Artificial intelligence (AI) has significantly advanced with the development of large language models (LLMs) that follow user instructions. These models aim to provide accurate and relevant responses to human queries, often requiring fine-tuning to enhance their performance in various applications, such as customer service, information retrieval, and content generation. The ability to instruct these models precisely has become a cornerstone of modern AI, pushing the boundaries of what these systems can achieve in practical scenarios.
One of the challenges in developing and evaluating instruction-following models is the inherent length bias. This bias arises because human evaluators and training algorithms favor longer responses, leading to models that generate unnecessarily lengthy outputs. This preference complicates the assessment of model quality and effectiveness, as longer responses are only sometimes more informative or accurate. Consequently, the challenge is to develop models that understand instructions and ensure they can generate responses of appropriate length.
Current methods to address the length bias include incorporating length penalties into evaluation benchmarks. For instance, AlpacaEval and MT-Bench have integrated these penalties to counteract the models’ tendency to produce longer responses. Furthermore, various fine-tuning techniques, such as reinforcement learning with human feedback (RLHF), are employed to optimize models for better instruction-following capabilities. These methods aim to refine the models’ ability to generate concise yet comprehensive responses, balancing the length and quality of the output.
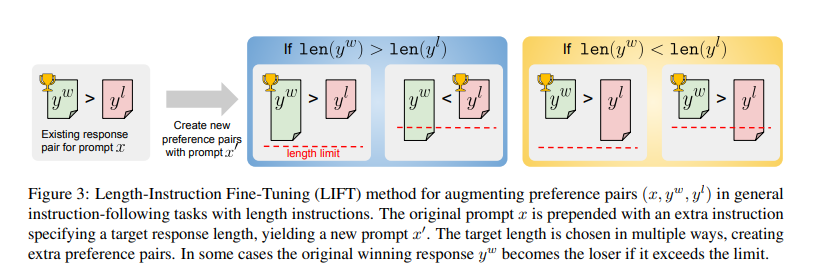
Researchers from Meta FAIR and New York University have introduced a novel approach called Length-Instruction Fine-Tuning (LIFT), which involves augmenting training data with explicit length instructions. This method enables models to be controlled at inference time to adhere to specified length constraints. The research team, including Meta FAIR and New York University members, designed this approach to mitigate the length bias and improve the models’ adherence to length-specific instructions. The models learn to respect these constraints during real-world applications by incorporating detailed instructions into the training data.
The LIFT method incorporates Direct Preference Optimization (DPO) to fine-tune models using datasets enhanced with length instructions. This process starts with augmenting a conventional instruction-following dataset by inserting length constraints into the prompts. The method constructs preference pairs that reflect both length constraints and response quality. These augmented datasets are then used to fine-tune models, such as Llama 2 and Llama 3, ensuring they can handle prompts with and without length instructions. This systematic approach allows the models to learn from various instructions, enhancing their ability to generate accurate and appropriately concise responses.
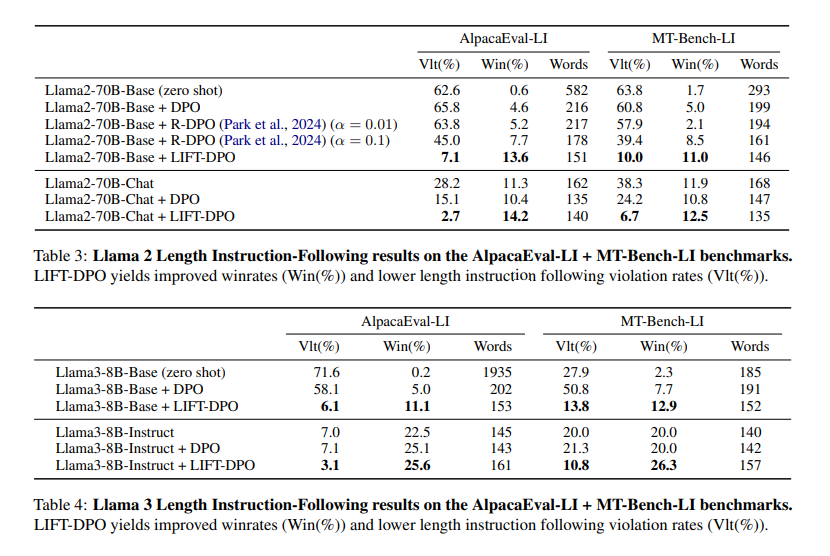
The proposed LIFT-DPO models demonstrated superior performance in adhering to length constraints compared to existing state-of-the-art models like GPT-4 and Llama 3. For example, the researchers found that the GPT-4 Turbo model violated length constraints almost 50% of the time, highlighting a significant flaw in its design. In contrast, the LIFT-DPO models exhibited significantly lower violation rates. Specifically, the Llama-2-70B-Base model, when subjected to standard DPO training, showed a violation rate of 65.8% on AlpacaEval-LI, which dramatically decreased to 7.1% with LIFT-DPO training. Similarly, the Llama-2-70B-Chat model’s violation rate reduced from 15.1% with standard DPO to 2.7% with LIFT-DPO, demonstrating the method’s effectiveness in controlling response length.
Moreover, the LIFT-DPO models maintained high response quality while adhering to length constraints. The win rates improved significantly, indicating that the models could generate high-quality responses within the specified length limits. For instance, the win rate for the Llama-2-70B-Base model increased from 4.6% with standard DPO to 13.6% with LIFT-DPO. These results underscore the method’s success in balancing length control and response quality, providing a robust solution for length-biased evaluations.
In conclusion, the research addresses the problem of length bias in instruction-following models by introducing the LIFT method. This approach enhances the controllability and quality of model responses by integrating length constraints into the training process. The results indicate that LIFT-DPO models outperform traditional methods, providing a more reliable and effective solution for length-constrained instruction following. The collaboration between Meta FAIR and New York University has significantly improved the development of AI models that can generate concise, high-quality responses, setting a new standard for instruction-following capabilities in AI research.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.
