Vision-and-Language Navigation (VLN) combines visual perception with natural language understanding to guide agents through 3D environments. The goal is to enable agents to follow human-like instructions and navigate complex spaces effectively. Such advancements hold potential in robotics, augmented reality, and smart assistant technologies, where linguistic instructions guide interaction with physical spaces.
The core problem in VLN research is the lack of high-quality annotated datasets that pair navigation trajectories with precise natural language instructions. Annotating these datasets manually requires significant resources, expertise, and effort, making the process costly and time-intensive. Moreover, these annotations often fail to provide the linguistic richness and fidelity required for generalizing the models across diverse environments, limiting their effectiveness in real-world applications.
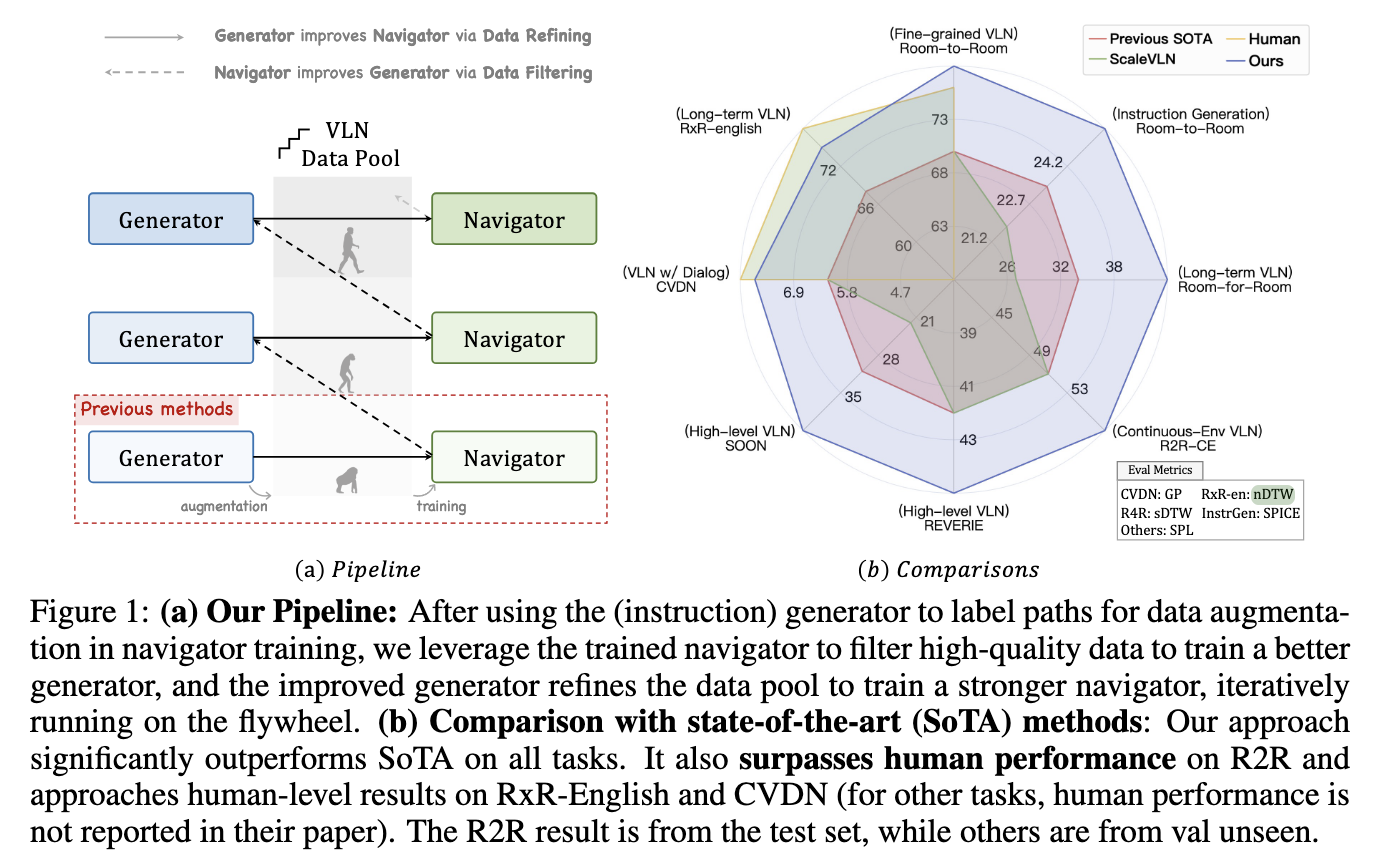
Existing solutions rely on synthetic data generation and environment augmentation. Synthetic data is generated using trajectory-to-instruction models, while simulators diversify the environments. However, these methods often must improve quality, producing poorly aligned data between language and navigation trajectories. This misalignment results in suboptimal agent performance. The problem is further compounded by metrics that inadequately evaluate instructions’ semantic and directional alignment with their corresponding trajectories, thereby challenging quality control.
