance of vision models, especially when dealing with high-resolution images or videos that require extensive computational power.

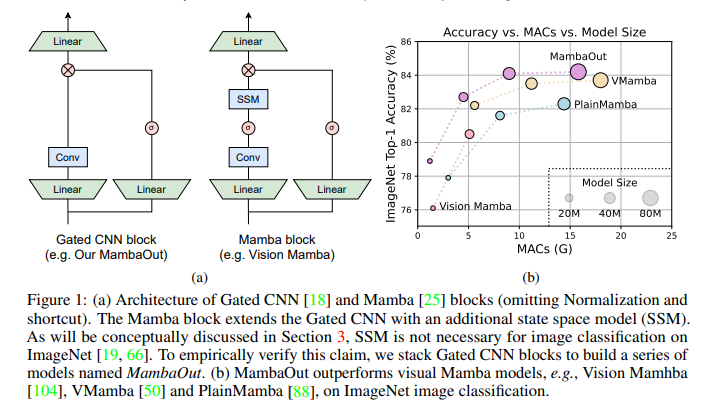
Existing research includes various token mixers with linear complexity, such as dynamic convolution, Linformer, Longformer, and Performer. Furthermore, RNN-like models such as RWKV and Mamba have been developed to handle long-sequence efficiently. Vision models incorporating Mamba include Vision Mamba, VMamba, LocalMamba, and PlainMamba. These models leverage structured state space models (SSM) for improved performance in visual recognition tasks, demonstrating their potential to address the quadratic complexity challenges posed by traditional attention mechanisms in transformers.
Researchers from the National University of Singapore have introduced MambaOut, an architecture derived from the Gated CNN block, designed to evaluate the necessity of Mamba for vision tasks. Unlike traditional Mamba models, MambaOut removes the state space model (SSM) component, focusing on simplifying the architecture while maintaining performance. This innovative approach seeks to determine whether the complexities introduced by Mamba are indeed necessary for achieving high performance in vision tasks, particularly in image classification on ImageNet.

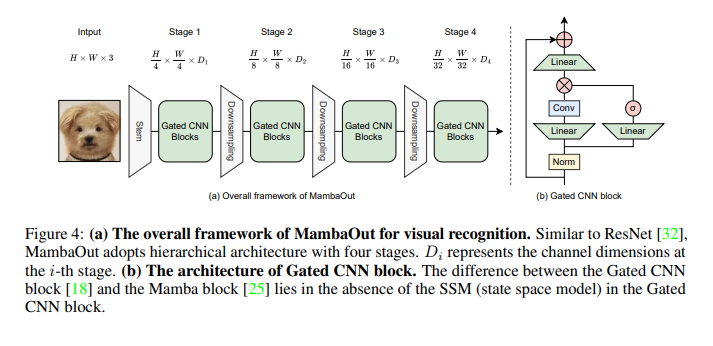
The MambaOut architecture utilizes Gated CNN blocks, integrating token mixing through depthwise convolution. This approach allows MambaOut to maintain a lower computational complexity than traditional Mamba models. By stacking these blocks, MambaOut constructs a hierarchical model, similar to ResNet, to handle various visual recognition tasks efficiently. The researchers implemented MambaOut with PyTorch and timm libraries, training the models on TPU v3 with a batch size of 4096 and an initial learning rate of 0.004. The training scheme followed DeiT without distillation, incorporating data augmentation techniques such as random resized crop, horizontal flip, and regularization techniques like weight decay and stochastic depth.
Empirical results indicate that MambaOut surpasses all visual Mamba models in ImageNet image classification. Specifically, MambaOut achieves a top-1 accuracy of 84.1%, outperforming LocalVMamba-S by 0.4% with only 79% of the MACs. For instance, the MambaOut-Small model achieves an accuracy of 84.1%, which is 0.4% higher than LocalVMamba-S, while requiring only 79% of the Multiply-Accumulate Operations (MACs). MambaOut is the backbone within Mask R-CNN, initialized with ImageNet pre-trained weights in object detection and instance segmentation on COCO. Despite MambaOut surpassing some visual Mamba models, it still lags behind state-of-the-art models like VMamba and LocalVMamba by 1.4 APb and 1.1 APm, respectively. This performance disparity highlights the benefits of integrating Mamba in long-sequence visual tasks, reinforcing the hypothesis that Mamba is more suitable for tasks with long-sequence characteristics.

In conclusion, the researchers demonstrated that while MambaOut effectively simplifies the architecture for image classification, the Mamba model’s strengths lie in handling long-sequence tasks like object detection and segmentation. This study underscores Mamba’s potential for specific visual tasks, guiding future research directions in optimizing vision models. The findings suggest that further exploration of Mamba’s application in long-sequence visual tasks is warranted, as it offers a promising avenue for enhancing the performance and efficiency of vision models.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 42k+ ML SubReddit


Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.