
Prior work on abstention in large language models (LLMs) has made significant strides in query processing, answerability assessment, and handling misaligned queries. Researchers have explored methods to predict question ambiguity, detect malicious queries, and develop frameworks for query alteration. The BDDR framework and self-adversarial training pipelines have been introduced to analyze query changes and classify attacks. Evaluation benchmarks like SituatedQA and AmbigQA have been crucial in assessing LLM performance with unanswerable or ambiguous questions. These contributions have established a foundation for implementing effective abstention strategies in LLMs, enhancing their ability to handle uncertain or potentially harmful queries.
The University of Washington and Allen Institute for AI researchers have surveyed abstention in large language models, highlighting its potential to reduce hallucinations and enhance AI safety. They present a framework analyzing abstention from the query, model, and human value perspectives. The study reviews existing abstention methods, categorizes them by LLM development stages, and assesses various benchmarks and metrics. The authors identify future research areas, including exploring abstention as a meta-capability across tasks and customizing abstention abilities based on context. This comprehensive review aims to expand the impact and applicability of abstention methodologies in AI systems, ultimately improving their reliability and safety.
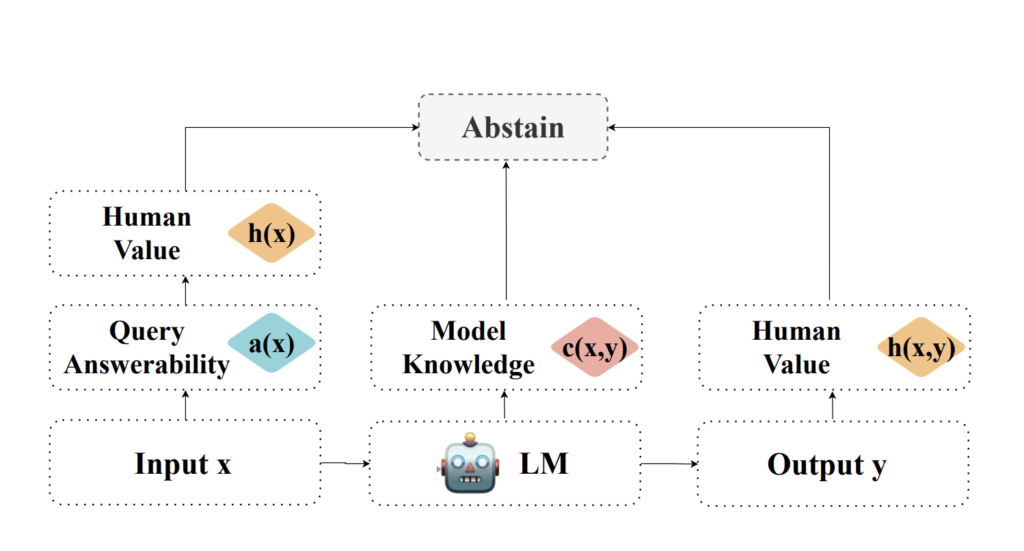
This paper explores the capabilities and challenges of large language models in natural language processing. While LLMs excel in tasks like question answering and summarization, they can produce problematic outputs such as hallucinations and harmful content. The authors propose incorporating abstention mechanisms to mitigate these issues, allowing LLMs to refuse answers when uncertain. They introduce a framework evaluating query answerability and alignment with human values, aiming to expand abstention strategies beyond current calibration techniques. The survey encourages new abstention methods across diverse tasks, enhancing AI interaction robustness and trustworthiness. It contributes an analysis framework, reviewing existing methods and discussing underexplored abstention aspects.

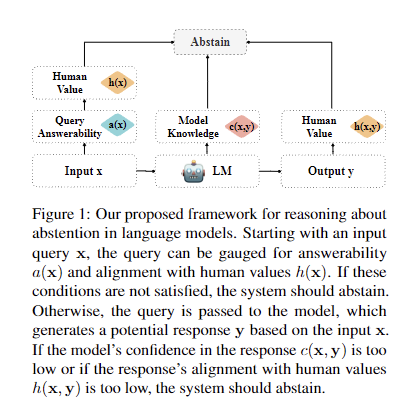
The paper’s methodology focuses on classifying and examining abstention strategies in large language models. It categorizes methods based on their application during pre-training, alignment, and inference stages. A novel framework evaluates queries from the query, model capability, and human value alignment perspectives. The study explores input-processing approaches to determine abstention, including ambiguity prediction and value misalignment detection. It incorporates calibration techniques while acknowledging their limitations. The methodology also outlines future research directions, such as privacy-enhanced designs and generalizing abstention beyond LLMs. The authors review existing benchmarks and evaluation metrics, identifying gaps to inform future research and improve abstention strategies’ effectiveness in enhancing LLM reliability and safety.


The study’s findings highlight the critical role of judicious abstention in bolstering the dependability and security of large language models.. It introduces a framework considering abstention from query, model, and human value perspectives, providing a comprehensive overview of current strategies. The study identifies gaps in existing methodologies, including limitations in evaluation metrics and benchmarks. Future research directions proposed include enhancing privacy protections, generalizing abstention beyond LLMs, and improving multilingual abstention. The authors encourage studying abstention as a meta-capability across tasks and advocate for more generalizable evaluation and customization of abstention capabilities. These findings underscore abstention’s significance in LLMs and outline a roadmap for future research to improve abstention strategies’ effectiveness and applicability in AI systems.
The paper concludes by highlighting several key aspects of abstention in large language models. It identifies under-explored research directions and advocates studying abstention as a meta-capability across various tasks. The authors emphasize the potential of abstention-aware designs to enhance privacy and copyright protections. They suggest generalizing abstention beyond LLMs to other AI domains and stress the need for improved multilingual abstention capabilities. The survey underscores strategic abstention’s importance in enhancing LLM reliability and safety, emphasizing the need for more adaptive and context-aware mechanisms. Overall, the paper outlines a roadmap for future research to improve abstention strategies’ effectiveness and ethical considerations in AI systems.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 47k+ ML SubReddit
Find Upcoming AI Webinars here


Shoaib Nazir is a consulting intern at MarktechPost and has completed his M.Tech dual degree from the Indian Institute of Technology (IIT), Kharagpur. With a strong passion for Data Science, he is particularly interested in the diverse applications of artificial intelligence across various domains. Shoaib is driven by a desire to explore the latest technological advancements and their practical implications in everyday life. His enthusiasm for innovation and real-world problem-solving fuels his continuous learning and contribution to the field of AI