Researchers from Shanghai AI Laboratory, UNC Chapel Hill, Adobe Research, and Nanjing University proposed the Self-Refining Data Flywheel (SRDF), a system designed to iteratively improve both the dataset and the models through mutual collaboration between an instruction generator and a navigator. This fully automated method eliminates the need for human-in-the-loop annotation. Starting with a small, high-quality human-annotated dataset, the SRDF system generates synthetic instructions and uses them to train a base navigator. The navigator then evaluates the fidelity of these instructions, filtering out low-quality data to train a better generator in subsequent iterations. This iterative refinement ensures continuous improvement in both the data quality and the models’ performance.
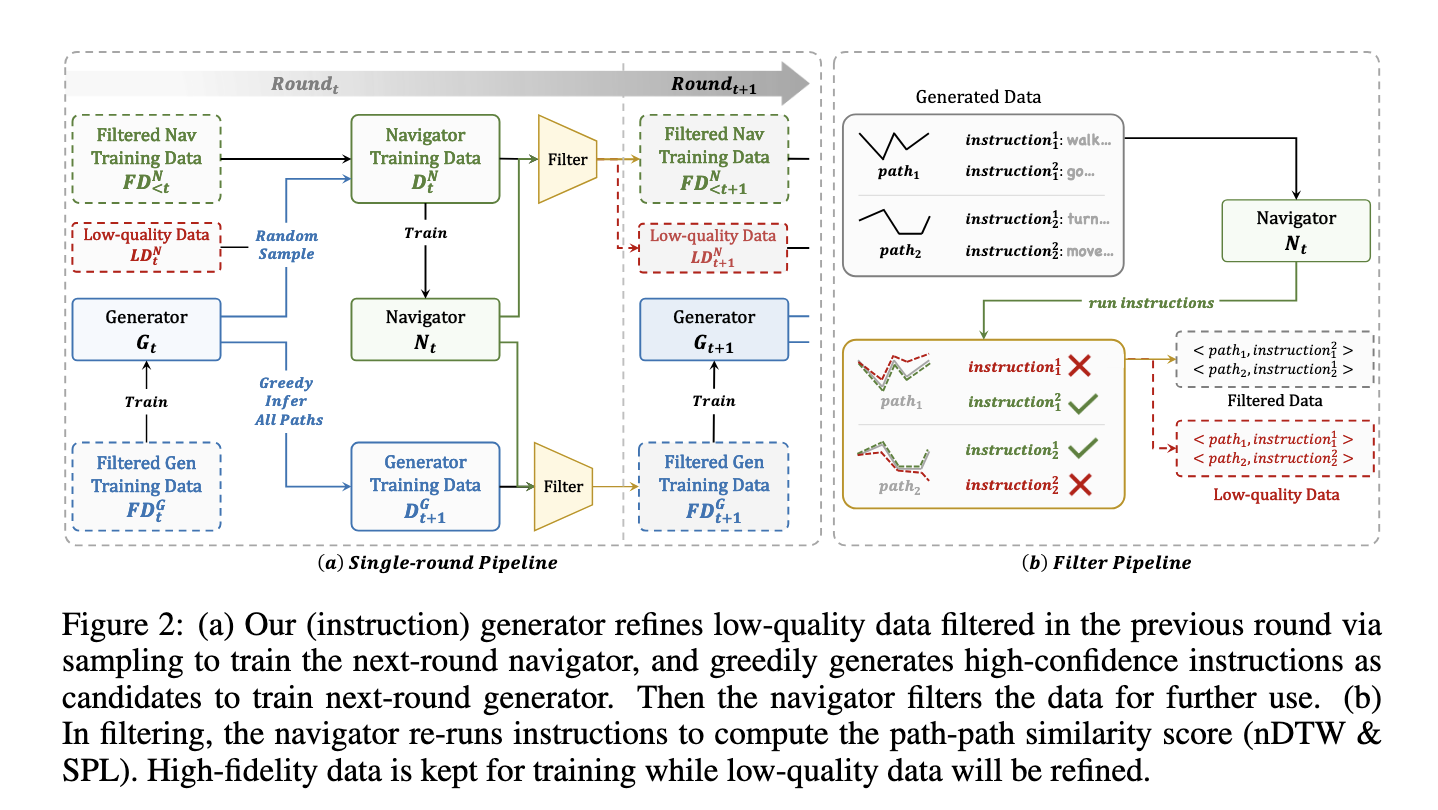
The SRDF system comprises two key components: an instruction generator and a navigator. The generator creates synthetic navigation instructions from trajectories using advanced multimodal language models. The navigator, in turn, evaluates these instructions by measuring how accurately it can follow the generated paths. High-quality data is identified based on strict fidelity metrics, such as the Success weighted by Path Length (SPL) and normalized Dynamic Time Warping (nDTW). Poor-quality data is either regenerated or excluded, ensuring that only reliable and highly aligned data is used for training. Over three iterations, the system refines the dataset, which ultimately contains 20 million high-fidelity instruction-trajectory pairs spanning 860 diverse environments.
The SRDF system demonstrated exceptional performance improvements across various metrics and benchmarks. On the Room-to-Room (R2R) dataset, the SPL metric for the navigator rose from 70% to an unprecedented 78%, surpassing the human benchmark of 76%. This marks the first instance where a VLN agent has outperformed human-level navigation accuracy. The instruction generator also achieved impressive results, with SPICE scores increasing from 23.5 to 26.2, surpassing all prior Vision-and-Language Navigation instruction generation methods. Further, the SRDF-generated data facilitated superior generalization across downstream tasks, including long-term navigation (R4R) and dialogue-based navigation (CVDN), achieving state-of-the-art performance across all tested datasets.
