Computer vision models have made significant strides in solving individual tasks such as object detection, segmentation, and classification. Complex real-world applications such as autonomous vehicles, security and surveillance, and healthcare and medical Imaging require multiple vision tasks. However, each task has its own model architecture and requirements, making efficient management within a unified framework a significant challenge. Current approaches rely on training individual models, making it difficult to scale them to real-world applications that require a combination of those tasks. Researchers at the University of Oxford and Microsoft have devised a novel framework, Olympus, which aims to simplify the handling of diverse vision tasks while enabling more complex workflows and efficient resource utilization.
Traditionally, the Computer vision approaches rely on task-specific Models. These models focus on accomplishing one task efficiently at a time. However, the requirement of separate models for each task increases the computational burden. Multitask learning models exist but often suffer from poor task balancing, resource inefficiency, and performance degradation on complex or underrepresented tasks. Therefore, there is a need for a new method that resolves the scalability issues, adapts to new scenarios dynamically, and effectively utilizes the resources.
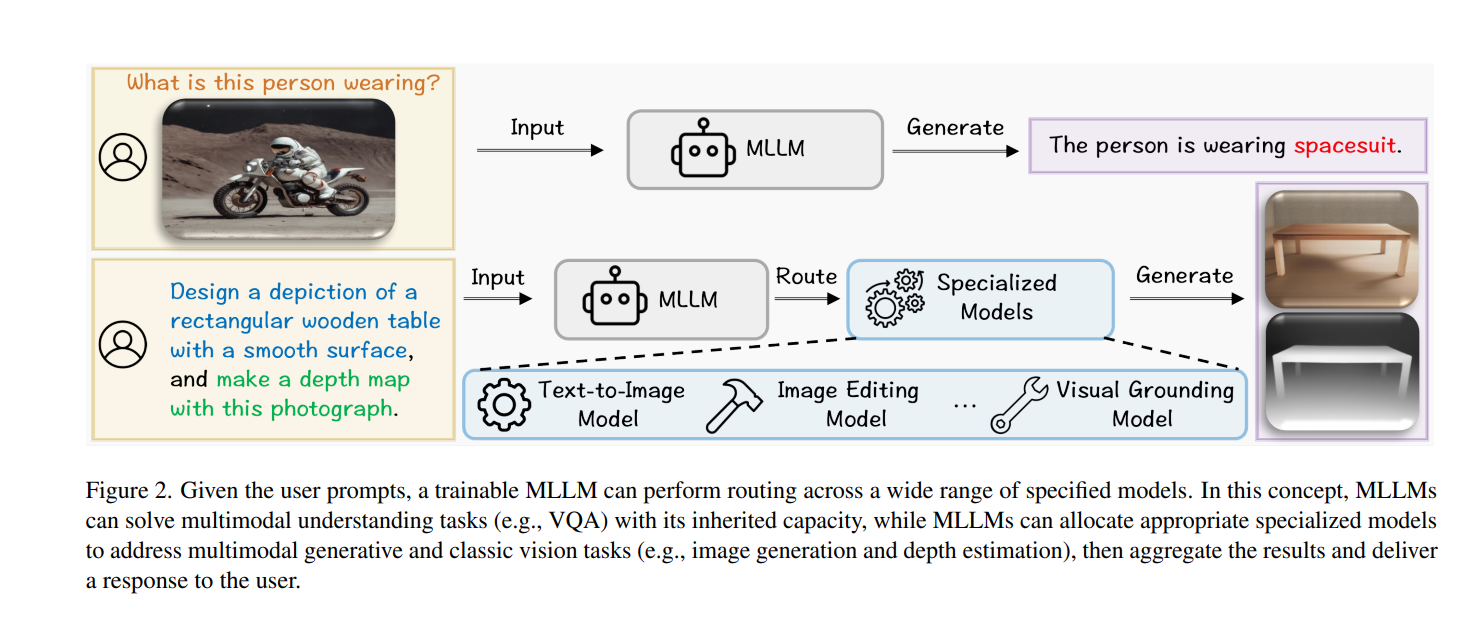
At its heart, the proposed framework, Olympus, has a controller, the Multimodal Large Language Model (MLLM), responsible for understanding user instructions and routing them to appropriate specialized modules. The key features of Olympus include:
- Task-Aware Routing: The controller MLLM analyses the incoming tasks and efficiently reroutes them to the most suitable specialized model to optimize the computational resources.
- Scalable Framework: It can handle up to 20 tasks simultaneously without requiring separate systems and integrate with the existing MLLMs efficiently.
- Knowledge Sharing: Different components of Olympus share whatever they have learned with each other, maximizing the output efficiency.
- Chain-of-Action Capability: Olympus can handle multiple vision tasks and is highly adaptable to complex real-world applications.
Olympus demonstrated impressive performance across various benchmarks. It achieved an average routing efficiency of 94.75% across 20 individual tasks and attained a precision of 91.82% in scenarios requiring multiple tasks to complete an instruction. The modular routing approach enabled the addition of new tasks with minimal retraining, showcasing its scalability and adaptability.
Olympus: A Universal Task Router for Computer Vision Tasks marks a significant leap in computer vision. Its innovative task-aware routing mechanism and modular knowledge-sharing framework address inefficiency and scalability challenges in multitask learning systems. By achieving impressive routing accuracy, precision in chained action scenarios, and scalability across diverse vision tasks, Olympus establishes itself as a versatile and efficient tool for various applications. While further exploration of edge-case tasks, latency trade-offs, and real-world validation is needed, Olympus paves the way for more integrated and adaptable systems, challenging the traditional task-specific model paradigm. With further developments and implementations, Olympus can change how complex vision problems are handled in different domains. This shall offer a solid base for future computer vision and artificial intelligence developments.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.

Afeerah Naseem is a consulting intern at Marktechpost. She is pursuing her B.tech from the Indian Institute of Technology(IIT), Kharagpur. She is passionate about Data Science and fascinated by the role of artificial intelligence in solving real-world problems. She loves discovering new technologies and exploring how they can make everyday tasks easier and more efficient.
