In machine learning, the focus is often on enhancing the performance of large language models (LLMs) while reducing the associated training costs. This endeavor frequently involves improving the quality of pretraining data, as the data’s quality directly impacts the efficiency and effectiveness of the training process. One prominent method to achieve this is data pruning, which involves selecting high-quality subsets from larger datasets to train the models more effectively. This process ensures that the models are kept from noisy and irrelevant data, streamlining the training process and improving overall model performance.
A challenge in training LLMs is the presence of vast and often noisy datasets. Poor-quality data can significantly degrade the performance of these models, making it crucial to develop methods to filter out low-quality data. The goal is to retain only the most relevant and high-quality information. Effective data pruning is essential to optimize the training of these models, ensuring that only the best data is used and enhancing the model’s accuracy and efficiency.
Traditional data pruning methods include simple rules-based filtering and basic classifiers to identify high-quality samples. While useful, these methods are often limited in handling large-scale and diverse datasets. Advanced techniques have emerged, utilizing neural network-based heuristics to assess data quality based on various metrics such as feature similarity or sample difficulty. Despite their advantages, these methods can be computationally expensive and may not perform consistently across different data domains, necessitating the development of more efficient and universally applicable techniques.
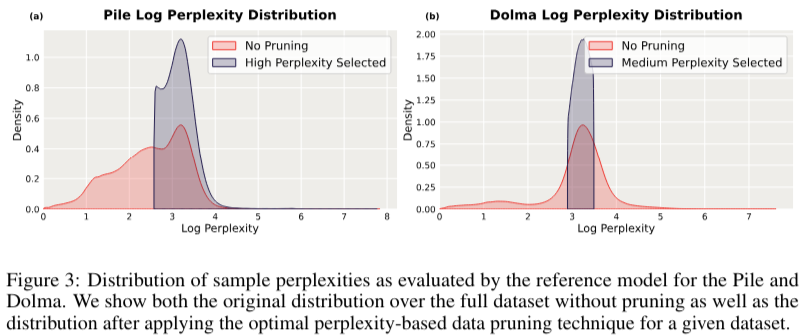
Researchers from Databricks, MIT, and DatologyAI have introduced an innovative approach to data pruning using small reference models to compute the perplexity of text samples. This approach begins with training a small model on a random subset of the data, which then evaluates the perplexity of each sample. Perplexity, in this context, measures how well a probability model predicts a sample. Lower perplexity scores indicate higher-quality data. By focusing on samples with the lowest perplexity scores, researchers can prune the dataset to retain only the most relevant data, thus improving the performance of the larger models trained on this pruned data.
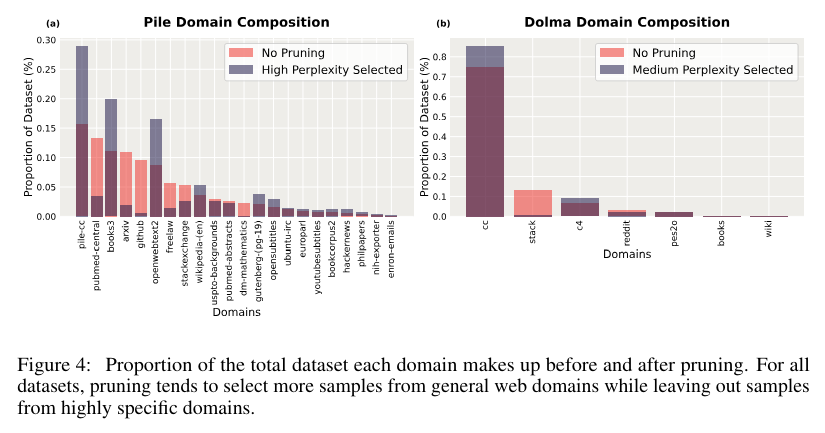
The proposed method involves splitting the dataset into training and validation sets for the small reference model. This model is trained on the standard next-token prediction objective, computing perplexity scores for each sample in the dataset. The dataset is then pruned based on these scores, selecting samples within a specific range of perplexities. For example, samples with the lowest perplexity are chosen using a low selection criterion. This pruned dataset is subsequently used to train the final, larger model, which benefits from the high-quality data. The effectiveness of this method is demonstrated across different dataset compositions, including the Pile, which is composed of diverse curated domains, and Dolma, a dataset derived mainly from web scrapes.
Perplexity-based data pruning significantly improves the performance of LLMs on downstream tasks. For instance, pruning based on perplexity scores computed with a 125 million parameter model improved the average performance on downstream functions of a 3 billion parameter model by up to 2.04%. Moreover, it achieved up to a 1.45 times reduction in pretraining steps required to reach comparable baseline performance. The method also proved effective in various scenarios, including over-trained and data-constrained regimes. In over-training scenarios, the absolute gain in average downstream normalized accuracy was similar for both compute optimal and over-trained models, demonstrating the method’s robustness.
This research underscores the utility of small reference models in perplexity-based data pruning, offering a significant step forward in optimizing LLM training. Researchers can improve model performance and training efficiency by leveraging smaller models to filter out low-quality data. This method presents a promising tool for data researchers, which showed a 1.89 improvement in downstream performance for the Pile and 1.51 for Dolma when training for a compute optimal duration. It enhances the performance of large-scale language models and reduces the computational resources required, making it a valuable addition to the modern data researcher’s toolkit.

In conclusion, the study presents a novel and effective method for data pruning using small reference models to compute perplexity. This approach improves the performance & efficiency of large language models by ensuring high-quality pretraining data. The method’s robustness across different data compositions and training regimes highlights its potential as a primary technique for modern data research. By optimizing data quality, researchers can achieve better model performance with fewer resources, making perplexity-based data pruning a valuable technique for future advancements in machine learning.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 43k+ ML SubReddit | Also, check out our AI Events Platform
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.
