Large language models (LLMs) are designed to understand and manage complex language tasks by capturing context and long-term dependencies. A critical factor for their performance is the ability to handle long-context inputs, which allows for a deeper understanding of content over extensive text sequences. However, this advantage comes with the drawback of increased memory usage, as storing and retrieving contextual information from previous inputs can consume substantial computational resources.
Memory consumption in LLMs is primarily attributed to storing key-value (KV) pairs during autoregressive inference. In such a scenario, the model must repeatedly access these stored pairs for every new token it generates. As the sequence length increases, the memory requirements grow exponentially, making it impractical for deployment in many hardware environments. This problem is further exacerbated when LLMs are applied to long-context tasks, where the entire sequence must be preserved in memory for accurate predictions. Consequently, reducing the memory footprint of LLMs has become an urgent need for optimizing their performance in real-world applications.
Traditional approaches for managing memory usage in LLMs involve complex algorithms or fine-tuning techniques tailored to individual model architectures. These methods often include post-hoc compression of the KV cache by analyzing attention scores or introducing changes to the model itself. While effective, such strategies are limited by their complexity and the need for additional computational resources. Moreover, some of these approaches are incompatible with modern attention mechanisms like FlashAttention, which are designed to improve memory efficiency. Therefore, researchers have explored new effective and easily adaptable techniques for various LLMs.
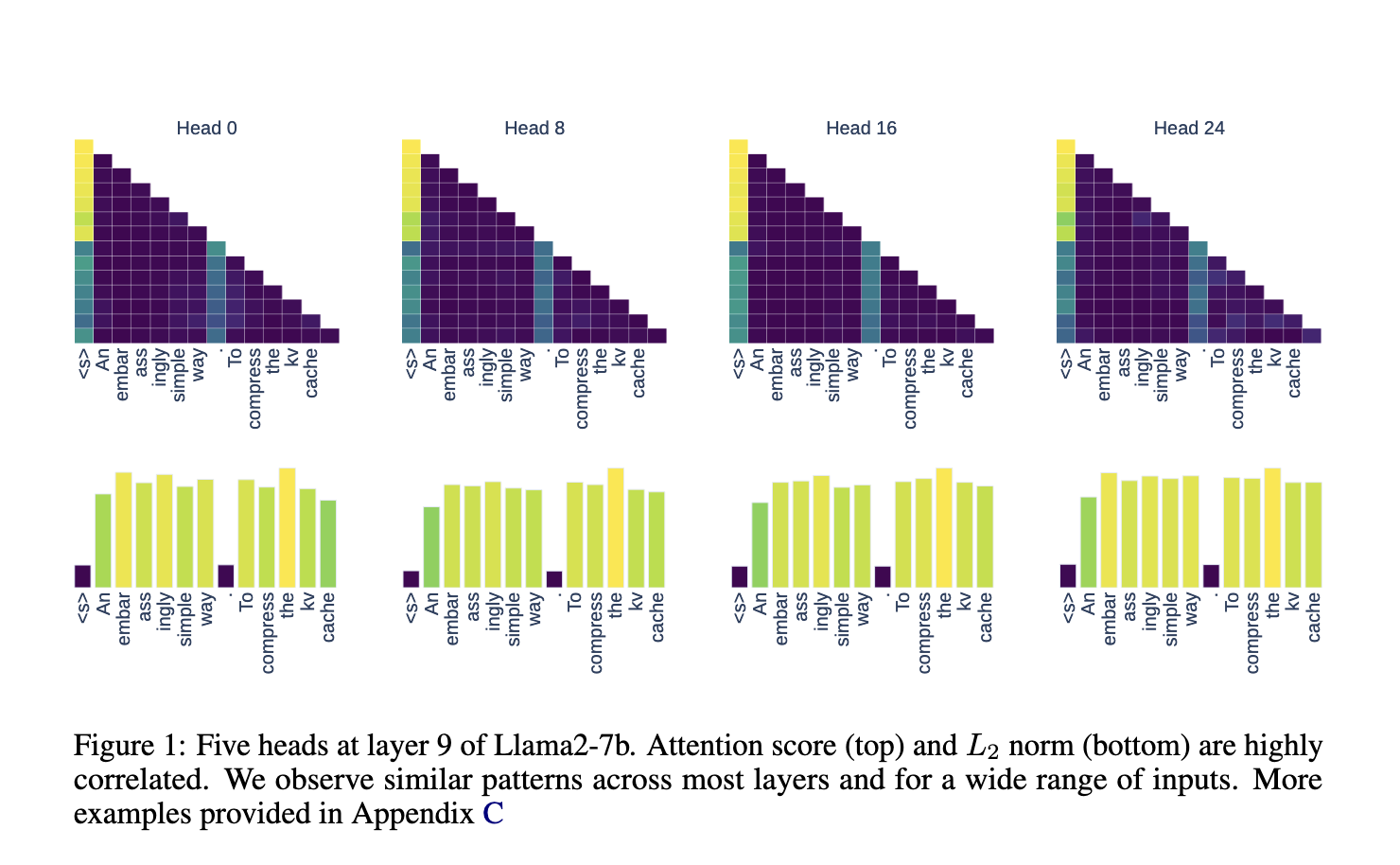
Researchers from the University of Edinburgh and Sapienza University of Rome proposed a novel approach for KV cache compression that is simpler and more efficient than existing solutions. This strategy leverages the correlation between the L2 norm of key embeddings and the corresponding attention scores, enabling the model to retain only the most impactful KV pairs. Unlike prior methods that require additional training or intricate modifications, this approach is non-intrusive and can be implemented directly on any transformer-based, decoder-only LLM. By keeping only the KV pairs with the lowest L2 norm, the researchers demonstrated that the model could reduce its memory footprint while maintaining high accuracy.