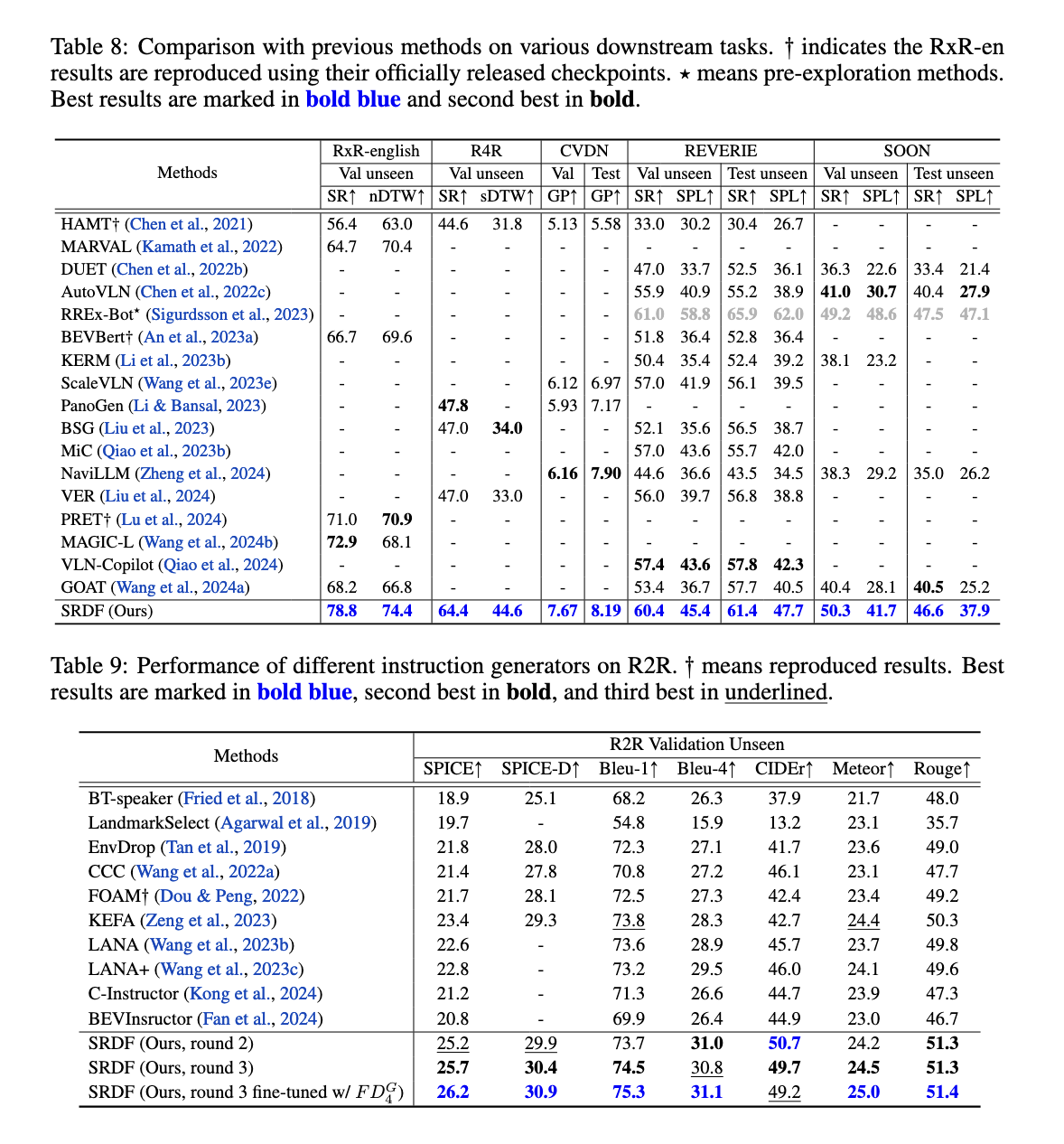
Specifically, the system excelled in long-horizon navigation, achieving a 16.6% improvement in Success Rate on the R4R dataset. The CVDN dataset significantly improved the Goal Progress metric, outperforming all prior models. Furthermore, the scalability of SRDF was evident as the instruction generator consistently improved with larger datasets and diverse environments, ensuring robust performance across varied tasks and benchmarks. The researchers also reported enhanced instruction diversity and richness, with over 10,000 unique words incorporated into the SRDF-generated dataset, addressing the vocabulary limitations of previous datasets.
The SRDF approach addresses the long-standing challenge of data scarcity in VLN by automating dataset refinement. The iterative collaboration between the navigator and the instruction generator ensures continuous enhancement of both components, leading to highly aligned, high-quality datasets. This breakthrough method has set a new standard in VLN research, showcasing the critical role of data quality and alignment in advancing embodied AI. With its ability to surpass human performance and generalize across diverse tasks, SRDF is poised to drive significant progress in developing intelligent navigation systems.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.