The methodology is rooted in the observation that key embeddings with lower L2 norm values are typically associated with higher attention scores during decoding. This implies that such embeddings are more influential in determining the model’s output. Therefore, retaining only these key embeddings and their corresponding values allows the model to compress its KV cache significantly without losing critical information. This strategy is particularly advantageous as it does not rely on calculating attention scores, making it compatible with various attention mechanisms, including FlashAttention. Moreover, it can be applied to any existing model without extensive retraining or architectural changes, broadening its applicability.
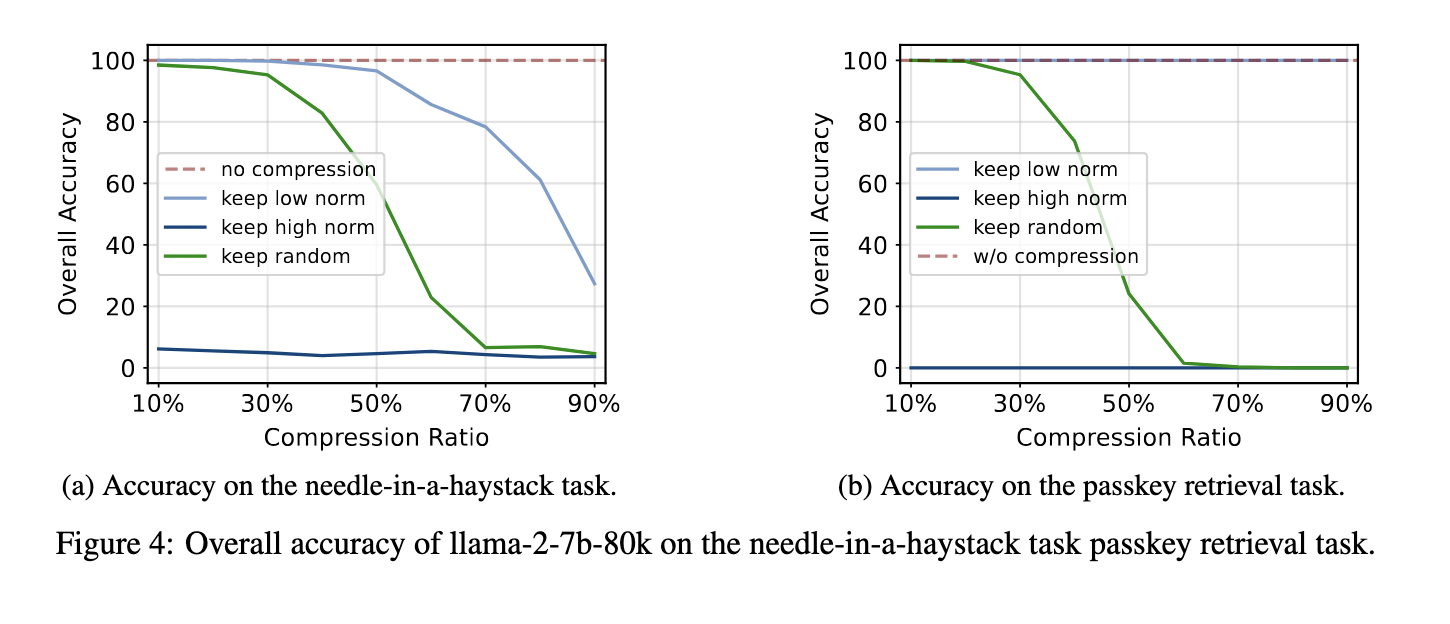
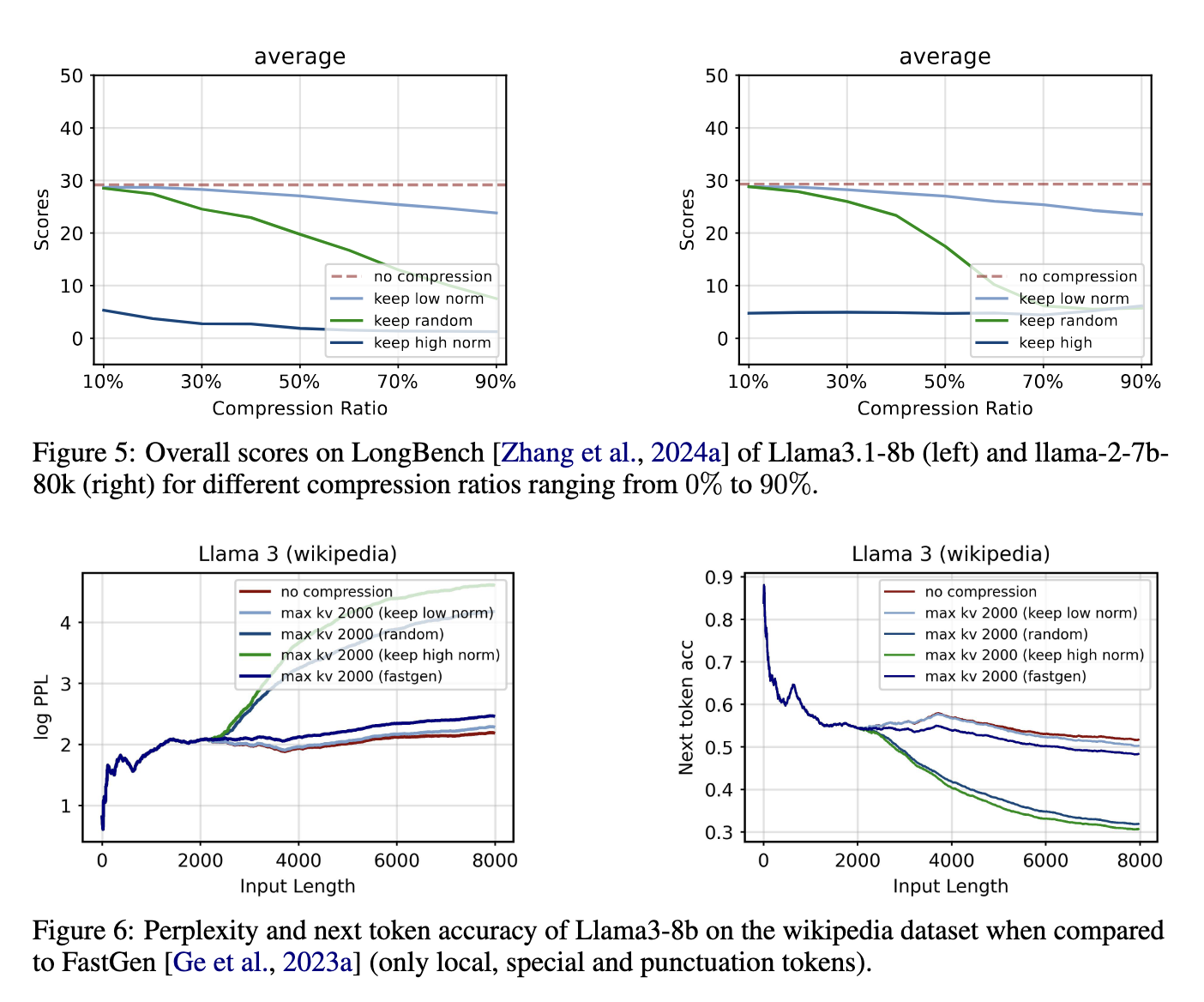
Regarding performance, the proposed method yields remarkable results across various tasks. Experimental evaluations showed that compressing the KV cache using the L2 norm strategy reduced memory usage by up to 50% in general language modeling tasks, with no significant impact on model perplexity or accuracy. For tasks that require retrieving specific information from long contexts, such as the passkey retrieval task, the model achieved 100% accuracy even when compressing 90% of the KV cache. These results highlight the effectiveness of the compression strategy in maintaining model performance while substantially reducing the memory requirements.
Furthermore, the method demonstrated robust performance on challenging long-context tasks like the needle-in-a-haystack test, where the model needs to identify and retrieve critical information from a large volume of data. In this scenario, the model maintained 99% accuracy when compressing 50% of the KV cache, a testament to the reliability of the compression strategy. Compared to existing methods like FastGen, which rely on attention scores for compression, the L2 norm-based strategy provides a simpler and more adaptable solution. The results also indicate that discarding KV pairs with high L2 norm values harms performance, as these pairs typically correspond to less informative embeddings.
In conclusion, the researchers from the University of Edinburgh and Sapienza University of Rome have presented an innovative solution to a longstanding problem in LLM deployment. Their L2 norm-based compression strategy offers a practical way to manage LLMs’ memory consumption without compromising performance. This approach is versatile, compatible with various model architectures, and easily implementable, making it a valuable contribution to LLMs. As LLMs evolve and handle increasingly complex tasks, such memory-efficient strategies will enable broader adoption across different industries and applications.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit.
We are inviting startups, companies, and research institutions who are working on small language models to participate in this upcoming ‘Small Language Models’ Magazine/Report by Marketchpost.com. This Magazine/Report will be released in late October/early November 2024. Click here to set up a call!
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.
